During this year’s WWDC keynote, Apple announced the availability of FaceTime in web browsers, making it available to Android and Windows users. It has been six years since the last time we looked at FaceTime (FaceTime Doesn’t Face WebRTC) so it was about time for an update. It had to be WebRTC and as I’ll show – it is very much WebRTC.
tl;dr
FaceTime Web does use WebRTC for media and it uses the Insertable Streams API for end-to-end encryption. It also uses an interesting approach to avoid simulcast.
Fortunately, my old friend Dag-Inge Aas was around to set up a meeting and helped me grab the necessary data for analysis. Tooling has become a bit better since so in addition to the WebRTC internals dump I got an RTP dump and an SCTP dump from the Chrome logs as well as some of the JavaScript that does the end to end encryption (E2EE).
Joining a meeting
Upon pasting the invite link into my browser I get asked to enter my name and join the call which needs to be accepted by the person setting up the meeting. So far, it doesn’t seem like calls can be initiated from the web.
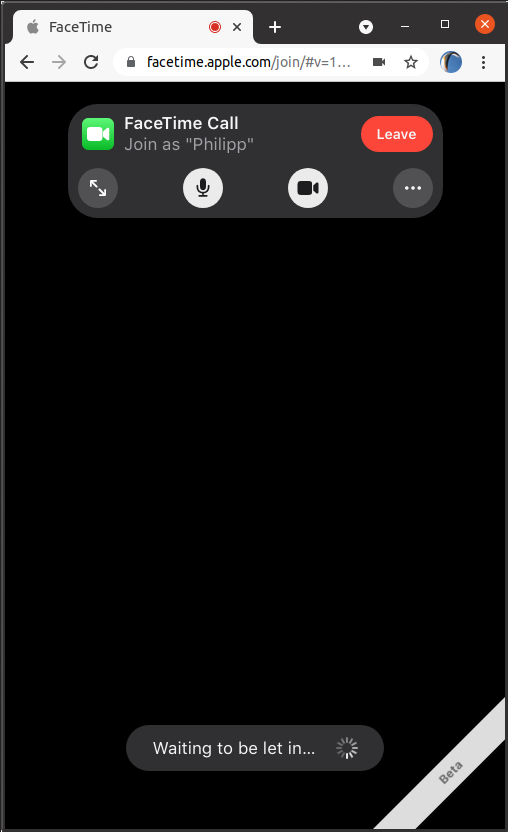
The device testing is dearly lacking a display for audio level display as we spent the usual amount of time figuring out whose microphone was not working correctly.
I could spot Dag-Inge’s phone number in the binary signaling traffic sent over the WebSocket. His number wasn’t new to me but be careful with whom you share these invites.
The URL
But first, let’s start with the URL Dag-Inge sent:
https://facetime.apple.com/join#v=1&p=
<a base64 encoded string>&k=<another base64 encoded string>
The usage of the hash part of the URL hash is somewhat expected, having used the same technique for end-to-end encryption in Jitsi Meet last year. The important property the hash has is that it does not get sent to the server, making it a good location to put sensitive data like encryption keys.
The “p” argument gets sent to the server over a secure WebSocket so is likely a public key. We’ll cover end-to-end encryption further down.
webrtc-internals analysis
If you want to draw your own conclusions, find the dump here and import it using the import tool.
getUserMedia constraints

The getUserMedia part of the webrtc-internals dump is relatively easy to interpret. getUserMedia is used to acquire the microphone and camera. The video constraints ask for the user-facing camera and an ideal height of 720 pixels. The width isn’t specified but for most cameras this will result in a 1280×720 pixel video stream being captured. Which is later cropped to a square 720×720 one, probably by using the track.applyConstraints method.
RTCPeerConnection arguments
The RTCPeerConnection part is more complicated. The constructor arguments already hint at the usage of Insertable Streams (now named “Encoded Transform“) for end-to-end encryption:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Connection:21-1 URL: https://facetime.apple.com/applications/facetime/current/en-us/index.html?rootDomain=facetime#join/ Configuration: "{ iceServers: [], iceTransportPolicy: all, bundlePolicy: max-bundle, rtcpMuxPolicy: require, iceCandidatePoolSize: 0, sdpSemantics: \"unified-plan\", encodedInsertableStreams: true, extmapAllowMixed: true } "Legacy (chrome) constraints: "" Signaling state: => SignalingStateHaveLocalOffer => SignalingStateStable => SignalingStateHaveRemoteOffer => SignalingStateStable => SignalingStateHaveRemoteOffer => SignalingStateStable => SignalingStateHaveRemoteOffer => SignalingStateStable ICE connection state: => checking => connected Connection state: => connecting => connected |
Unified plan sdpSemantics is the default here (and if you still use plan-b you better stop doing that soon). rtcpMuxPolicy being set to require and a bundlePolicy of max-bundle is pretty standard too. encodedInsertableStreams set to true is what enables the insertable streams API. It is only shown in chrome://webrtc-internals in Chrome 92 or higher.
No ICE servers are used which means things will not work when UDP is blocked. Given that this connection only talks to a server, ICE server’s usually are not required outside of restrictive environments like those in many enterprises. The limited transport option makes it unlikely FaceTime will be much of a real “Zoom competitor” as The Verge describes it – at least for business use cases.
Offer / Answer Exchange
The high-level WebRTC flow is shown below:
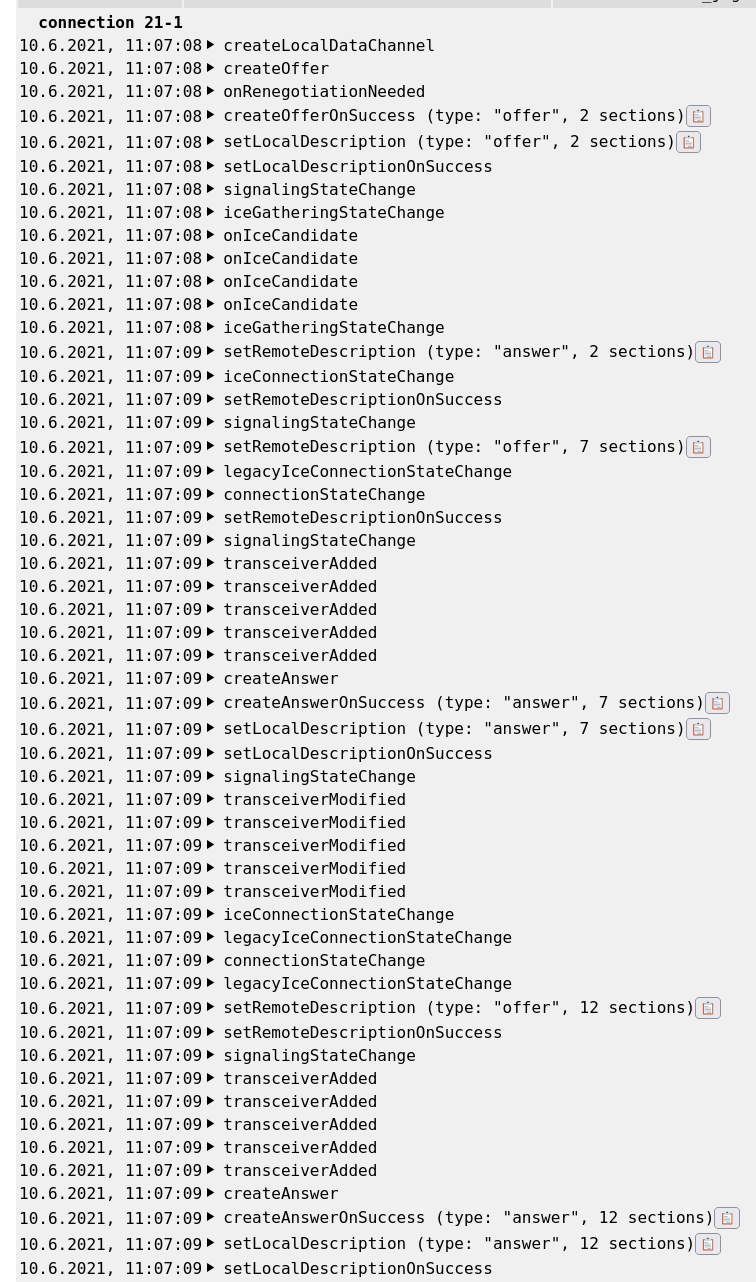
The client begins by offering a datachannel to the server, the server then sends a new offer, adding audio and video. The number of media sections added to the SDP (2, 7, 12, …) in each step is quite important as we will see later.
SDP Analysis
The first answer to the datachannel-only offer is pretty standard (see also our old SDP Anatomy post for the meaning of some lines):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
v=0 o=- 6972089255627587584 6972089255627587584 IN IP4 127.0.0.1 s=- t=0 0 a=group:BUNDLE 0 a=ice-lite m=application 9 UDP/DTLS/SCTP webrtc-datachannel c=IN IP4 127.0.0.1 a=rtcp:9 IN IP4 0.0.0.0 a=candidate:1 1 udp 1 17.252.108.36 3483 typ host a=ice-ufrag:iiTRM3DatXbD a=ice-pwd:vAsEpbbiFr7whr1KxJlwGKiM a=ice-options:trickle a=fingerprint:sha-256 76:DD:71:C3:27:74:F6:2D:38:77:1B:C2:A5:8C:26:3E:9D:B4:21:C7:A1:BE:03:CE:E7:A5:75:99:F9:1D:B4:8F a=setup:passive a=mid:0 a=sctp-port:5000 a=max-message-size:262144 a=rtcp-mux a=rtcp-rsize |
It does however specify rtcp, rtcp-mux and rtcp-rsize attributes in a section where these attributes don’t mean anything. How sloppy!
ice-options is a session-level attribute and does not belong at media level – that is a bug that WebRTC made popular.
The server is an ice-lite server, so no peer-to-peer connection even though Dag-Inge and I started the session as 1-1 and were only later joined by a second device on his side. Allowing such sessions to use direct peer-to-peer connections, commonly known as P2P4121 is a pretty common pattern that we don’t see here.
The only thing to note here is that the setup attribute which controls the direction of the DTLS handshake is set to passive. Keep that in mind for when we look at the statistics.
Video parameters
The first offer from the server is where things start to get interesting. In the datachannel section there is no change and the server adds three video sections and two audio section for each participant:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
m=video 9 UDP/TLS/RTP/SAVPF 123 c=IN IP4 127.0.0.1 a=rtcp:9 IN IP4 0.0.0.0 a=candidate:1 1 udp 1 17.252.108.36 3483 typ host a=ice-ufrag:iiTRM3DatXbD a=ice-pwd:vAsEpbbiFr7whr1KxJlwGKiM a=ice-options:trickle a=fingerprint:sha-256 76:DD:71:C3:27:74:F6:2D:38:77:1B:C2:A5:8C:26:3E:9D:B4:21:C7:A1:BE:03:CE:E7:A5:75:99:F9:1D:B4:8F a=setup:passive a=mid:1 a=extmap:1 urn:3gpp:video-orientation a=extmap:6 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time a=recvonly a=rtcp-mux a=rtcp-rsize a=rtpmap:123 H264/90000 a=rtcp-fb:123 nack pli a=rtcp-fb:123 ccm fir a=rtcp-fb:123 goog-remb a=fmtp:123 level-asymmetry-allowed=1;packetization-mode=1;profile-level-id=42c01f |
The video sections unsurprisingly use H.264 baseline profile 42c01f as the only codec offered. They don’t differ much and are recvonly, suggesting a unidirectional use of transceivers.
RTX is not used for retransmissions and we see only the urn:3gpp:video-orientation extension (that allows to specify a video orientation which is pretty important on mobile devices that tend to get rotated in the middle of the call) as well as the abs-send-time extension. The latter is used with the still popular REMB bandwidth estimation algorithm described back in 2013. The newer (2015) transport-cc algorithm and extension are not used.
Making Apple put “goog-remb” into the SDP… well played Harald!
Apart from a missing nack feedback mechanism (there is only “nack pli”, for the WebRTC library this probably doesn’t make a difference though), there isn’t much more we can learn from the video part of the offer.
Audio parameters
On the other hand, the two audio m-lines are interesting:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
m=audio 9 UDP/TLS/RTP/SAVPF 96 c=IN IP4 127.0.0.1 a=rtcp:9 IN IP4 0.0.0.0 a=candidate:1 1 udp 1 17.252.108.36 3483 typ host a=ice-ufrag:iiTRM3DatXbD a=ice-pwd:vAsEpbbiFr7whr1KxJlwGKiM a=ice-options:trickle a=fingerprint:sha-256 76:DD:71:C3:27:74:F6:2D:38:77:1B:C2:A5:8C:26:3E:9D:B4:21:C7:A1:BE:03:CE:E7:A5:75:99:F9:1D:B4:8F a=setup:passive a=mid:4 a=extmap:2 urn:ietf:params:rtp-hdrext:ssrc-audio-level vad=off a=extmap:6 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time a=recvonly a=rtcp-mux a=rtcp-rsize a=rtpmap:96 opus/48000/2 a=rtcp-fb:96 goog-remb a=fmtp:96 ptime=60 m=audio 9 UDP/TLS/RTP/SAVPF 97 c=IN IP4 127.0.0.1 a=rtcp:9 IN IP4 0.0.0.0 a=candidate:1 1 udp 1 17.252.108.36 3483 typ host a=ice-ufrag:iiTRM3DatXbD a=ice-pwd:vAsEpbbiFr7whr1KxJlwGKiM a=ice-options:trickle a=fingerprint:sha-256 76:DD:71:C3:27:74:F6:2D:38:77:1B:C2:A5:8C:26:3E:9D:B4:21:C7:A1:BE:03:CE:E7:A5:75:99:F9:1D:B4:8F a=setup:passive a=mid:5 a=extmap:2 urn:ietf:params:rtp-hdrext:ssrc-audio-level vad=off a=extmap:6 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time a=recvonly a=rtcp-mux a=rtcp-rsize a=rtpmap:97 opus/48000/2 a=rtcp-fb:97 goog-remb a=fmtp:97 ptime=40;useinbandfec=1 |
The Opus codec is used for audio, which must have been added to the native FaceTime client (it wasn’t there before). Natalie Silvanovich might investigate potential vulnerabilities here a bit for our collective enjoyment, as she did before 🙂
Devices without iOS 15 can not join a call is an indicator of this (also they will not support the E2EE scheme).
Excuse the obligatory complaint about putting the fingerprint as well as the ice-ufrag and ice-pwd into each media section instead of putting them at the session level. This repeats the same information many times over.
Also, the setup attribute of this offer is set to passive (from the previous answer), in direct violation of RFC 5763. Oddly, Chrome accepts this. Time for the IETFs protocol police to take action here!
In terms of header extensions we see the ssrc-audio-level with an additional specifier vad=off and the abs-send-time extension. The ssrc-audio-level is commonly used for active speaker detection in SFUs and FaceTime is known to use such a feature.
It means it is sending the audio level data unencrypted. This is not ideal but common practice. We might see some movement here with Lennart Grahls WebRTC contributions to fix encrypted header extensions
The use of vad=off is technically allowed, but this is such an obscure feature the WebRTC library does not even implement it. Star this bug if you think it should but don’t expect much push around it. We will see this again in the JavaScript section of the post…
What is interesting here is the usage of two audio sections, with different codec specifications. We have Opus both times but with different payload types (96 and 97) and different packetization times — 40 and 60 milliseconds which is considerably larger than the 20ms commonly used by WebRTC. Also, Opus inband FEC is only enabled for one of them which might be the reason that two different payload types are used. Opus DTX – discontinuous transmission – is not used.
If this call is end-to-end encrypted (no claims have been made with respect to that but the usage of insertable streams for providing another layer of encryption suggests that. I hope they provide a whitepaper at some point that goes into the same level of detail as the one written for Google Duo).
The next offer from the server increases the number of media sections by another five. We have two additions here that are notable.
First the new media sections which are sendonly and suggest a new participant has joined the call. The second is pretty subtle, adding a=ssrc lines with a cname to each section (even though it is not clear why. This means the remote end can now send data using those SSRCs. Putting them next to each other:
|
1 2 3 4 5 |
a=ssrc:3633224106 cname:3243262565732983040 a=ssrc:2993385163 cname:3243262565732983040 a=ssrc:4150121997 cname:3243262565732983040 a=ssrc:1095248263 cname:3243262565732983040 a=ssrc:2285848791 cname:3243262565732983040 |
It is easy to see that they share the same cname. This means that they are from the same participant (once you decode RFC 3550 language). This is kind of a poor man’s simulcast. It turns out to be quite an interesting hack as we will see later when inspecting the JavaScript.
The cnames seem to be numeric, one of them is even negative which is a rather odd choice.
The rest of the WebRTC API calls are pretty uninteresting, adding yet another five media sections when a third device joins.
So let’s move on to the statistics section of the dump.
WebRTC statistics
The statistics gathered by chrome://webrtc-internals tell quite a bit about the behavior of the application such as the bitrates.
They also do tell a bit about things like encryption, so we can see the kind of certificates used in the DTLS exchange (ECDSA certificates which is standard these days) as well as the SRTP cipher. This turns out to be AEAD_AES_256_GCM, a cipher suite that got enabled in Chrome last year. It only gets used in certain conditions as it is not the default cipher suite which explains the use of the passive setup in the SDP. See the chrome bug for details – it seems the FaceTime developers read it as well. Or brought that knowledge with them.
On the incoming audio statistics we can see a modest amount of Forward Error Correction (FEC) despite no packet loss:
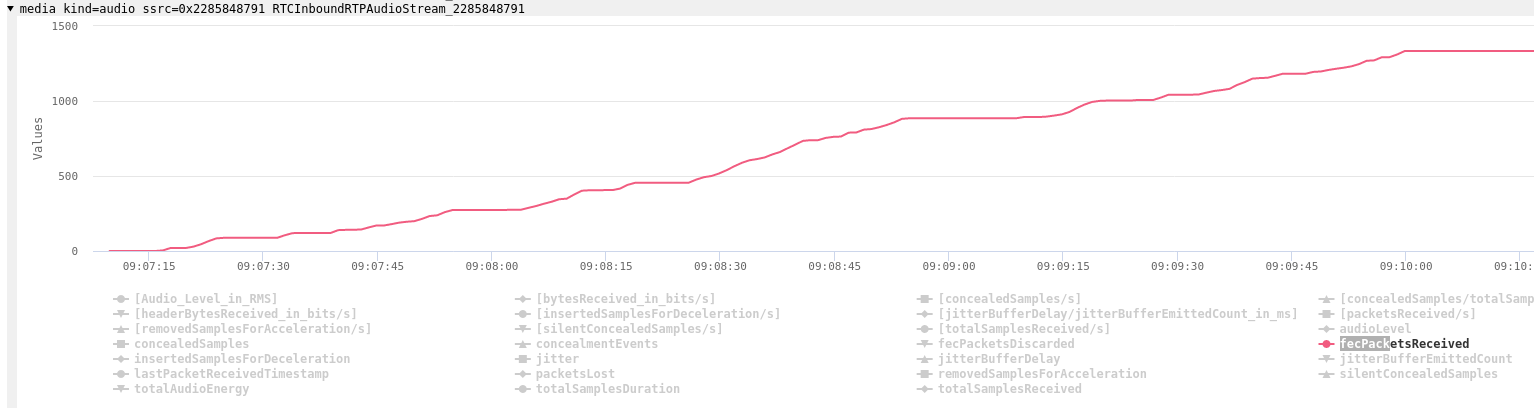
While Opus FEC is not as good as RED for redundancy, it does increase resilience in scenarios with low packet loss. Packet rate is lower than the usual 50 packets per second, but that is expected due to the larger frame size (40 and 60ms compared to 20ms; a larger frame size increases the delay but lowers the overhead). The incoming bitrate is about 50 kbps which is slightly higher than the outbound bandwidth of 30 kbps.
It seems like only one of the audio SSRCs is sending at a time, suggesting something like simulcast for audio:

We will check that in the RTP dump later.
We can see similar behavior for video:

The usual thing here would be simulcast but it is not what we see. In terms of resolution, we see three different ones, 192×192, 320×320, and 720×720. As the bandwidth estimate ramps up slowly, we move from the low-resolution stream (in the middle) to the mid-resolution (at the top) and end up with a nice and stable connection on the 720×720 layer, using about 750 kbps of bandwidth:

Commonly, this would be done using simulcast. The FaceTime developers seem to shy away from that but found a nice JavaScript level hack to make it work anyway.
We can see the same resolutions used for outbound streams as the inbound ones. The bitrates in the dumps seem a bit odd, suggesting no video was sent for quite some time during the call. Of course, as with any new setup, we ran into issues that might explain the behavior:
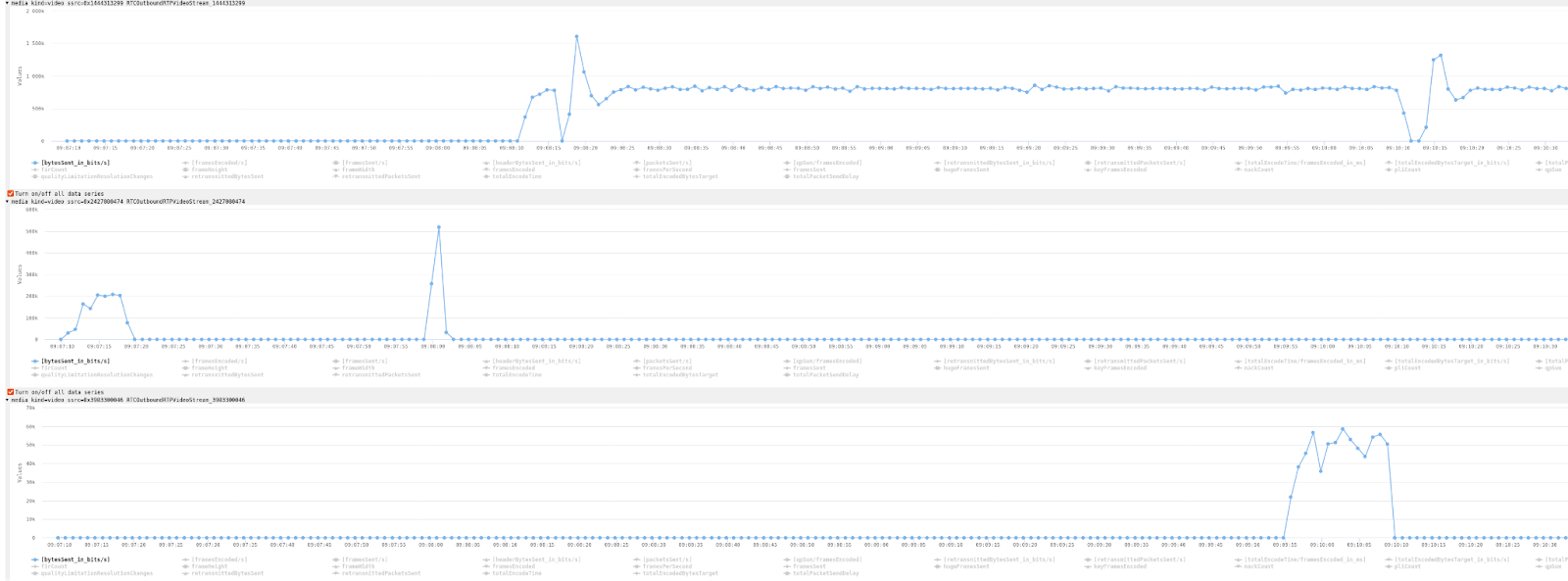
The target bitrates seem to be around 800 kbps for the high-resolution stream, 200 kbps for the 320×320 stream, and 60 kbps for the 192×192 thumbnail. This gets sent only during a specific phase of the call (when the third device joins?), but is then sent concurrently.
One of the functionalities that is missing from webrtc-internals is tracing of the RTCRtpSender.setParameters calls which would allow more insight into the advanced manipulations required to get such a behavior. Maybe someone will volunteer a patch.
With the statistics done, let’s move on to the JavaScript.
UPDATE 2021-06-15
There was another odd thing about the audio statistics. The audio ssrc 78925910 showed up in the statistics graphs twice, once as inbound
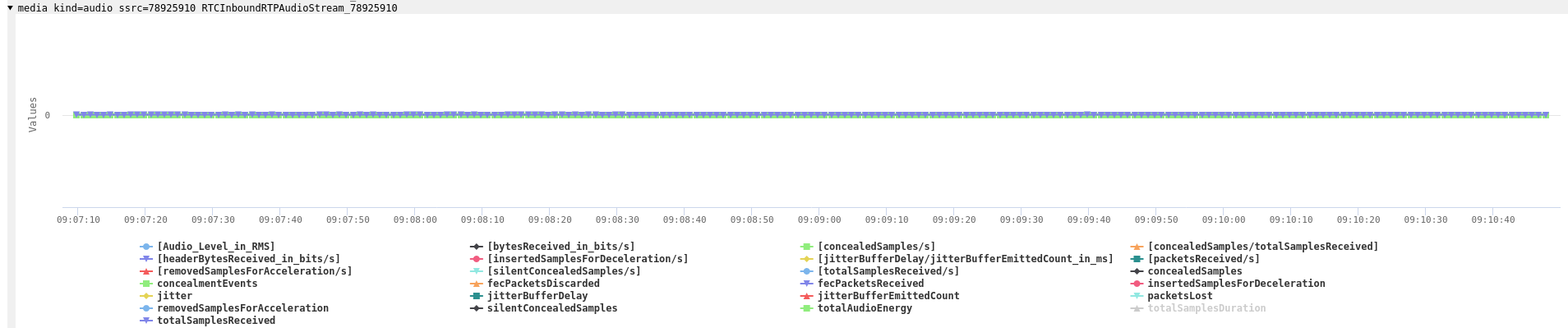
and also as outbound:
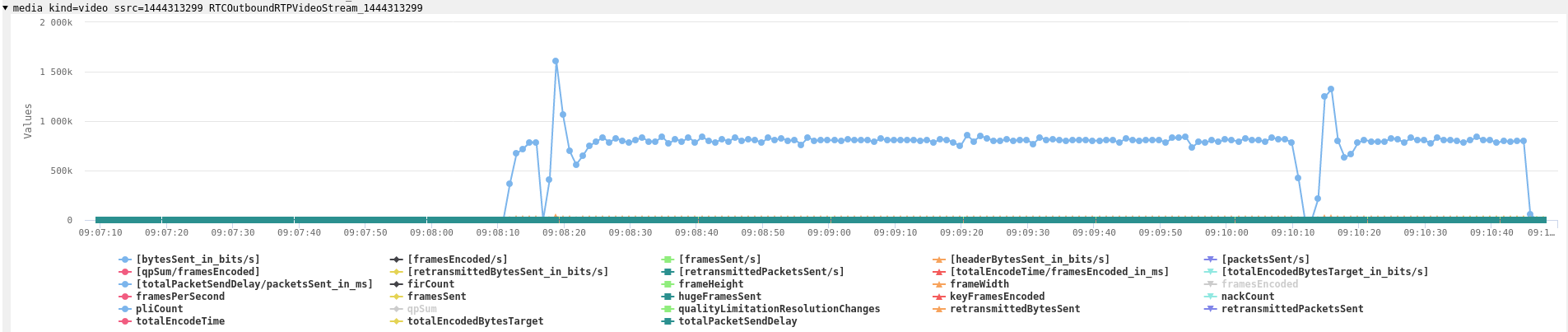
The RTP dump clearly shows that the server does not send any audio packets with this SSRC. It is generated by the browser when first calling createAnswer and setLocalDescription and subsequently used by the server in the setRemoteDescription calls. Technically that is a SSRC conflict and should be rejected by the browser. Also it doesn’t make sense so is another of those subtle errors.
The RTCP stats proved to show another two bugs:
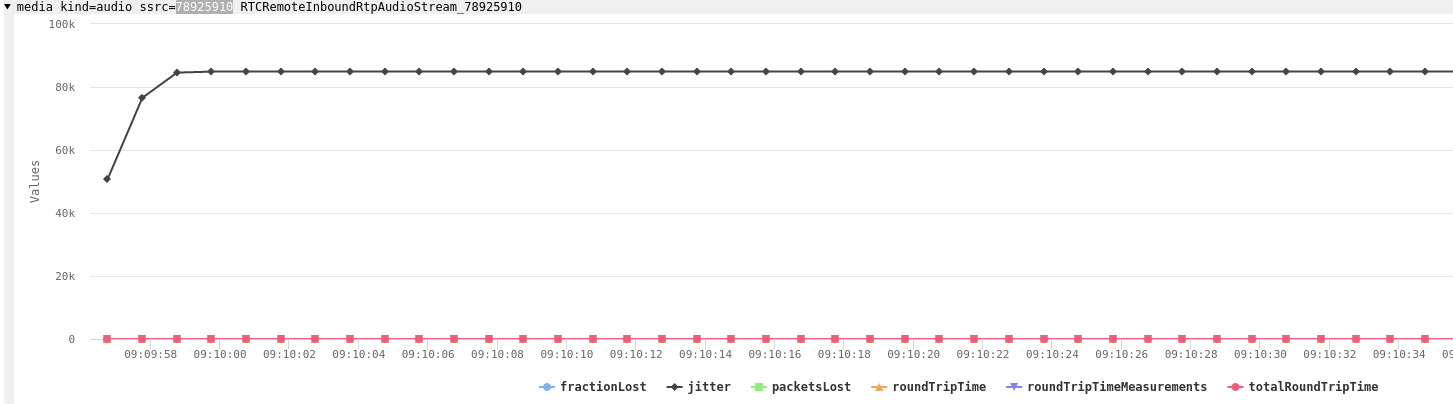
Such a high jitter value is quite unlikely as jitter is measured in seconds and anything above half a second means a terrible call quality.
The round trip time being consistently zero turned out to be another bug, the time-since-last-sender-report field in the RTCP receiver reports was set to zero.
The main JavaScript
We found the main Javascript here (the link might invalidate at some point).
The RTCPeerConnection constructor was relatively easy to find:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
this.rtcPeerConnection = new RTCPeerConnection({ rtcpMuxPolicy: "require", bundlePolicy: "max-bundle", encodedInsertableStreams: !0 }), this.dataChannel = new l.QRDataChannel(this.delegate,this, this.rtcPeerConnection.createDataChannel("0"),this.sessionDescription), this.midMap = new c.MIDMap, this.sdpModifyLock = new i.Mutex(!0), this.conversationSdpBuilder = new p.ConversationSDPBuilder, this.transceiverInfoMap = new Map, this.conversation = { us: (0, s.participantDescriptionForTiers)(this.participantId, [], []), them: [] }, this.unlisteners = [], this.ourActiveStreamIds = [], |
The naming of some of the variables around is quite insightful. The MIDMap shows that FaceTime is using the transceiver’s mid property to map tracks to participants, as suggested by Mozilla’s Jan-Ivar back in 2018.
Using a=msid lines and stream IDs are an easier way to manage this in my opinion.
The updateVideoTrack and updateAudioTrack methods show heavy use of the RTCRtpSender.setParameters API to enable and disable the different audio and video streams. Note the naming of “getAudioTierForStreamIndex”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
async updateAudioTrack(e, t) { var n, r; const [i] = null !== (r = null === (n = this.mediaStreamManager) || void 0 === n ? void 0 : n.getAudioTracks()) && void 0 !== r ? r : []; if (i && i.enabled && this.ourActiveStreamIds.includes(t.streamID)) { const n = (0, a.getAudioTierForStreamIndex)(t.streamIndex), r = e.sender.getParameters(); await e.sender.setParameters({ ...r, encodings: r.encodings.map(e => ({ ...e, maxBitrate: n.encodingBitrate, active: !0 })) }), await e.sender.replaceTrack(i) } else await e.sender.replaceTrack(null) } |
The SDP seems to be generated on the client-side in the conversationSDPBuilder object. The binary signaling is too small to contain the full unified plan SDP too.
The conversationSDPBuilder has some flags suggesting that the better transport-wide congestion control (or “twcc”) is being tested at least.
There is some SDP munging as well which is sad to see (even more so using regular expressions). It is rather limited:
|
1 2 3 4 5 |
_mungeSDP(e) { let t = e.replace(/ssrc-audio-level$/gm, "ssrc-audio-level vad=off"); return t = t.replace(/profile-level-id=42[0-9a-zA-Z]{4}$/gm, "profile-level-id=42e01f"), t } |
The first is non-standard and unnecessary to do before calling setLocalDescription with it.
Replacing whatever H.264 level was picked by Chrome with baseline should not be necessary either, if only baseline is desired, the profile-level-asymmetry should be removed from the server’s offer.
The ice candidate is statically created:
|
1 2 3 4 |
createCandidate(e) { const t = e.connectionParameters; return t ? `1 1 udp 1 ${t.serverIP} ${t.serverPort} typ host` : void 0 } |
As mentioned in the constraints section, only UDP is supported currently which is unlikely to work in enterprise environments as mentioned above. Dear FaceTime developer, would you mind not copying Chrome’s WebRTC bugs? The standard says it shall be uppercase “UDP”.
Searching for “createEncodedStreams” shows where the Insertable Streams API is being used. It attempts to use the newer version of the API but seems to work just fine with the current implementation in Chrome. It is also the reason for the lack of Firefox support which aims to implement the newer version of the specification as does Safari.
The worker and the end-to-end encryption it uses is our next stop.
The JavaScript Worker
As I said last year, using a worker for the encryption and decryption is quite nice as those are easy to find in the developers tools and typically very self-contained. That is the case here as well, the prettified version containing less than 1,750 lines.
The end-to-end encryption uses the SFrame scheme described in an IETF draft. That isn’t surprising given that one of the authors recently left Google to join Apple and work on FaceTime.
The lack of simulcast and how the insertable streams interact with each other in the decrypt function is interesting here. Whenever receiving a frame on an SSRC, a method notifyOnFirstRecentFrameReceived gets called:
|
1 2 3 4 5 6 |
async decrypt(e, t) { if (this.framesReceived++, void 0 === t && (t = this.ssrc), t !== this.ssrc && (this.ssrc = t, this.lastReceivedFrameTime = 0, this.lastDecryptedFrameTime = 0), void 0 === t) return new Error(`Receiver[${this.id}]: no ssrc for frame`); this.notifyOnFirstRecentFrameReceived(); const s = await this.receiver.decrypt(e, t); return s instanceof Error || (this.framesDecrypted++, this.lastDecryptedFrameTime = Date.now()), s; } |
Without tracing it back, I would speculate that this goes back to the main JavaScript and then chooses a video object to display depending on which poor-man’s-simulcast layer is used. This should work quite well without major glitches. That is quite a hack and I am looking forward to exploring that in a Javascript fiddle next month, the user experience is quite acceptable.
It does allow FaceTime to avoid the complexity of SSRC rewriting that SFUs have to do when dealing with simulcast.
Another interesting note here is that there is a known issue when using Insertable Streams with H.264. Unless one takes great care not to encrypt the NAL header, keyframe detection does not work. This is a known bug in the WebRTC library.
It can be avoided by not encrypting the first few bytes of the H.264 packet. Presumably, the server does that in this case which we can check in the RTP dump. When sending, this doesn’t matter much as this is merely a bug in the WebRTC library which the FaceTime server isn’t obliged to make the same mistake.
On to the packet dumps…
The SCTP dump
Chrome has long since provided the ability to do SCTP packet dumps after decrypting the datachannel packets. See the instructions in the sctp_transport code. This is quite useful so it was reimplemented in the new dcSCTP library that was just announced.
We could snoop on the datachannel messages exchanged that way but there are easier ways to do so by overriding the RTCDataChannel prototype and it doesn’t seem to be that interesting. What is interesting is one of the first packets:

The string KAME-BSD 1.1 stands out in the server’s response.
This suggests the server is using the usrsctp library which sets this as a version string.
Hopefully, the FaceTime team has taken note of the recent CVE-2021-30523 against it that was just updated in Chrome 91.
Last but not least, the RTP dump…
The RTP dump
The ability to dump RTP packets directly from Chrome without having to jump through the hoops shown in the video replay post had been on my wishlist for quite a while. At the end of 2020, I had an excuse to spend time on this and added the functionality to WebRTC.
In a nutshell, one has to start Chrome with --enable-logging --v=3 --force-fieldtrials=WebRTC-Debugging-RtpDump/Enabled and extract the RTP_PACKET lines in the log which can then be converted to a PCAP for easy inspection.
We can’t share those dumps because neither Dag-Inge nor I want to reveal what we talked about or looked like at that point 🙂
We will use this for two things:
- to check if only a single audio “stream” is sent by the server at a time
- look at the encrypted H264 frame
For audio this means we are going to filter the resulting dump for two ssrcs:
|
1 |
rtp.ssrc eq 1095248263 or rtp.ssrc eq 2285848791 |

What we see is that there is a short one-second overlap when both audio streams are received by the client. The RTP timestamp for both of them is the same for the first frame with payload type 97 which allows the client to switch seamlessly and drop “old” frames using Insertable Streams.
For the video packets, we can take a look at rtp.ssrc eq 3633224106 and configure Wireshark’s excellent H.264 dissector to decode the payload type 123 as H.264. This shows the usual sequence of a STAP-A NALU with SPS and PPS followed by a FU-A that spans three packets and contains an IDR (keyframe), followed by a single slice NALUs with pictures small enough to fit into a single UDP packet. The higher resolution stream uses FU-A NALUs to split the pictures. That shows the sending side is not encrypting the NAL header, working around the WebRTC bug mentioned earlier. Starting the RTP timestamp at zero instead of a random offset is a bit sloppy but we’ve all done that at some point.
If we look at the video sent by Chrome, e.g. rtp.ssrc eq 1444313299 we can see the H.264 structure is properly retained by the encryption function:
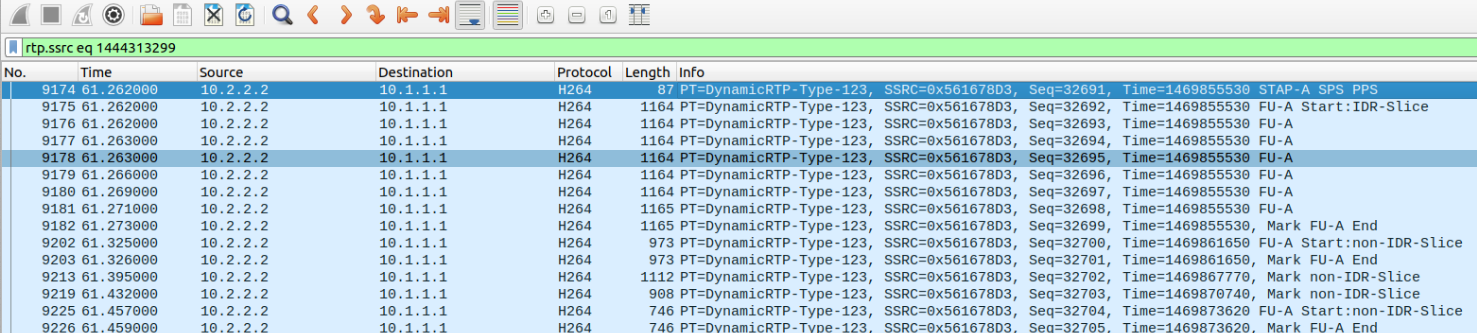
Easier to see at this level than in the slightly obfuscated Javascript 😉
REMB feedback from the server is quite notably absent in the first three minutes of the call, leading to a slow bandwidth ramp-up typically associated with pure loss-based congestion control.
The STUN messages obtained via Wireshark were pretty minimal so not to learn from these.
Summary
The FaceTime Web endpoint is using WebRTC and End-to-End encryption using Insertable streams. It also uses a pragmatic WebRTC hack enabled by that API to avoid using simulcast and rewriting synchronization sources in the server.
While I call this “poor man’s simulcast” it does seem to work and probably makes the server implementation considerably less complex. One notable gap in the implementation is relying on the older REMB bandwidth estimation rather than the newer transport-cc one but given some features in the JavaScript code that might change soon and simply did not make it in time.
The lack of TCP support is quite odd as it would make the use in enterprise scenarios quite difficult…
Using the open Opus audio codec together with end-to-end encryption raises the question of whether the native FaceTime client is now using it as well and if yes, in what scenarios. So far, FaceTime has been preferring codecs such as AAC-LD for that.
Limiting the video resolution to 720×720 does make sense on a mobile device with additional considerations like power consumptions and screen rotation but on the web, it seems a bit small.
Thank you Dag-Inge for helping with the dumps and as usual Tsahi and Chad for meticulous editing!
Special thanks to Gustavo Garcia who dared to make a bet on the simulcast technique and now owes me a beer.
{“author”: “Philipp Hancke“}




Great review.
Is AEAD_AES_256_GCM enabled in Safari? The issue is still open [1].
How can I test the effect of the urn:3gpp:video-orientation extension? I didn’t see a difference with or without it.
[1] https://bugs.webkit.org/show_bug.cgi?id=214402
IETF’s protocol police here. It is legal to insert setup=passive in the answer. This is commonly used, especially in combination with ICE-lite. The setup attribute value is generated based on the setup attribute value in the offer and the local preference. The language you refer to says that ClientHello MUST be sent towards the offerer if the answer has setup=active, not that setup=active must be sent.
Thanks Roman. The “passive” is set on the second offer — setting it on the answer is perfectly fine and widely used. Let me clarify that!
“The video constraints ask for the user-facing camera and an ideal width of 720 pixels. The height isn’t specific but for most cameras this will result in a 1280×720 pixel video stream being captured.”
You’ve mixed that up. It asks for an ideal height of 720. The width isn’t specified.
Fixed, thanks for catching that!