
A few days back my old friend Chris Koehncke, better known as “Kranky” asked me how hard it would be to implement a wild idea he had to monitor what percentage of the time you spent talking instead of listening on a call when using WebRTC. When I said “one day” that made him wonder whether he could offshore it to save money. Well… good luck!
A week later Kranky showed me some code. Wait, he is writing code? It was not bad – it was using the WebAudio API so going in the right direction. It was enough to prod me to finish writing the app for him.
The audio stream volume sample application from Google calculates the root mean square (RMS) of the audio signal which is extracted from the input stream using a script processor every 200ms. There is a lot of tuning options here of course.
Instead of starting from scratch, I decided to use hark, a small open source module for this task that my coworker Philip Roberts had built in mid-2013 when the WebAudio API became first available.
Instead of the RMS, hark uses the Fast Fourier Transformation to obtain a frequency domain representation of the input signal. Then, hark picks the maximum amplitude as an indication for the volume of the signal. Let’s try this (full code here):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var hark = require('../hark.js') var getUserMedia = require('getusermedia') getUserMedia(function(err, stream) { if (err) throw err var options = {}; var speechEvents = hark(stream, options); speechEvents.on('volume_change', function(volume) { console.log('current volume', volume); }); }); |
On top of this, hark uses a simple speech detection algorithm that considers speech to be started when the maximum amplitude stays above a threshold for a number of milliseconds. Much less complicated than typical voice activity detection algorithms but pretty effective. And easy to use as well, just subscribe to two additional events:
|
1 2 3 4 5 6 7 |
speechEvents.on('speaking', function() { console.log('speaking'); }); speechEvents.on('stopped_speaking', function() { console.log('stopped_speaking'); }); |
Tuning the threshold for accurate speech detection is pretty tricky. So I needed visualization (and just requiring hark only took five minutes so I had plenty of time). Using the awesome Highcharts graph library I quickly added plot bands to the graph I was generating:
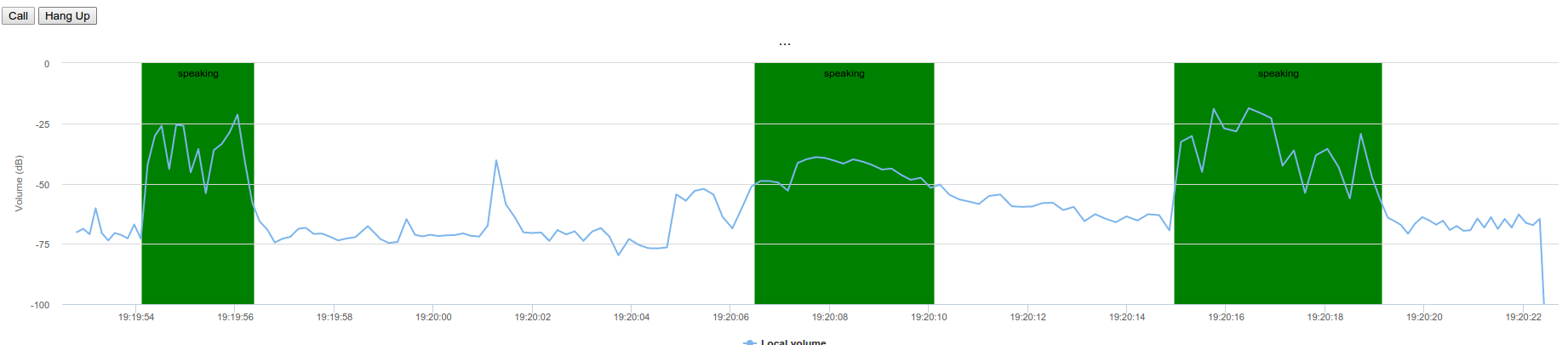
With the visualization I could easily see that the speech detection events happened a bit later than I expected since hark requires a certain history over the threshold for the trigger to work (say: 400ms). To adjust for this in the graph had to substract this speech starting to trigger time from my x-axis (now()– 400ms for example).
That graph is still visibile on the more techie variant of the website so if you think the results are not accurate… it might help you figure out what is going on. I am happy with the current behavior.
The percentage of speech then calculated as the sum of the intervals that speech is detected divided by the duration of the call. As a display, a gauge chart is used with three different colors:
- up to 65% speech time: green
- up to 79%: yellow
- more than 80%: red
Adding remote audio to this would be awesome. However, while the WebAudio API is supported for local media streams in Chrome, Firefox and Edge, it is only supported for remote streams in Firefox. Hooking this up with the getStats API (in Chrome) to get the audio level would certainly be possible, but would require calling getStats at a very high frequency to get proper averages.
Check out the app in action at talklessnow and let us know what you think.
{“author”: “Philipp Hancke“}




how i can do this in native api?