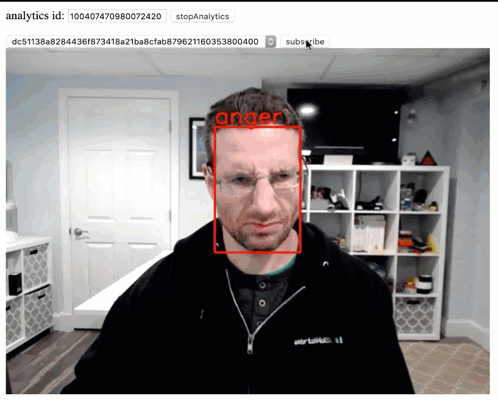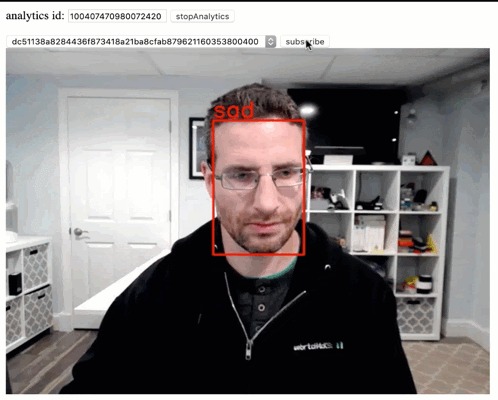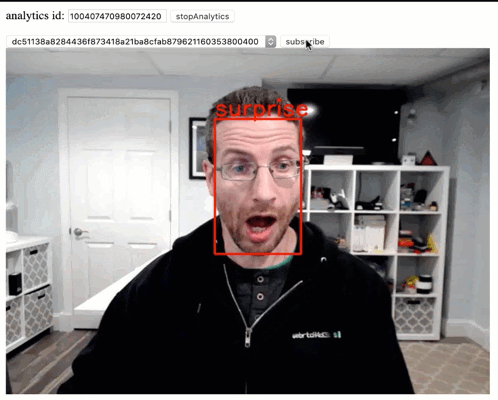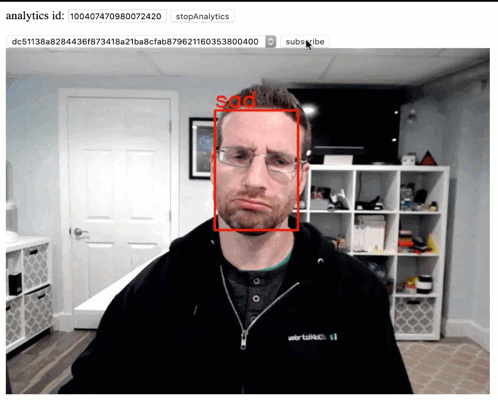
WebRTC has made getting and sending real time video streams (mostly) easy. The next step is doing something with them, and machine learning lets us have some fun with those streams. Last month I showed how to run Computer Vision (CV) locally in the browser. As I mentioned there, local is nice, but sometimes more performance […]
computer vision
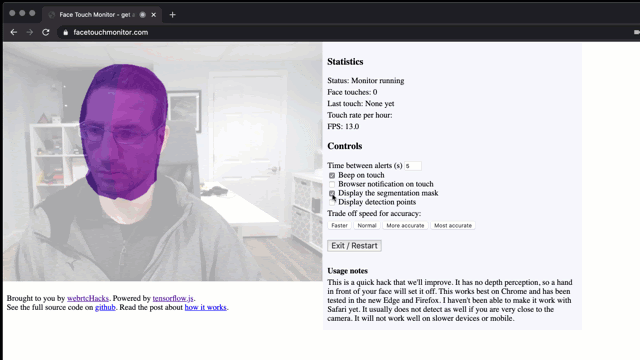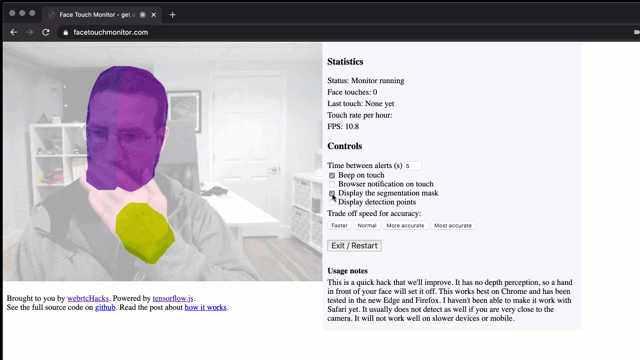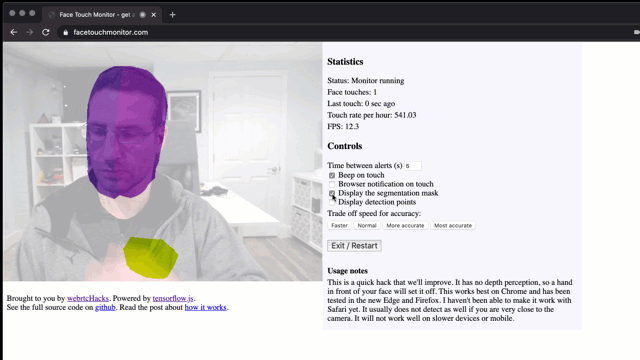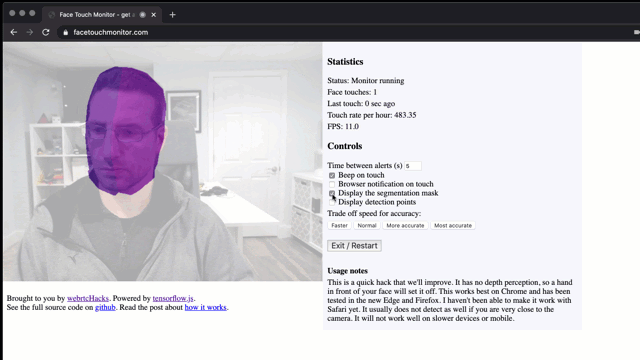
Stop touching your face using a browser and TensorFlow.js
Don’t touch your face! To prevent the spread of disease, health bodies recommend not touching your face with unwashed hands. This is easier said than done if you are sitting in front of a computer for hours. I wondered, is this a problem that can be solved with a browser? We have a number of […]

Smile, You’re on WebRTC – Using ML Kit for Smile Detection
Now that it is getting relatively easy to setup video calls (most of the time), we can move on to doing fun things with the video stream. With new advancements in Machine Learning (ML) and a growing number of API’s and libraries out there, computer vision is also getting easier to do. Google’s ML Kit is […]
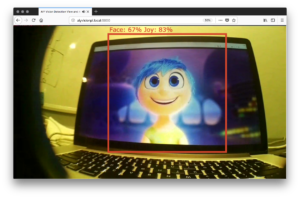
Part 2: Building a AIY Vision Kit Web Server with UV4L
In part 1 of this set, I showed how one can use UV4L with the AIY Vision Kit send the camera stream and any of the default annotations to any point on the Web with WebRTC. In this post I will build on this by showing how to send image inference data over a WebRTC […]
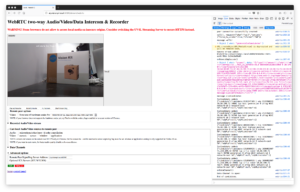
AIY Vision Kit Part 1: TensorFlow Computer Vision on a Raspberry Pi Zero
A couple years ago I did a TADHack where I envisioned a cheap, low-powered camera that could run complex computer vision and stream remotely when needed. After considering what it would take to build something like this myself, I waited patiently for this tech to come. Today with Google’s new AIY Vision kit, we are […]