A couple of weeks ago, the Chrome team announced an interesting Intent to Experiment on the blink-dev list about an API to do some custom processing on top of WebRTC. The intent comes with an explainer document written by Harald Alvestrand which shows the basic API usage. As I mentioned in my last post, this is the sort of thing that maybe able to help add End-to-End Encryption (e2ee) in middlebox scenarios to WebRTC.
I had been watching the implementation progress with quite some interest when former webrtcHacks guest author Emil Ivov of jitsi.org reached out to discuss collaborating on exploring what this API is capable of. Specifically, we wanted to see if WebRTC Insertable Streams could solve the problem of end-to-end encryption for middlebox devices outside of the user’s control like Selective Forwarding Units (SFUs) used for media routing.
The good news it looks like it can! Read below for details.
Before we get into the project, we should first recap how media encryption works with media server devices like SFU’s.
Media Encryption in WebRTC
WebRTC mandates encryption. It uses DTLS-SRTP for encrypting the media. DTLS-SRTP works by using a DTLS handshake to derive keys for encrypting the payload of the RTP packets. It is authenticated by comparing the a=fingerprint lines in the SDP that are exchanged via the signaling server with the fingerprints of the self-signed certificates used in the handshake. This can be called end-to-end encryption since the negotiated keys do not leave the local device and the browser does not have access to them. However, without authentication it is still vulnerable to man-in-the-middle attacks.
See our post about the mandatory use of DTLS for more background information on encryption and how WebRTC landed where it is today.
SFU Challenges
The predominant architecture for multiparty is a Selective Forwarding Unit (SFU). SFUs are basically packet routers that forward a single or small set of streams from one user to many other users. The basics are explained in this post.
In terms of encryption, DTLS-SRTP negotiation happens between each peer endpoint and the SFU. This means that the SFU has access to the unencrypted payload and could listen in. This is necessary for features like server-side recording. On the downside, it means you need to trust the entity running the SFU and/or the client code to keep that stream private. Zero trust is always best for privacy.
Unlike a more traditional VoIP Multipoint Control Unit (MCU) which decodes and mixes media, a SFU only routes packets. It does not care much about the content (apart from a number of bytes in the header and whether a frame is a keyframe). So theoretically the SFU should not need to decode and decrypt anything. SFU developers have been quite aware of that problem since the early days of WebRTC. Similarly, Google’s webrtc.org library has included a “frame encryption” approach for a while which was likely added for Google Duo but doesn’t exist in the browser. However, the “right” API to solve this problem universally only happened now with WebRTC Insertable Streams.
Make it Work
Our initial game plan looked like the following:
- Make it work
End-to-End Encryption Sample
Fortunately making it work was a bit easier since Harald Alvestrand had been working on a sample which simplified our job considerably. The approach taken in the sample is a very nice demonstration:
- opening two connections,
- applying the (intentionally weak, xor-ing the content with the key) encryption on both but
- only decryption on one of them.
You can test the sample on here. Make sure you run the latest Chrome Canary (84.0.4112.0 or later) and that the experimental Web Platform Features flag is on.
The API is quite easy to use. A simple logging transform function looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
const sender = pc1.addTrack(stream.getVideoTracks()[0], stream); const senderStreams = sender.createEncodedVideoStreams() : const senderTransformStream = new TransformStream({ transform: (chunk, controller) { console.log(chunk, chunk.data.byteLength); controller.enqueue(chunk); } }); senderStreams.readableStream .pipeThrough(senderTransformStream) .pipeTo(senderStreams.writableStream); |
The transform function is then called for every video frame. This includes an encoded frame object (named chunk) and a controller object. The controller object provides a way to pass the modified frame to the next step. In our case this is defined by the pipeTo call above which is the packetizer.
Iterating improvements
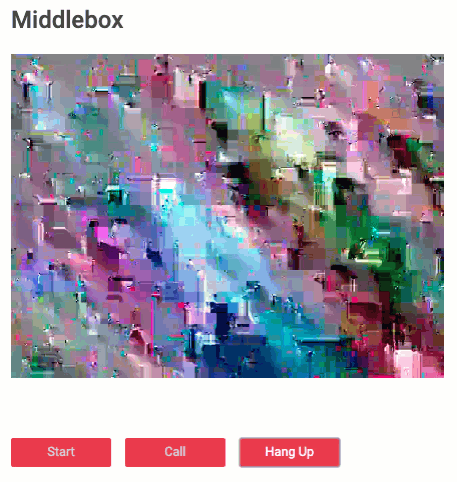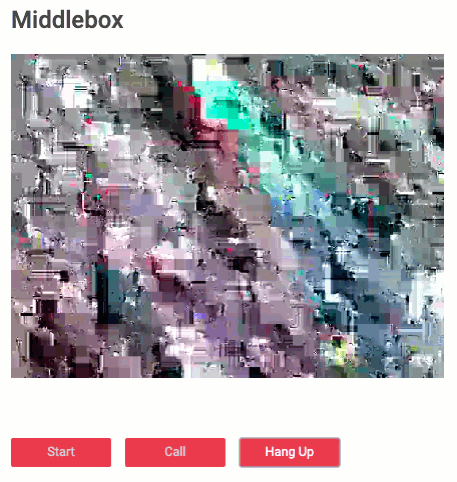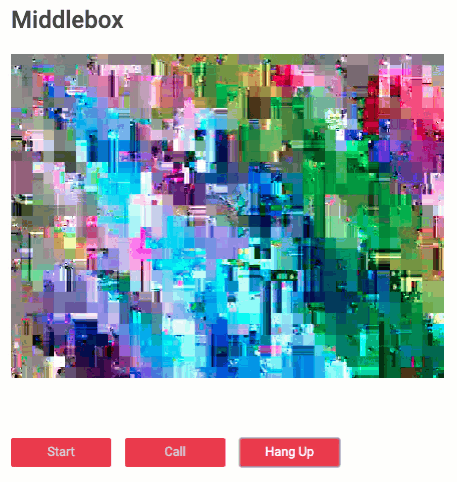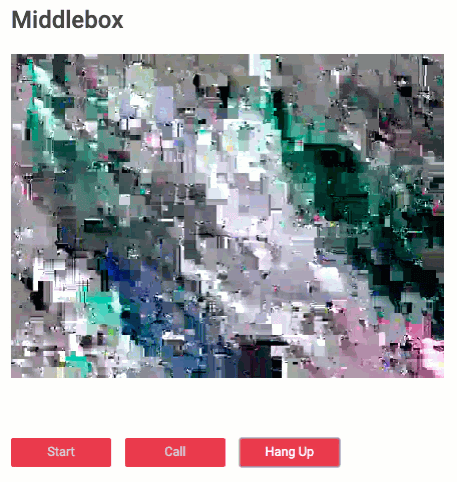
With a fully working sample (video-only at first because audio was not yet implemented), we iterated quickly on some improvements such as key changes and not encrypting the frame header. The latter turned out to be very interesting visually. Initially, upon receiving the encrypted frame, the decoder of the virtual “middlebox” would just throw an error and the picture would be frozen. Exploiting some properties of the VP8 codec and not encrypting the first couple of bytes now tricks the decoder into thinking that frame is valid VP8. Which looks … interesting:

Give the sample a try yourself here.
Insertable Streams iterates on frames, not packets
The Insertable Streams API operates between the encoder/decoder and the packetizer that splits the frames into RTP packets. While it is not useful for inserting your own encoder with WebAssembly (it does not have access to the raw data), it can transform the encoded frame. Encryption is one example of such a transformation.

This is not a new idea – the webrtc.org library already has a native API for frame encryption. However, this was never exposed to the browser. Surprisingly, it is not used by the current API. This can be seen in channel_send.cc. The difference here is that Insertable Streams needs to be asynchronous.
Operating at the frame level – vs. every packet – haa another advantage: not having to worry about how many bytes of overhead are added by the encryption. The packetizer takes care of spitting up the packets.
In addition to that, it makes it easy to pass metadata such as (for video frames) whether the frame is a key frame or a delta frame. The API for that is still a bit in flux so if you need access to this be prepared for changes in the future. After all, this is an experimental API that is still not enabled by default.
Inspect yourself
All this is quite easy to observe in Chrome. When disabling encryption in Chrome (which is possible in Chrome Beta and Canary only) using the --disable-webrtc-encryption flag, you can see what’s happening quite nicely in Wireshark:
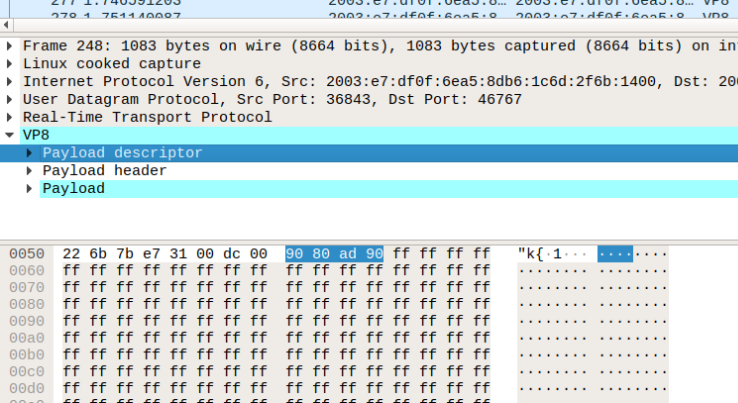
To view what is happening at the packet level, you need Wireshark to decode VP8 (see here). You will need to change the “encryption” to put 0xff into all elements of the frame. You will also need to disable Redundancy (RED) in Chrome to make Wireshark understand the VP8 packets – see here for the SDP munging. Once you do this, the result becomes visible and helps to illustrate the level at which API operates.
What we can see is the VP8 payload descriptor does not change and is followed by our 0xff bytes. This has meaningful implications for how to design the encryption. The payload descriptor is one of the key elements in routing packets so this could continue to used by a SFUs. Importantly, transformation does change the frame itself which is described in the VP8 RFC.
Fixing all the bugs
Playing with the sample showed a number of issues. For example, the transformation was only applied on the sender level when the peer connection was the initiator. Bug reported and a fix came quickly. Simulcast didn’t work either. This was going to be a showstopper for SFUs as simulcast is quite essential there. This one turned out to be a bit more complicated to fix. I was very happy to see the recently landed simulcast web-platform test (using the “playground” approach) provided an easy way to test this.
I ended up filing quite a number of Chrome issues (eight and counting; add nine pull requests with improvements to the sample). They were quickly fixed, showing this was a high priority project for the Chrome WebRTC team trying to push the API into Chrome 83. When bugs are fixed rapidly and the response to filing one is “bring more” that is how WebRTC development should happen. Many thanks to Harald Alvestrand, Marina Ciocea and Guido Urdaneta!
Web Worker support
One of the seemingly unimportant aspects of the Insertable Streams API is that the streams are transferable – i.e. the transformation can be moved to a WebWorker.
Offloading the encryption from the main thread could help performance so I started exploring that. The model I had in mind was passing each frame to the worker, encrypting it there, and then passing it back. This turned out to be wrong. One just transfers the streams, offloading all handling to the worker.
Implementing that in the sample and even more so my own personal playground version of it turned out to be mind-blowing in terms of how the code gets organised.
The PR to the sample shows this nicely.
All the encryption/decryption and the key management now happens in a separate file and that file is easy to inspect in Chrome DevTools. That means the code is cleanly isolated and all communication happens via worker.postMessage . It is also relatively small and therefore easy to audit. Which is great for any piece of code involving cryptography.
A successful experiment
The API delivers the ability to implement end-to-end encryption for Chrome-based WebRTC applications. The general design of using a TransformStream is solid. It will be interesting to see what WebRTC NV use-cases can be enabled with additions that allow access to the unencoded frame.
I like how the API works with WebWorker. I especially like how it allows both isolation and verification of the any cryptography code you write.
Moving from the experiment to a real world application requires a bit more effort. This is particularly true for implementing the encryption and the key management. Head over to jitsi.org to hear more on that story.
{“author”: “Philipp Hancke“}





True End-to-End Encryption is already possible when all peers call each other in P2P. The article title should changed to “True End-to-End Encryption with WebRTC Insertable Streams using SFU/MCU/MediaServer”.
That’s a fair statement and we should have better emphasized “WebRTC p2p is always end-to-end encrypted”. I thought of using “True End-to-End Encryption through Middleboxes with WebRTC Insertable Streams” but it was starting to get long and the larger audience looking for e2ee with video conferencing probably wouldn’t know what we mean by a middle box. We did want to convey “true end-to-end encryption with WebRTC”.
We covered the p2p scenario that better in Fippo’s post previous to this (https://webrtchacks.com/you-dont-have-end-to-end-encryption-e2ee/). I adjusted some of the opening statements to link to that and specify “middlebox” earlier on.
How would this work with firefox users?
Are there plans to do something cross-browser compatible?
This encryption is not supported in Mozilla, IE, and Safari.
What is the solution for this?
Regarding this: “While it is not useful for inserting your own encoder with WebAssembly (it does not have access to the raw data) […]”
I wonder if it is possible to insert a custom codec (Wasm-based) by overwriting the encoded stream? Then the receiver endpoint would use an insertable stream to decode the custom codec, and pipe the decoded stream to an audio element (thus bypassing the rest of the receiver pipeline). To avoid the rest of the receiver pipeline from complaining, we could let it decode a dummy frame with the original codec.
This would be a huge hack, but is it possible at all?
The sender side, on the other hand, could run the Wasm encoder straight from the source stream, and replace the original frame with the Wasm one.
See https://github.com/w3c/webrtc-encoded-transform/issues/121 for some discussion on why the encoded transform API isn’t solving the “bring your own codec” problem
How does this affect compression? Was there an increase in bitrate? I mean there is no Spatial or Temporal redundancy and even if there were, compressing it would cause the frame not decodable. How can this be addressed?