TensorFlow is one of the most popular Machine Learning frameworks out there – probably THE most popular one. One of the great things about TensorFlow is that many libraries are actively maintained and updated. One of my favorites is the TensorFlow Object Detection API. The Tensorflow Object Detection API classifies and provides the location of multiple objects in an image. It comes pre-trained on nearly 1000 object classes with a wide variety of pre-trained models that let you trade off speed vs. accuracy.
The guides are great, but all of them rely on using images you need to add to a folder yourself. I really wanted to hook this into a live WebRTC stream to do real-time computer vision with the web. I could not find any examples or guides on how to do this, so I am writing this. For RTC people, this will be a quick guide on how to use TensorFlow to process WebRTC streams. For TensorFlow people, this will be a quick intro on how to add WebRTC to your project. WebRTC people will need to get used to Python. TensorFlow people will need to get used to web interaction and some JavaScript.
This is not a reasonable getting started guide on either WebRTC or TensorFlow – for that you should see Getting Started with TensorFlow, Getting Started with WebRTC, or any of the innumerable guides on these topics out there.
 Detecting Cats with Tensor Flow and WebRTC
Detecting Cats with Tensor Flow and WebRTC
Just show me how to do it
If you are just coming back for a quick reference or are too lazy to read text, here is a quick way to get started. You need to have Docker installed. Load a command prompt and then type:
|
1 |
docker run -it -p 5000:5000 chadhart/tensorflow-object-detection:runserver |
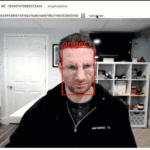
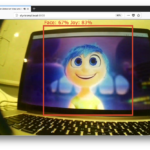
Then point your browser to http://localhost:5000/local accept camera permissions and you should see something like this:
Architecture
Let’s start with a basic architecture that sends locally a local web camera stream from WebRTC’s getUserMedia to a Python server using the Flask web server and the TensorFlow Object Detection API. My setup looks like the graphic below.
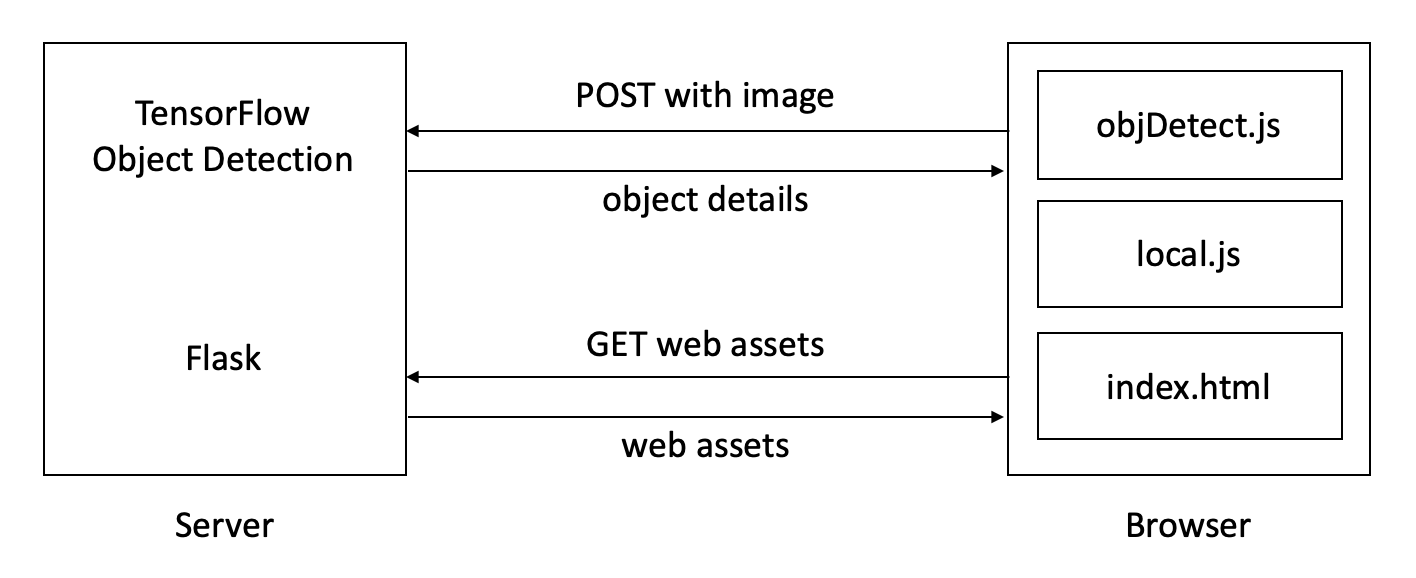
Flask will serve the html and JavaScript files for the browser to render. getUserMedia.js will grab the local video stream. Then objDetect.js will use the HTTP POST method send images to the TensorFlow Object Detection API which will returns the objects it sees (what it terms classes) and their locations in the image. We will wrap up this detail in a JSON object and send it back to objDetect.js so we can show boxes and labels of what we see.
Setup
Setup and Prerequisites
Before we start we’ll need to setup Tensorflow and the Object Detection API.
Easy setup with Docker
I have done this a few times across OSX, Windows 10, and Raspbian (which is not easy). There are a lot of version dependencies and getting it all right can be frustrating, especially when you just want to see something work first. I recommend using Docker to avoid the headaches. you will need to learn docker, but that is something you should probably know anyway and that time is way more productive than trying to build the right version of Protobuf. The TensorFlow project maintains some official Docker images, like tensorflow/tensorflow.
If you go the Docker route, then we can use the image I created for this post. From your command line do the following:
|
1 2 3 |
git clone https://github.com/webrtcHacks/tfObjWebrtc.git cd tfObjWebrtc docker run -it -p 5000:5000 --name tf-webrtchacks -v $(pwd):/code chadhart/tensorflow-object-detection:webrtchacks |
Note the $(pwd) in the docker run only works for Linux and the Windows Powershell. Use %cd% on Windows 10 command line.
At this point you should be in the docker container. Now run:
|
1 |
python setup.py install |
This will use the latest TensorFlow docker image and attach port 5000 on the docker host machine to port 5000 , name the container tf-webrtchacks , map a local directory to a new /code directory in the container, set that as the default directory where we will do our work, and run a bash for command line interaction before we start.
If you are new to TensorFlow then you should probably start by following the instructions in tensorflow/tensorflow to run the intro Jupyter notebook and then come back to the command above.
The Hard Way
If you start from scratch you’ll need to install TensorFlow which has a lot of its own dependencies like Python. The TensorFlow project has guides for various platforms here: https://www.tensorflow.org/install/. The Object Detection API also has its own install instructions with a few additional dependencies. Once you get that far then do this:
|
1 2 3 |
git clone https://github.com/webrtcHacks/tfObjWebrtc.git cd tfObjWebrtc python setup.py install |
That should install all the Python dependencies, copy over the appropriate Tensorflow Object API files, and install the Protobufs. If this does not work then I recommend inspecting the setup.py and running the commands there manually to address any issues.
Code Walkthrough
Part 1 – Make sure Tensorflow works
To make sure the TensorFlow Object Detection API works, let’s start with a tweaked version of the official the Object Detection Demo Jupyter Notebook. I saved this file as object_detection_tutorial.py.
If you cut and paste each section of the notebook, you should have this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
# IMPORTS import numpy as np import os import six.moves.urllib as urllib import sys import tarfile import tensorflow as tf import zipfile from collections import defaultdict from io import StringIO # from matplotlib import pyplot as plt ### CWH from PIL import Image if tf.__version__ != '1.4.0': raise ImportError('Please upgrade your tensorflow installation to v1.4.0!') # ENV SETUP ### CWH: remove matplot display and manually add paths to references ''' # This is needed to display the images. %matplotlib inline # This is needed since the notebook is stored in the object_detection folder. sys.path.append("..") ''' # Object detection imports from object_detection.utils import label_map_util ### CWH: Add object_detection path #from object_detection.utils import visualization_utils as vis_util ### CWH: used for visualization # Model Preparation # What model to download. MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17' MODEL_FILE = MODEL_NAME + '.tar.gz' DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/' # Path to frozen detection graph. This is the actual model that is used for the object detection. PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb' # List of the strings that is used to add correct label for each box. PATH_TO_LABELS = os.path.join('object_detection/data', 'mscoco_label_map.pbtxt') ### CWH: Add object_detection path NUM_CLASSES = 90 # Download Model opener = urllib.request.URLopener() opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE) tar_file = tarfile.open(MODEL_FILE) for file in tar_file.getmembers(): file_name = os.path.basename(file.name) if 'frozen_inference_graph.pb' in file_name: tar_file.extract(file, os.getcwd()) # Load a (frozen) Tensorflow model into memory. detection_graph = tf.Graph() with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') # Loading label map label_map = label_map_util.load_labelmap(PATH_TO_LABELS) categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True) category_index = label_map_util.create_category_index(categories) # Helper code def load_image_into_numpy_array(image): (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8) # Detection # For the sake of simplicity we will use only 2 images: # image1.jpg # image2.jpg # If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS. PATH_TO_TEST_IMAGES_DIR = 'object_detection/test_images' #cwh TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ] # Size, in inches, of the output images. IMAGE_SIZE = (12, 8) with detection_graph.as_default(): with tf.Session(graph=detection_graph) as sess: # Definite input and output Tensors for detection_graph image_tensor = detection_graph.get_tensor_by_name('image_tensor:0') # Each box represents a part of the image where a particular object was detected. detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0') # Each score represent how level of confidence for each of the objects. # Score is shown on the result image, together with the class label. detection_scores = detection_graph.get_tensor_by_name('detection_scores:0') detection_classes = detection_graph.get_tensor_by_name('detection_classes:0') num_detections = detection_graph.get_tensor_by_name('num_detections:0') for image_path in TEST_IMAGE_PATHS: image = Image.open(image_path) # the array based representation of the image will be used later in order to prepare the # result image with boxes and labels on it. image_np = load_image_into_numpy_array(image) # Expand dimensions since the model expects images to have shape: [1, None, None, 3] image_np_expanded = np.expand_dims(image_np, axis=0) # Actual detection. (boxes, scores, classes, num) = sess.run( [detection_boxes, detection_scores, detection_classes, num_detections], feed_dict={image_tensor: image_np_expanded}) ### CWH: below is used for visualizing with Matplot ''' # Visualization of the results of a detection. vis_util.visualize_boxes_and_labels_on_image_array( image_np, np.squeeze(boxes), np.squeeze(classes).astype(np.int32), np.squeeze(scores), category_index, use_normalized_coordinates=True, line_thickness=8) plt.figure(figsize=IMAGE_SIZE) plt.imshow(image_np) ''' |
I am not going to review what the actual TensorFlow code does since that is covered in the Jupyter demo and other tutorials. Instead I’ll just focus on the modifications.
Things we don’t need
I commented out a few sections:
- Changed some location references
- Removed any references to the Python matplot for visualizing the output in GUI-based environments. This isn’t setup in my docker environment – keep those in there depending on how you are running things.
Object Detection API Outputs
As shown in line 111, the Object Detection API outputs 4 objects:
- classes – an array of object names
- scores – an array of confidence scores
- boxes – locations of each object detected
- num – the total number of objects detected
classes, scores, and boxes are all equal sized arrays that parallel to each other, so classes[n] corresponds to scores[n] and boxes[n] .
Since I took out the visualizations, we need some way of seeing the results, so let’s add this to the end of the file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
### CWH: Print the object details to the console instead of visualizing them with the code above classes = np.squeeze(classes).astype(np.int32) scores = np.squeeze(scores) boxes = np.squeeze(boxes) threshold = 0.50 #CWH: set a minimum score threshold of 50% obj_above_thresh = sum(n > threshold for n in scores) print("detected %s objects in %s above a %s score" % ( obj_above_thresh, image_path, threshold)) for c in range(0, len(classes)): if scores[c] > threshold: class_name = category_index[classes[c]]['name'] print(" object %s is a %s - score: %s, location: %s" % (c, class_name, scores[c], boxes[c])) |
The first np.squeeze part just reduces the multi-dimensional array output into a single dimension – just like in the original visualization code. I believe this is a byproduct of TensorFlow usually outputting a multidimensional array.
Then we set a threshold value for the scores it outputs. It appears TensorFlow defaults to 100 objects it returns. Many of these objects are nested within or overlap with higher confidence objects. I have not seen any best practices for picking a threshold value, but 50% seems to work well with the sample images.
Lastly we cycle through the arrays, just printing those that are over the threshold value.
If you run:
|
1 |
python object_detection_tutorial.py |
You should get the following output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
detected 2 objects in object_detection/test_images/image1.jpg above a 0.5 score object 0 is a dog - score: 0.940691, location: [ 0.03908405 0.01921503 0.87210345 0.31577349] object 1 is a dog - score: 0.934503, location: [ 0.10951501 0.40283561 0.92464608 0.97304785] detected 10 objects in object_detection/test_images/image2.jpg above a 0.5 score object 0 is a person - score: 0.916878, location: [ 0.55387682 0.39422381 0.59312469 0.40913767] object 1 is a kite - score: 0.829445, location: [ 0.38294643 0.34582412 0.40220094 0.35902989] object 2 is a person - score: 0.778505, location: [ 0.57416666 0.057667 0.62335181 0.07475379] object 3 is a kite - score: 0.769985, location: [ 0.07991442 0.4374091 0.16590245 0.50060284] object 4 is a kite - score: 0.755539, location: [ 0.26564282 0.20112294 0.30753511 0.22309387] object 5 is a person - score: 0.634234, location: [ 0.68338078 0.07842994 0.84058815 0.11782578] object 6 is a kite - score: 0.607407, location: [ 0.38510025 0.43172216 0.40073246 0.44773054] object 7 is a person - score: 0.589102, location: [ 0.76061964 0.15739655 0.93692541 0.20186904] object 8 is a person - score: 0.512377, location: [ 0.54281253 0.25604743 0.56234604 0.26740867] object 9 is a person - score: 0.501464, location: [ 0.58708113 0.02699314 0.62043804 0.04133803] |
Part 2 – Making a Object API Web Service
In this section we’ll adapt the tutorial code to run as web service. My Python experience is pretty limited (mostly Raspberry Pi projects), so please comment or submit a pull request on anything dumb I did so I can fix it.
2.1 Turn the Demo code into a service
Now that we got the TensorFlow Object API working, let’s wrap it into a function we can call. I copied the demo code into a new python file called object_detection_api.py. You’ll see I removed a bunch of lines that were unused or commented and the print details to console section (for now).
Since we will be outputting this to the web, it would be nice to wrap our output into a JSON object. To do that make sure to add an import json to your imports and then add the following:
|
1 2 3 4 5 6 7 |
# added to put object in JSON class Object(object): def __init__(self): self.name="Tensor Flow Object API Service 0.0.1" def toJSON(self): return json.dumps(self.__dict__) |
Next let’s make a get_objects function reusing our code from before:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def get_objects(image, threshold=0.5): image_np = load_image_into_numpy_array(image) # Expand dimensions since the model expects images to have shape: [1, None, None, 3] image_np_expanded = np.expand_dims(image_np, axis=0) # Actual detection. (boxes, scores, classes, num) = sess.run( [detection_boxes, detection_scores, detection_classes, num_detections], feed_dict={image_tensor: image_np_expanded}) classes = np.squeeze(classes).astype(np.int32) scores = np.squeeze(scores) boxes = np.squeeze(boxes)obj_above_thresh = sum(n > threshold for n in scores) obj_above_thresh = sum(n > threshold for n in scores) print("detected %s objects in image above a %s score" % (obj_above_thresh, threshold)) |
We have an image input and a threshold value with a default of 0.5 . The rest is just restructured from the demo code.
Now lets add some more code to this function to take our values and output then into a JSON object:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
output = [] #Add some metadata to the output item = Object() item.numObjects = obj_above_thresh item.threshold = threshold output.append(item) for c in range(0, len(classes)): class_name = category_index[classes[c]]['name'] if scores[c] >= threshold: # only return confidences equal or greater than the threshold print(" object %s - score: %s, coordinates: %s" % (class_name, scores[c], boxes[c])) item = Object() item.name = 'Object' item.class_name = class_name item.score = float(scores[c]) item.y = float(boxes[c][0]) item.x = float(boxes[c][1]) item.height = float(boxes[c][2]) item.width = float(boxes[c][3]) output.append(item) outputJson = json.dumps([ob.__dict__ for ob in output]) return outputJson |
This time we are using our Object class to create some initial metadata and add that to our output list. Then we use our loop to add Object data to this list. Finally we convert this to JSON and return it.
After that, let’s make a test file (note to self- make tests first) to check it called object_detection_test.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import scan_image import os from PIL import Image # If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS. PATH_TO_TEST_IMAGES_DIR = 'object_detection/test_images' #cwh TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ] for image_path in TEST_IMAGE_PATHS: image = Image.open(image_path) response = object_detection_api.get_objects(image) print("returned JSON: \n%s" % response) |
That’s it. Now run
|
1 |
python object_detection_test.py |
In addition to the console output from before you should see a JSON string:
|
1 2 |
returned JSON: [{"threshold": 0.5, "name": "webrtcHacks Sample Tensor Flow Object API Service 0.0.1", "numObjects": 10}, {"name": "Object", "class_name": "person", "height": 0.5931246876716614, "width": 0.40913766622543335, "score": 0.916878342628479, "y": 0.5538768172264099, "x": 0.39422380924224854}, {"name": "Object", "class_name": "kite", "height": 0.40220093727111816, "width": 0.3590298891067505, "score": 0.8294452428817749, "y": 0.3829464316368103, "x": 0.34582412242889404}, {"name": "Object", "class_name": "person", "height": 0.6233518123626709, "width": 0.0747537910938263, "score": 0.7785054445266724, "y": 0.5741666555404663, "x": 0.057666998356580734}, {"name": "Object", "class_name": "kite", "height": 0.16590245068073273, "width": 0.5006028413772583, "score": 0.7699846625328064, "y": 0.07991442084312439, "x": 0.43740910291671753}, {"name": "Object", "class_name": "kite", "height": 0.3075351119041443, "width": 0.22309386730194092, "score": 0.7555386424064636, "y": 0.26564282178878784, "x": 0.2011229395866394}, {"name": "Object", "class_name": "person", "height": 0.8405881524085999, "width": 0.11782577633857727, "score": 0.6342343688011169, "y": 0.6833807826042175, "x": 0.0784299373626709}, {"name": "Object", "class_name": "kite", "height": 0.40073245763778687, "width": 0.44773054122924805, "score": 0.6074065566062927, "y": 0.38510024547576904, "x": 0.43172216415405273}, {"name": "Object", "class_name": "person", "height": 0.9369254112243652, "width": 0.20186904072761536, "score": 0.5891017317771912, "y": 0.7606196403503418, "x": 0.15739655494689941}, {"name": "Object", "class_name": "person", "height": 0.5623460412025452, "width": 0.26740866899490356, "score": 0.5123767852783203, "y": 0.5428125262260437, "x": 0.25604742765426636}, {"name": "Object", "class_name": "person", "height": 0.6204380393028259, "width": 0.04133802652359009, "score": 0.5014638304710388, "y": 0.5870811343193054, "x": 0.026993142440915108}] |
2.2 Add a Web Server
We have our function – now we’ll make a web service out of it.
Start with a test route
We have a nice API we can easily add to a web service. I found Flask to be the easiest way to do this. Create a server.py and let’s do a quick test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import object_detection_api import os from PIL import Image from flask import Flask, request, Response app = Flask(__name__) @app.route('/') def index(): return Response('Tensor Flow object detection') @app.route('/test') def test(): PATH_TO_TEST_IMAGES_DIR = 'object_detection/test_images' # cwh TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3)] image = Image.open(TEST_IMAGE_PATHS[0]) objects = object_detection_api.get_objects(image) return objects if __name__ == '__main__': app.run(debug=True, host='0.0.0.0') |
Now run the server:
|
1 |
python server.py |
Make sure it works
And then call the web service. In my case I just ran the following from my host machine (since my docker instance is now running the server in the foreground):
|
1 |
curl http://localhost:5000/test | python -m json.tool |
json.tool will help format your output. You should see this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 467 100 467 0 0 300 0 0:00:01 0:00:01 --:--:-- 300 [ { "name": "webrtcHacks Sample Tensor Flow Object API Service 0.0.1", "numObjects": 2, "threshold": 0.5 }, { "class_name": "dog", "height": 0.8721034526824951, "name": "Object", "score": 0.9406907558441162, "width": 0.31577348709106445, "x": 0.01921503245830536, "y": 0.039084047079086304 }, { "class_name": "dog", "height": 0.9246460795402527, "name": "Object", "score": 0.9345026612281799, "width": 0.9730478525161743, "x": 0.4028356075286865, "y": 0.10951501131057739 } ] |
Ok, next let’s make a real route by accepting a POST containing an image file and other parameters. Add a new /image route under the /test route function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@app.route('/image', methods=['POST']) def image(): try: image_file = request.files['image'] # get the image # Set an image confidence threshold value to limit returned data threshold = request.form.get('threshold') if threshold is None: threshold = 0.5 else: threshold = float(threshold) # finally run the image through tensor flow object detection` image_object = Image.open(image_file) objects = object_detection_api.get_objects(image_object, threshold) return objects except Exception as e: print('POST /image error: %e' % e) return e |
This takes an image from a form encoded POST with an optional threshold value and passes it to our object_detection_api.
Let’s test it:
|
1 |
curl -F "image=@./object_detection/test_images/image1.jpg" http://localhost:5000/image | python -m json.tool |
You should see the same result as the /test route above. Go ahead and put a path to any other local image you like.
Make it work for more than localhost
If you are going to be running your browser on localhost you probably don’t need to do anything, but that is not too realistic for a real service or even a lot of tests. Running a web service across networks and with other sources means you’ll need to deal with CORS. Fortunately that’s easy to fix by adding the following before your routes:
|
1 2 3 4 5 6 7 |
# for CORS @app.after_request def after_request(response): response.headers.add('Access-Control-Allow-Origin', '*') response.headers.add('Access-Control-Allow-Headers', 'Content-Type,Authorization') response.headers.add('Access-Control-Allow-Methods', 'GET,POST') # Put any other methods you need here return response |
Make it secure origin friendly
Its best practice to use HTTPS with WebRTC since browsers like Chrome and Safari will only work out of the box secure origins (though Chrome is fine with localhost and you can enable Safari to allow capture on insecure sites – jump to the Debug tools section here ). To do this you’ll need to get some SSL certificates or generate some self-hosted ones. I put mine in the ssl/ directory and then changed the last app.run line to:
|
1 |
app.run(debug=True, host='0.0.0.0', ssl_context=('ssl/server.crt', 'ssl/server.key')) |
If you’re using a self-signed cert, you’ll probably need to add the --insecure option when testing with CURL:
|
1 |
curl -F "image=@./object_detection/test_images/image2.jpg" --insecure https://localhost:5000/image | python -m json.tool |
Since it is not strictly required and a bit more work to make your certificates, I kept the SSL version commented out at the bottom of server.py .
For a production application you would likely use a proxy like nginx to send HTTPS to the outside while keeping HTTP internally (in addition to making a lot of other improvements).
Add some routes to serve our web pages
Before we move on to the browser side of things, let’s stub out some routes that we’ll need later. Put this after the index() route:
|
1 2 3 4 5 6 7 8 |
@app.route('/local') def local(): return Response(open('./static/local.html').read(), mimetype="text/html") @app.route('/video') def remote(): return Response(open('./static/video.html').read(), mimetype="text/html") |
That’s about it for Python. Now we’ll dig into JavaScript with a bit of HTML.
Part 3 – Browser Side
Before we start, make a static directory at the root of your project. We’ll serve our HTML and JavaScript from here.
Now let’s start by using WebRTC’s getUserMedia to grab a local camera feed. From there we’ll send snapshots of that to the Object Detection Web API we just made, get the results, and then display them in real time over the video using the canvas.
HTML
Let’s make our local.html file first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Tensor Flow Object Detection from getUserMedia</title> <script src="https://webrtc.github.io/adapter/adapter-latest.js"></script> </head> <style> video { position: absolute; top: 0; left: 0; z-index: -1; /* Mirror the local video */ transform: scale(-1, 1); /*For Firefox (& IE) */ -webkit-transform: scale(-1, 1); /*for Chrome & Opera (& Safari) */ } canvas{ position: absolute; top: 0; left: 0; z-index:1 } </style> <body> <video id="myVideo" autoplay></video> <script src="/static/local.js"></script> <script id="objDetect" src="/static/objDetect.js" data-source="myVideo" data-mirror="true" data-uploadWidth="1280" data-scoreThreshold="0.25"></script> </body> </html> |
This is what this webpage does:
- uses the WebRTC adapter.js polyfill
- Sets some styles to
- put the elements on top of each other
- put the video on the bottom so we can draw on top of it with the canvas
- Create a video element for our getUserMedia stream
- Link to a JavaScript file that calls getUserMedia
- Link to a JavaScript file that will interact with our Object Detection API and draw boxes over our video
Get the camera stream
Now create a local.js file in the static directory and add this to it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
//Get camera video const constraints = { audio: false, video: { width: {min: 640, ideal: 1280, max: 1920}, height: {min: 480, ideal: 720, max: 1080} } }; navigator.mediaDevices.getUserMedia(constraints) .then(stream => { document.getElementById("myVideo").srcObject = stream; console.log("Got local user video"); }) .catch(err => { console.log('navigator.getUserMedia error: ', err) }); |
You’ll see here we first set some constraints. In my case I asked for an 1280×720 video but require something between 640×480 and 1920×1080. Then we make our getUserMedia with those constraints and assign the resulting stream to the video object we created in our HTML.
Client side version of the Object Detection API
The TensorFlow Object Detection API tutorial includes code that takes an existing image, sends it to the actual API for “inference” (object detection) and then displays boxes and class names for what it sees. To mimic that functionality in the browser we need to:
- Grab images – we’ll create a canvas to do this
- Send those images to the API – we will pass the file as part of a form-body in a XMLHttpRequest for this
- Draw the results over our live stream using another canvas
To do all this create a objDetect.js file in the static folder.
Initialization and setup
We need to start by defining some parameters:
|
1 2 3 4 5 6 |
//Parameters const s = document.getElementById('objDetect'); const sourceVideo = s.getAttribute("data-source"); //the source video to use const uploadWidth = s.getAttribute("data-uploadWidth") || 640; //the width of the upload file const mirror = s.getAttribute("data-mirror") || false; //mirror the boundary boxes const scoreThreshold = s.getAttribute("data-scoreThreshold") || 0.5; |
You’ll notice I included some of these as data- elements in my HTML code. I ended up using this code for a few different project and wanted to reuse the same codebase and this made it easy. I will explain these as they are used.
Setup our video and canvas elements
We need a variable for our video element, some starting events, and we need to create the 2 canvas’ mentioned above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//Video element selector v = document.getElementById(sourceVideo); //for starting events let isPlaying = false, gotMetadata = false; //Canvas setup //create a canvas to grab an image for upload let imageCanvas = document.createElement('canvas'); let imageCtx = imageCanvas.getContext("2d"); //create a canvas for drawing object boundaries let drawCanvas = document.createElement('canvas'); document.body.appendChild(drawCanvas); let drawCtx = drawCanvas.getContext("2d"); |
The drawCanvas is for displaying our boxes and labels. The imageCanvas is for uploading to our Object Detection API. We add the drawCanvas to the visible HTML so we can see it when we draw our object boxes. Next we’ll go to the bottom of ObjDetect.js and work our way up function by function.
Kicking off the program
Trigger off video events
Let’s get our program started. First, let’s trigger off some video events:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
//Starting events //check if metadata is ready - we need the video size v.onloadedmetadata = () => { console.log("video metadata ready"); gotMetadata = true; if (isPlaying) startObjectDetection(); }; //see if the video has started playing v.onplaying = () => { console.log("video playing"); isPlaying = true; if (gotMetadata) { startObjectDetection(); } }; |
We start with looking for both the onplay event and loadedmetadata events for our video – there is no image processing to be done without video. We need the metadata to set our draw canvas size to match the video size in the next section.
Start our main object detection subroutine
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//Start object detection function startObjectDetection() { console.log("starting object detection"); //Set canvas sizes base don input video drawCanvas.width = v.videoWidth; drawCanvas.height = v.videoHeight; imageCanvas.width = uploadWidth; imageCanvas.height = uploadWidth * (v.videoHeight / v.videoWidth); //Some styles for the drawcanvas drawCtx.lineWidth = "4"; drawCtx.strokeStyle = "cyan"; drawCtx.font = "20px Verdana"; drawCtx.fillStyle = "cyan"; |
While the drawCanvas has to be the same size as the video element, the imageCanvas is never displayed and only sent to our API. This size can be reduced with the uploadWidth parameter at the beginning of our file to help reduce the amount of bandwidth needed and lower the processing requirements on the server. Just note, reducing the image might impact the recognition accuracy, especially if you go too small.
While we’re here we will also set some styles for our drawCanvas. I chose cyan but pick any color you want. Just make sure it has a lot of contrast with your video feed for good visibility.
toBlob conversion
|
1 2 3 4 5 |
//Save and send the first image imageCtx.drawImage(v, 0, 0, v.videoWidth, v.videoHeight, 0, 0, uploadWidth, uploadWidth * (v.videoHeight / v.videoWidth)); imageCanvas.toBlob(postFile, 'image/jpeg'); } |
After we have set our canvas sizes we need to figure out how to send the image. I was doing this a more complex way and then I saw Fippo’s grab() function at the last Kranky Geek WebRTC event, so I switched to the simple toBlob method. Once the image is converted to a blob we’ll send it to the next function we will create – postFile .
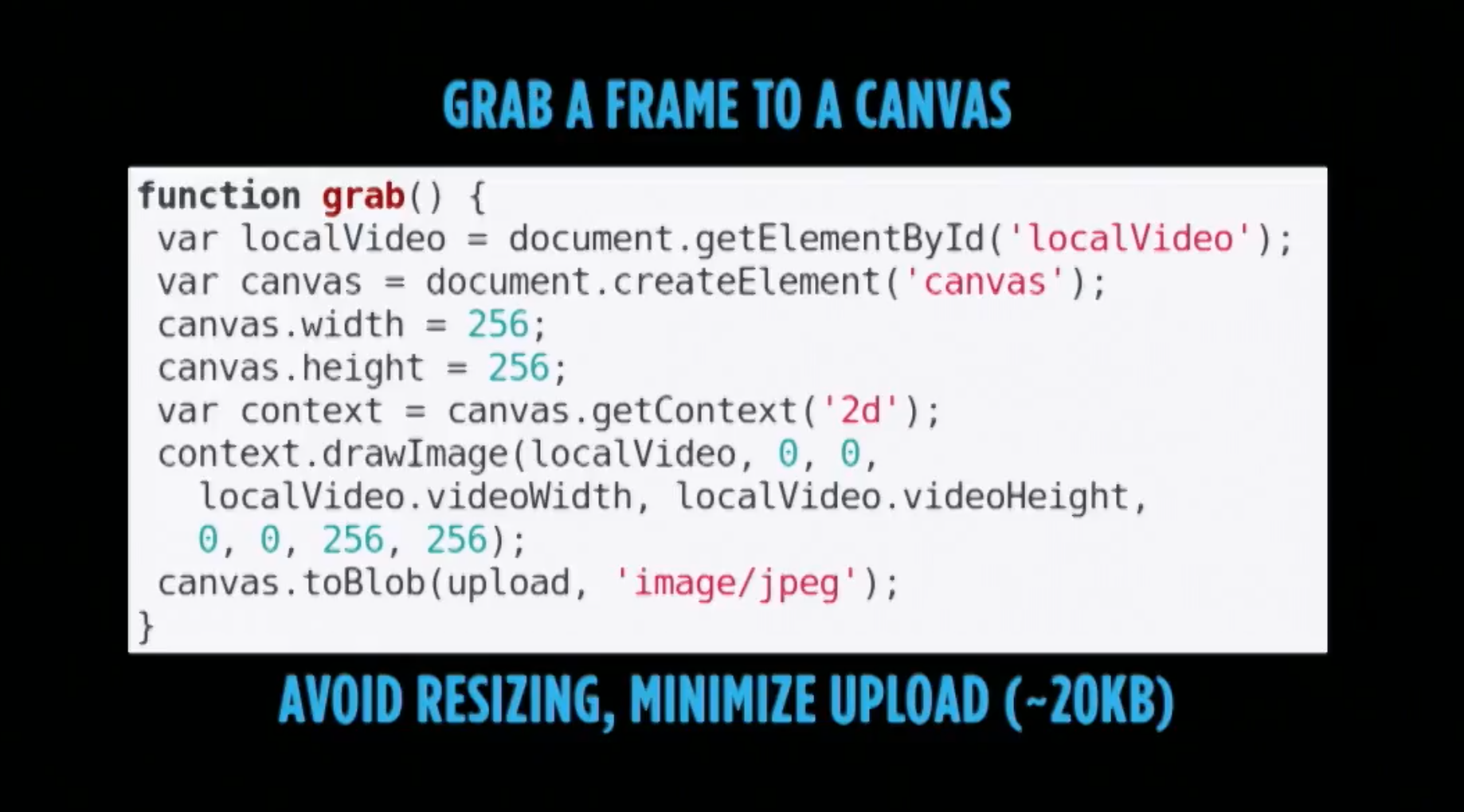
One note – Edge does not seem to support the HTMLCanvasElement.toBlob method. It looks like you can use the polyfill recommended here or the msToBlob instead, but I have not had a chance to try either.
Sending the image to the Object Detection API
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
//Add file blob to a form and post function postFile(file) { //Set options as form data let formdata = new FormData(); formdata.append("image", file); formdata.append("threshold", scoreThreshold); let xhr = new XMLHttpRequest(); xhr.open('POST', window.location.origin + '/image', true); xhr.onload = function () { if (this.status === 200) { let objects = JSON.parse(this.response); //console.log(objects); //draw the boxes drawBoxes(objects); //Send the next image imageCanvas.toBlob(postFile, 'image/jpeg'); } else{ console.error(xhr); } }; xhr.send(formdata); } |
Our postFile takes the image blob as an argument. To send this data we’ll POST it as form data using XHR. Remember, our Object Detection API also takes an optional threshold value, so we can include that here too. To make this easy to adjust without touching this library, this is one of the parameters you can include in a data- tag we set up in the beginning.
Once we have our form set, we use XHR to send it and wait for a response. Once we get the returned objects we can draw them (see the next function). And that’s it. Since we want to do this continually we’ll just keep grabbing a new image and sending it again right after we get a response from the previous API all.
Drawing Boxes and Class Labels
Next we need a function to draw the Object API outputs so we can actually check what is being detected:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function drawBoxes(objects) { //clear the previous drawings drawCtx.clearRect(0, 0, drawCanvas.width, drawCanvas.height); //filter out objects that contain a class_name and then draw boxes and labels on each objects.filter(object => object.class_name).forEach(object => { let x = object.x * drawCanvas.width; let y = object.y * drawCanvas.height; let width = (object.width * drawCanvas.width) - x; let height = (object.height * drawCanvas.height) - y; //flip the x axis if local video is mirrored if (mirror){ x = drawCanvas.width - (x + width) } drawCtx.fillText(object.class_name + " - " + Math.round(object.score * 100, 1) + "%", x + 5, y + 20); drawCtx.strokeRect(x, y, width, height); }); } |
Since we want to have a clean drawing board for our rectangles every time, we start by clearing the canvas with clearRect . Then we just filter our items with a class_name and perform our drawing operation on each.
The coordinates passed in the objects object are percentage units of the image size. To use them with the canvas we need to convert them to pixel dimensions. We also check if our mirror parameter is enabled. If it is is then we’ll flip the x-axis to match the flipped mirror view of the video stream. Finally we write the object class_name and draw our rectangles.
Try it!
Now go to your favorite WebRTC browser and put your URL in. If you’re running on the same machine that will be http://localhost:5000/local (or https://localhost:5000/local if you setup your certificates).
Optimizations
The setup above will run as many frames as possible through the server. Unless setup Tensorflow with GPU optimizations, this will chew up a lot of CPU (like a whole core for me), even if nothing has changed. It would be more efficient to limit how often the API is called and to only invoke the API when there is new activity in the video stream. To do this I made some modifications to the objDetect.js in a new file objDetectOnMotion.js.
This is mostly the same, except I added 2 new functions. First, instead of grabbing the image every time, we’ll use a new function sendImageFromCanvas() that only send the image if it has changed within a given framerate – a new updateInterval parameter which the maximum the API can be called. We’ll use a new canvas and context for this
That code is pretty simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//Check if the image has changed & enough time has passeed sending it to the API function sendImageFromCanvas() { imageCtx.drawImage(v, 0, 0, v.videoWidth, v.videoHeight, 0, 0, uploadWidth, uploadWidth * (v.videoHeight / v.videoWidth)); let imageChanged = imageChange(imageCtx, imageChangeThreshold); let enoughTime = (new Date() - lastFrameTime) > updateInterval; if (imageChanged && enoughTime) { imageCanvas.toBlob(postFile, 'image/jpeg'); lastFrameTime = new Date(); } else { setTimeout(sendImageFromCanvas, updateInterval); } } |
imageChangeThreshold is a percentage representing the percentage of pixels that changed. We’ll take this and pass it to an imageChange function that returns a true or false if the threshold has been exceeded. Here is that function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
//Function to measure the chagne in an image function imageChange(sourceCtx, changeThreshold) { let changedPixels = 0; const threshold = changeThreshold * sourceCtx.canvas.width * sourceCtx.canvas.height; //the number of pixes that change change let currentFrame = sourceCtx.getImageData(0, 0, sourceCtx.canvas.width, sourceCtx.canvas.height).data; //handle the first frame if (lastFrameData === null) { lastFrameData = currentFrame; return true; } //look for the number of pixels that changed for (let i = 0; i < currentFrame.length; i += 4) { let lastPixelValue = lastFrameData[i] + lastFrameData[i + 1] + lastFrameData[i + 2]; let currentPixelValue = currentFrame[i] + currentFrame[i + 1] + currentFrame[i + 2]; //see if the change in the current and last pixel is greater than 10; 0 was too sensitive if (Math.abs(lastPixelValue - currentPixelValue) > (10)) { changedPixels++ } } //console.log("current frame hits: " + hits); lastFrameData = currentFrame; return (changedPixels > threshold); } |
The above is a much improved version of how I did motion detection long ago in the Motion Detecting Baby Monitor hack. It starts by measuring the RGB color values of each pixel. If those values exceed an absolute difference of 10 across the aggregate color values for that pixel then the pixel is deemed to have changed. The 10 is a little arbitrary, but seemed to be a good value in my tests. If the number of change pixels crosses the threshold than the function returns true.
After researching this a bit more I saw other algorithms typically convert to greyscale since color is not a good indicator of motion. Applying a gaussian blur can also smooth out encoding variances. Fippo had a great suggestion to look into Structural Similarity algorithms as used by the test.webrtc.org to detect video activity (see here). More to come here.
Works on any video element
This code will actually work on any <video> element, including a remote peer’s video in a WebRTC peerConnection. I did not want to make this post/code any longer and complex, but I did include a video.html file in the static folder as an illustration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Tensor Flow Object Detection from a video</title> <script src="https://webrtc.github.io/adapter/adapter-latest.js"></script> </head> <style> video { position: absolute; top: 10; left: 10; z-index: -1; } canvas{ position: absolute; top: 10; left: 10; z-index:1 } </style> <body> <video id="myVideo" crossOrigin="anonymous" src="https://webrtchacks.com/wp-content/uploads/2014/11/webrtcDogRemover-working.mp4" muted controls></video> <script id="objDetect" src="/static/objDetectOnMotion.js" data-source="myVideo" data-scoreThreshold="0.40"></script> </body> </html> |
You should see this (running on the video I took from my How to Train a Dog with JavaScript project):
Try it with your own video. Just be aware of CORS issues if you are using a video hosted on another server.
This was a long one
This took quite some time to get going, but now I hope to get on to the fun part of trying different models and training my own classifiers. The published Object Detection API is designed for static images. A model tuned for video and object tracking would be great to try.
In addition, there is a long list of optimizations to make here. I was not running this with a GPU, which would make a huge difference in performance. It takes about 1 core to support 1 client at a handful of frames, and I was using the fastest/least accurate model. There is a lot of room to go here to improve performance. It would also be interesting to see how well this performs in a GPU cloud network.
There is no shortage of ideas for additional posts in this area – any volunteers?
{“author”: “chad hart“}


incredible , thanks a lot, going to try it too
Great tutorial 🙂
Amazing tutorial, I followed the “Hard way” section and work perfectly.
Here is the reference for Tensorflow Object Detection Model for other readers.
https://github.com/tensorflow/models/tree/master/research/object_detection
Thanks Chad
Simply awesome. Gonna try that for sure.
As usual, amazing stuff. Thanks for the great tutorial.
Gonna try this over a GPU cloud network, will let you know the results
Please do share! My hack here certainly wouldn’t scale well into a service, but the situation should dramatically with a proper GPU setup.
I have another set of posts coming soon applying a similar technique to an embedded device too.
Thanks for the very detailed write-up!
Just to be complete, if you want to process an actual video stream (as opposed to capturing individual images and sending them using an XHR), you could make use of an RTCPeerConnection. On the server side you can make use of “aiortc”, a Python implementation of WebRTC. You can then grab whatever frames you want, apply image processing and even return the results as a video stream.
Can you please elaborate? because i have implemented this tutorial and there is lag.
Thanks for this incredible work, unfortunately I have a problem and I have not been able to solve it, I am using windows 10 and at the moment of executing the service it throws me the following error
TypeError: Object of type ‘int32’ is not JSON serializable
Any idea what it could be?
You are seeing this in the Python console output?
I’m not sure why you are getting an error – I ran mine on Win10 and OSX. Offhand the only piece of the output JSON that is an integer is line 106 of the object_detection_apy.py:
item.numObjects = obj_above_thresh. You could try to convert that to a string withstr()or something like it to see if that works (or just remove that line).If you still have trouble please open an issue in the github repo where others are more likely to see it: https://github.com/webrtcHacks/tfObjWebrtc/issues
Yes is in the console, the probles seems come form File “D:\web\tfObjWebrtc\object_detection_api.py”, line 126, in get_objects
outputJson = json.dumps([ob.__dict__ for ob in output])
I solved yet, i put item.numObjects = str(obj_above_thresh) as you says
Thanks a lot
i wanna use my own trained model for myobjectdetection but when i try to run i get this error
127.0.0.1 – – [02/Aug/2018 02:48:45] “[1m[35mPOST /image HTTP/1.1[0m” 500 –
Traceback (most recent call last):
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 2309, in __call__
return self.wsgi_app(environ, start_response)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 2295, in wsgi_app
response = self.handle_exception(e)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 1741, in handle_exception
reraise(exc_type, exc_value, tb)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\_compat.py”, line 35, in reraise
raise value
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 2292, in wsgi_app
response = self.full_dispatch_request()
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 1816, in full_dispatch_request
return self.finalize_request(rv)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 1831, in finalize_request
response = self.make_response(rv)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 1982, in make_response
reraise(TypeError, new_error, sys.exc_info()[2])
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\_compat.py”, line 34, in reraise
raise value.with_traceback(tb)
File “C:\Python36\lib\site-packages\flask-1.0.2-py3.6.egg\flask\app.py”, line 1974, in make_response
rv = self.response_class.force_type(rv, request.environ)
File “C:\Python36\lib\site-packages\werkzeug\wrappers.py”, line 921, in force_type
response = BaseResponse(*_run_wsgi_app(response, environ))
File “C:\Python36\lib\site-packages\werkzeug\test.py”, line 923, in run_wsgi_app
app_rv = app(environ, start_response)
TypeError: ‘InvalidArgumentError’ object is not callable
The view function did not return a valid response. The return type must be a string, tuple, Response instance, or WSGI callable, but it was a InvalidArgumentError.
im trying to use the model faster_rcnn_inception_v2_pets.config, i been relaced the routes for the frozen inference graph and labelmap.pbtxt but this error continues, can you help me? (my model is only one)
What happens when you try to run a saved image through object_detection_api_test.py? You’ll need to modify that code a bit for your image paths and the number of images.
It would be better to move this thread to https://github.com/webrtcHacks/tfObjWebrtc/issues
pless help me
app_rv = app(environ, start_response)
TypeError: ‘JpegImageFile’ object is not callable
The view function did not return a valid response. The return type must be a string, tuple, Response instance, or WSGI callable, but it was a JpegImageFile.
Hi, thanks for this detailed post. Very informative. I’ve developed a similar solution using
aiortc– A WebRTC implementation in Python using asyncio. The result is a low latency real time object detection inference solution. The git repository can be found here: https://github.com/omarabid59/YOLO_Google-Cloud . Let me know if this is of interest to anyone and I can write a detailed post on it!Great post, Chad. Sorry for the very late response.
Omar, have you had time to post a blog about your aiortc based solution?
I am definitely interested, please write one! Thank you!
i am interested Omar. Did you write detailed article with aiortc?
Hi Omar. That sounds interesting and I have been meaning to give aiortc a try. Can you send an email to my chadwhart Gmail so we can discuss the details?
Thank you so much for this tutorial, can you add a new article where we can use websockets instead of sending the image using post.
or any suggestion on how to improve the speed of this??
Please see https://github.com/webrtcHacks/tfObjWebrtc/issues/1 for comments on both topics.
For more speed using server-side Tensorflow I would either reduce the resolution or and/or add GPU support (or even TPU support if you are using Google Cloud Platform) on the server.
I am working on GPU and still there is lag of 7-9 seconds..Can you suggest something else?
hi, I have a problem when i run object_detection_test.py
the error is:
Traceback (most recent call last):
File “object_detection_test.py”, line 1, in
import scan_image
ModuleNotFoundError: No module named ‘scan_image’
I haven’t found “scan_image” anywhere
I tried to run:
python3 object_detection_test.py
but it gave me the same error… Can you help me please?
Hi,
This is a great post. I was wondering if this will work for multiple webcam for real time?
I never tested having multiple browsers connect at the same time but that should work fine as long as you have enough processing to handle each stream.
I have tested and it is working fine..:-)
Does this work on the google cloud environment aswell?I had a different approach prior ,it gave me an issue that the camera device was not found
Hi Hazel – you are trying to run the browser part from GCP?
Excellent technical advice, many thanks for this.
However, I have a question about this. Since we are using WebRTCP packets, it follows that WebRTC only transmits RTP packets, correct? Please provide guidance on how to handle RTCP packets in TensorFlow.
RTCP is the control channel for RTP. The WebRTC stack handles that. Are trying to do some analysis based on RTP’s packet flows where you need access to that?
Yes, I just want to process image recognition data from RTP packets instead of getting it from HTTP request from browser.