Back in April 2020 a Citizenlab reported on Zoom’s rather weak encryption and stated that Zoom uses the SILK codec for audio. Sadly, the article did not contain the raw data to validate that and let me look at it further. Thankfully Natalie Silvanovich from Googles Project Zero helped me out using the Frida tracing tool and provided a short dump of some raw SILK frames. Analysis of this inspired me to take a look at how WebRTC handles audio. In terms of perception, audio quality is much more critical for the perceived quality of a call as we tend to notice even small glitches. Mere ten seconds of this audio analysis were enough to set me off on quite an adventure investigating possible improvements to the audio quality provided by WebRTC.

I had looked at Zooms native client in 2017 (before the DataChannel post) and found that the audio packets were rather large sometimes compared to any WebRTC based solutions:

The graph above shows the number of packets with a certain UDP payload length. The packets with a length of 150 to 300 bytes are unusual compared to a typical WebRTC call. These are much longer than the packets we typically get from Opus. We suspected some kind of forward error correction (FEC) or redundancy back in the day but without access to the unencrypted frames it was hard to come up with more conclusions or action items.
The unencrypted SILK frames in the new dump showed a very similar distribution. After converting the frames to a file and then playing out the short message (thanks to Giacomo Vacca for a very helpful blog post describing the steps required) I went back to Wireshark and looked at the packets. Here is an example consisting of three packets that I found particularly interesting:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
packet 7: e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee 5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f packet 8: e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef 930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396 203453951f00065ec7d26a03420496f packet 9: e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc 854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef 930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396 203453951f00065ec7d26a03420496f e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee 5e6e68e6bcd73adbd59d3d31ea5fdda955cbaef |
Packet 9 contains the two previous packets, in full. Packet 8 contains the previous packet. Such redundancy is a feature, as a deep-dive into the SILK decoder (which can be either obtained from the internet draft submitted by the Skype team or from this GitHub repository) showed that this is SILKs LBRR – Low Bit-Rate Redundancy – format:

Zoom uses SKP_SILK_LBRR_VER1, but with up to two redundant packets. If every UDP packet contains not only the current audio frame but the two previous ones, this would be resilient even if you lost two out of three packets. So maybe the key to Zooms audio quality is Grandmother Skype’s secret recipe?
Opus FEC
How could we achieve the same with WebRTC? Looking at Opus FEC was the obvious next step.
LBRR, low bit-rate redundancy, from SILK is also contained in Opus (remember Opus is a hybrid codec that uses SILK for the lower end of the bitrate spectrum). However, Opus SILK is quite different from the original SILK that Skype open-sourced back in the day and so is the LBRR part that is used in forward error correction mode.
In Opus, forward error correction is not simply appended after the original audio frame but comes before it and is encoded in the bitstream. We experimented a bit with attempting to add our own forward error correction using the Insertable Streams API but that would have required a complete transcoding to insert the information into the bitstream before the actual packet.
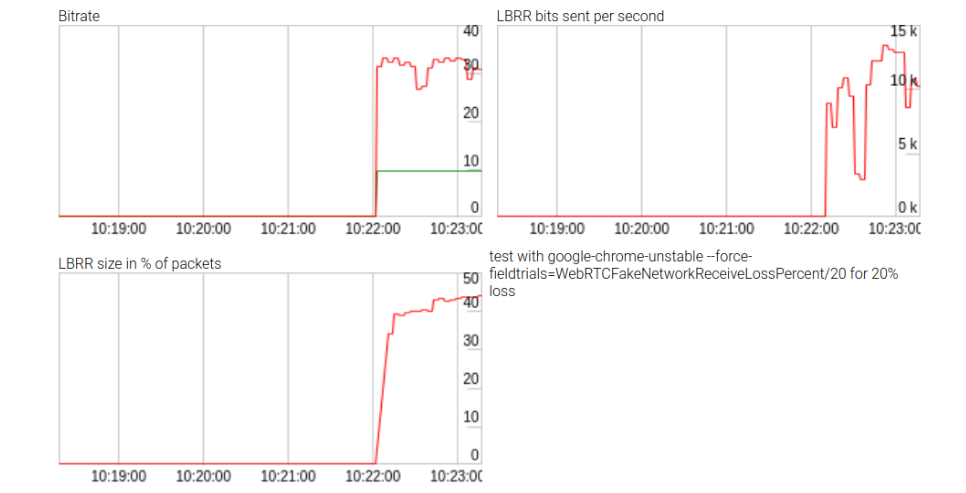
While not successful, the effort did allow gathering some statistics on the effect of LBRR shown above. LBRR uses bitrate of up to 10kbps (or two thirds of the data rate) under heavy packet loss. You can find the [repository here](https://github.com/fippo/opus-fec/). These statistics are not exposed by the WebRTC getStats() API and therefore these results were quite interesting.
In addition to the problem of having to re-encode, Opus FEC turns out to be configured in several unhelpful ways in WebRTC:
- It is enabled based on packet loss and we wanted to have the redundant information all the time, so it is there before any issues. The Slack folks wrote about this back in 2016. This means we can’t enable it by default and protect ourselves against random sporadic loss.
- The amount of forward error correction is capped to 25%. It will not be useful beyond that point.
- The bitrate for FEC is subtracted from the target max bitrate (see here).
Subtracting the FEC bitrate from the target max bitrate is quite unhelpful – FEC actively reduces the bitrate of the core stream. A lower bitrate stream generally leads to reduced quality. If there isn’t any packet loss for FEC to correct then this will only make quality worse instead of improving it. Why is it setup this way? The general theory is that one of the reasons for packet loss is congestion. If you have congestion, you don’t want to send more data because that that will only make the problem worse. However, as Emil Ivov describes in this great KrankyGeek talk from 2017, congestion isn’t always the reason for packet loss. In addition, this approach also ignores any accompanying video streams(s). The congestion-based FEC strategy for Opus audio doesn’t make much sense when you are sending hundreds of kilobits of video alongside a relatively minor 50kbps Opus’ stream. Maybe we will see some changes in libopus in the future. Until then it might be interesting to turn it off, it is enabled by default in WebRTC currently.
So that didn’t work…
And I see RED
If we want actual redundancy, RTP has a solution for that, called RTP Payload for Redundant Audio Data, or RED. It is fairly old, RFC 2198 was written in 1997. It allows putting multiple RTP payloads with different timestamps into the same RTP packet with relatively low overhead.
Using RED to put one or two redundant audio frames into each packet would give much more resilience to packet loss than Opus FEC. It comes at a cost however, doubling or tripling the audio bitrate from 30kbps to 60kbps or 90kbps (with an additional 10 kbps for the header). Compared to more than one megabit per second of video data it does not seem so bad however.
The webrtc library actually contained a second encoder and decoder for RED – now that is redundant! Despite some efforts to remove some unused audio-RED code, I managed to use that encoder with relatively little effort. The WebRTC issue tracker contains the full story.
This is now available under a field trial, enabled when running Chrome with the following flags:
|
1 |
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/ |
RED can then be enabled through SDP negotiation, it will show up as follows:
|
1 |
a=rtpmap:someid red/48000/2 |
It is not enabled by default as there are environments where consuming extra bandwidth is not a good idea. To use RED, change the order of codec such that it comes before the Opus codec. One way to do this is to use the RTCRtpTransceiver.setCodecPreferences API as shown in this change. SDP munging is the other alternative obviously. The SDP format might also provide a way to configure the maximum level of redundancy but the offer-answer semantics of RFC 2198 were not fully clear so I opted to leave it out for the time being.
Running it in the audio sample demonstrates the behaviour. Here is an early version with one packet redundancy:
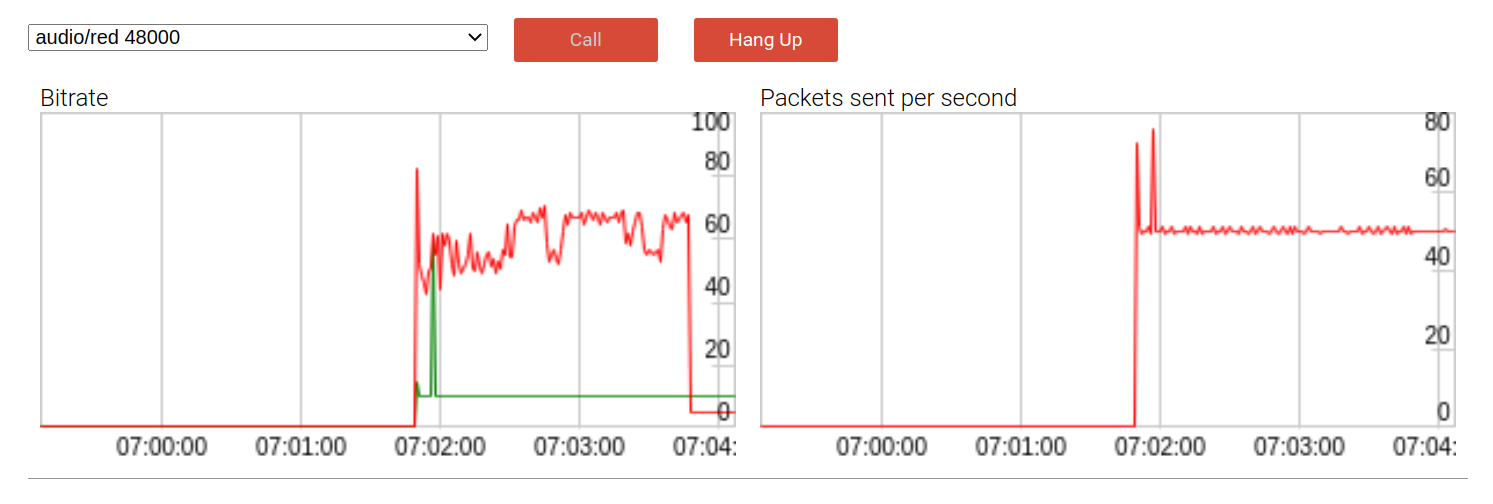
By default, the payload bitrate (red line) is almost twice as high as without redundancy at nearly 60kbps. DTX (discontinuous transmission) is a bandwidth conserving mechanism that send packents only when voice is detected. As expected, when DTX is used the bitrate impact is somewhat mitigated as we can see towards the end of the call.
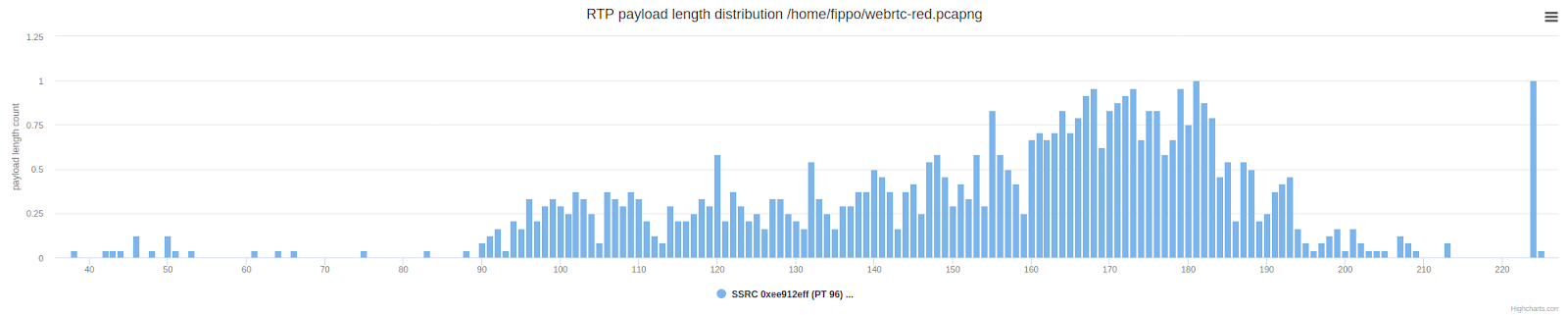
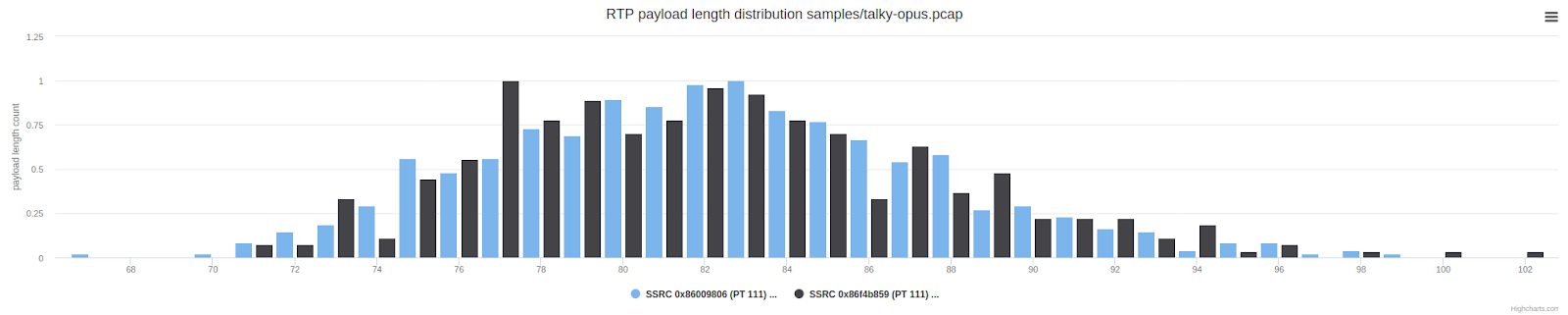
Inspeting the packet lengths reveals the expected result: the packets are twice as long on average (above) compared to the normal distribution of the payload length shown below:
This is still a bit different from what Zoom does, where we saw some redundancy, but many packets without redundancy. Let’s repeat the Zoom packet length chart from earlier so we can look at them side-by-side:
Adding Voice Activity Detection (VAD) support
Opus FEC only sends redundant data if there is voice activity on the packet. The same should be applied to the RED implementation. To do this, the Opus encoder needed to be fixed to expose the correct VAD information that is determined in the SILK layer. With that adjustment, the bitrate only goes to 60kbits if there is speech (vs. 60kps+ continually above):
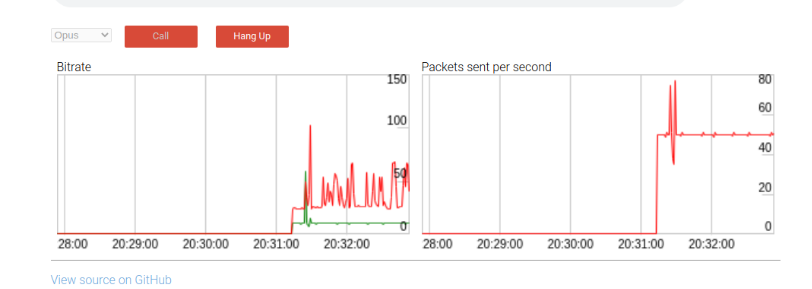
and the “spectrum” looks much more similar to what Zoom does:

The change enabling that fix has not landed yet.
Finding the Right Distance
“Distance” refers to the number of redundant packets. While working on this we ended up discovering that while RED with distance 1 is great, RED with a distance of 2 is significantly better. Our lab evaluation simulated 60% random packet loss. In this environment Opus+RED produced great audio while Opus without RED was severely degraded. The WebRTC getStats() API provides a very useful way to measure this by comparing the percentage of concealed samples, which is obtained from dividing concealedSamples by totalSamplesReceived.
On the audio sample page these stats were easy to obtain with this snippet of JavaScript pasted into the console:
|
1 2 |
(await pc2.getReceivers()[0].getStats()).forEach(report => { if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)}) |
I then ran a couple of tests with packet loss using the not very well known but very useful WebRTCFakeNetworkReceiveLossPercent Chrome fieldtrial flag:
|
1 |
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/ |
With 20% packet loss and FEC enabled by default there was no big difference in audio quality but some difference in the metric:
| scenario | concealment percentage |
| no red | 18% |
| no red, FEC disabled | 20% |
| red with distance 1 | 4% |
| red with distance 2 | 0.7% |
Without RED or FEC the metric is almost the same as the requested packet loss, validating the metric. There is some small effect of FEC but it is not big.
With 60% loss the audio quality got pretty bad without RED, making the sound a bit metallic and the words were hard to understand:
| scenario | concealment percentage |
| no red | 60% |
| red with distance 1 | 32% |
| red with distance 2 | 18% |
There were some audible artifacts with a RED distance of 1 but almost perfect audio with a distance of 2 (which is the amount of redundancy that is now used).
It seems like the human brain can tolerate a certain level of intermittent silence.
(Indirectly related: Google Duo apparently uses a machine learning algorithm to fill the gaps with something better than silence.)
Measuring performance in the real world
We hope that introducing RED to Opus impoves audio quality, but it might make things worse even in some cases. Emil Ivov volunteered to first run a couple of listening tests using the POLQA-MOS method. This has been done in the past for Opus so we have a baseline to compare to.
If the initial tests shows promising result we’ll run a large-scale experiment on the main Jitsi Meet deployment using the concealment percentage metrics we used above.
Note that for media servers and SFUs, enabling RED is a bit more complex as the server may need to manage RED retransmission to select clients, like if not all clients in a conference support RED. Also some clients might be on a bandwidth constrained link where you don’t want RED. If an endpoint does not support RED, the SFU can remove the redundant encoding and send Opus without the wrapper. Likewise it might implement RED itself and use RED when resending packets from an endpoint sending Opus to an endpoint supporting RED.
Many thanks to Jitsi/8×8 Inc for sponsoring this adventure and the folks at Google who reviewed or provided feedback on the changes required.
And without Natalie Silvanovich I would still be stuck looking at encrypted bytes!
{“author”: “Philipp Hancke“}




Excellent and very relevant post about improving audio quality in webrtc video calls. Great work digging into Zoom and comparing packet lenghts. It looks like we might have to wait for some time until browsers support RED by default. What other approaches do you suggest to improve audio quality with webrtc as of right now?
Increasing the audio bitrate from default 30-35kbps might help. Together with things like DTX it is still relatively cheap compared to video.
Probably, SFU should not retransmit RED packets at all, given that the network conditions are so bad (like 60% loss) – to avoid extra congestion and loss.
That depends on the subscriber connection, the bandwidth and loss available there. In some cases RED might not be appropriate.
SFUs are a bit more flexible than browsers though 🙂
Great post, Philipp! I wondered how opus fec actually worked at the byte-level and now I know.
Wait until you see the range encoder:
https://github.com/fippo/opus-fec/
Codec people are… a special bunch 🙂
Thanks for sharing this, question about the test result, when comparing RED with opus FEC on, is that the opus FEC on the same with RED distance 1, except the RED use the full copy while opus FEC use LBRR? so the concealment should not make much difference? Or the it’s actually “RED distance 1 + OPUS FEC on”, which means it’s actually distance 2?
Here is the script for audio RED simulation for different packet loss model, https://gist.github.com/fuji246/d9b6e8e8742e5ebdb1e6a6e0b6b3fbd0
One more thing, wondering why not use LBRR in RED, is that due to implementation effort or some other technical concerns?
Great post. Thanks for sharing.
In my wireshark dump, wireshark is not able to decode the packets, i think its due to end to end encryption of zoom.
Can you provide more detail on setup to dump raw silk frames from zoom.
Hi Ranesh,
the raw silk frames were obtained prior to the transport encryption (and before Zoom added end-to-end encryption) using Frida. The setup is described in detail (for whatsapp) here: https://medium.com/@schirrmacher/analyzing-whatsapp-calls-176a9e776213
It is rather complex…
Thanks for the response.
Is their any way to anaylyse zoom call now after end to end encryption ?