Every year I typically catch up with many of the WebRTC standards people at the IIT-RTC Conference. The pandemic obviously made this year different. Bernard Aboba represented Edge at this year’s WebRTC Browsers Update Roundtable at Kranky Geek (and he has been a frequent Edge WebRTC spokesperson here too). Bernard is also co-chair of the WEBRTC Working Group in the W3C. While we did touch on standardization and the “Future of WebRTC” a bit in the Kranky Geek sessions this year, we did not have time to dig into much detail so we will do that here.
Bernard has a long and distinguished career in Real Time Communications. In addition to his W3C WebRTC co-chair role, he is also Co-Chair of the WEBTRANS and AVTCORE working groups there and an editor of the ORTC, WebRTC-SVC, WebRTC-NV Use Cases, WebRTC-ICE, WebTransport and WebRTC-QUIC documents. Don’t forget that WebRTC is also partly standardized in the IETF where Bernard is also Co-Chair of the WEBTRANS and AVTCORE WGs. At Microsoft he is a principal architect in the Microsoft Teams media organization in a group called IC3 which supports Microsoft Teams and other projects based on the Teams infrastructure such as Azure Communications Service (Gustavo posted about that here).
The below text is edited for clarity and context. This was a long interview that covered many topiccs. You can skip to specific parts using the links below:
- WebRTC Standardization Status
- WebRTC Extensions
- getCurrentBrowsingContextMedia
- WebRTC NV
- WebTransport
- Simulcast
- Scalable Video Coding
- AV1
- Insertable Streams & SFrame
- WebCodecs
- Does WebRTC have a future in the face of these alternatives?
- Machine Learning
- What now?
If you prefer, you can listen to the original, unedited audio version below or download here:
Bernard also provided some text edits with additional links and commentary that I could not fit in. Here is that text .
{“editor”, “chad hart“}

WebRTC Standardization Status
As one of the chairs of the W3C’s WebRTC Working Group, Bernard is an authoritative figure in the WebRTC standardization process. I started by asking him about the Working Group’s current charter.
Bernard: As discussed in the April 2020 presentation to W3C, the WebRTC Working Group charter describes work in three areas:
- Finishing WebRTC Peer Connection (WebRTC-PC) which is first priority, along with related specifications such as WebRTC-Stats.
- Capture, Streams and Output-related specifications, including Media Capture and Streams, Screen Capture, Media Capture from DOM Elements, MediaStream Image Capture, MediaStream Recording, Audio Output Devices and Content-Hints.
- WebRTC-NV, the “Next Version” of WebRTC.
WebRTC-NV is the “Next Version” of WebRTC. It’s what comes after the current 1.0 specification.
Bernard: WebRTC-NV work falls in four major categories.
- One category is extensions to WebRTC PeerConnection. This includes WebRTC Extensions, WebRTC-SVC, and Insertable Streams. I should mention that the WebRTC Proposed Recommendation and all work depending on
RTCPeerConnectionrequire “Unified Plan” which is now the default SDP dialect in all browsers. So, for example, it is not possible to take advantage of Insertable Streams to support End-to-End Encryption within your application without first supporting “Unified Plan”.- A second category involves features which did not meet the implementation or maturity requirements for inclusion in the WebRTC-PC Proposed Recommendation , such as WebRTC Identity, WebRTC Priority Control and WebRTC DSCP.
- A third category is extensions to Capture, such as MediaStreamTrack Insertable Streams, Media Capture and Streams Extensions and MediaCapture Depth Stream Extensions (recently revived).
- The fourth category is what I would call standalone specifications, which are not necessarily dependent on either
RTCPeerConnectionor the existing Media Capture specifications. WebRTC-ICE (which so far has been implemented as a standalone specification) fits into this category, as do API specifications developed outside the W3C WEBRTC WG such as WebTransport (in the W3C WebTransport WG), WebRTC-QUIC (in the ORTC CG) and WebCodecs (in the WICG).Given the different categories of work, the term “NV” is somewhat vague and possibly confusing. The term originally referred to ORTC, but today it typically refers to multiple specifications, not a single document. Within the current usage, there is ambiguity, because “NV” may refer to extensions to
RTCPeerConnectionand existing Capture APIs, or to APIs that aren’t related toRTCPeerConnectionor existing Capture APIs, such as WebTransport and WebCodecs. So when someone mentions “WebRTC-NV” it is often necessary to ask follow-up questions to understand which one of the potential meanings they intend.
The path to being a full Recommendation
The protocols used in WebRTC are defined by the IETF while the W3C defines the APIs used by browsers. The road to formal standardization by the W3C – and arguments on what that should include – has at times been a contentious topic.
Bernard gives some background and status on this process.
Chad: Could you just walk our audience through the W3C specification stages?
Bernard: The first standardization stage is CR – Candidate Recommendation. Candidate Recommendation means that the specification has been widely reviewed, has met WG requirements and is implementable. At CR, the specification may not have been completely implemented (there may be “features at risk”) and there may be interoperability issues between browsers.
You can see the full process details described here.
Chad: When you say the last CR, I guess the implication there is that there can be multiple CRs or that the CR process is a multi-stage thing?
Bernard: And also there’s a new W3C process where essentially you have live specifications. Let’s just say we’re at the last one before we’re about to file for a proposed recommendation on both of those things.
So PR [Proposed Recommendation] is the stage at which you try to demonstrate that everything in the spec has been implemented and that it also passes your interoperability bar. And then there’s Recommendation, which is even beyond that. The next step is PR and we’re amassing all of the data that you need for that. In the case of Peer Connection, it’s a lot of data because you need all of your interop tests, which consists of your WPT test results, but also potentially your KITE test results.

WPT refers to web-platform-tests which is a set of tests for checking API implementation by the W3C. The results are located at https://wpt.fyi.
KITE is an open source, interoperability testing project specific to WebRTC. Dr. Alex Gouaillard discusses that a bit in his webrtcHacks post – Breaking Point: WebRTC SFU Load Testing.
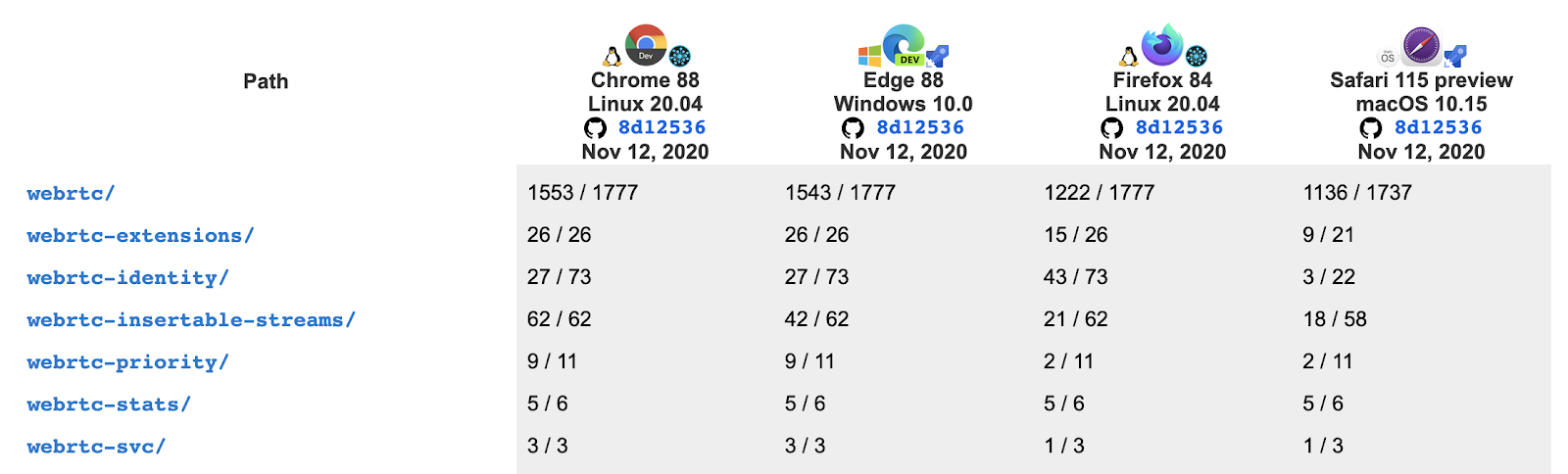
Chad: WPT being the wpt.fyi, which is the general kind of automated feature tests, and KITE being the WebRTC specific interop tests..
Bernard: The WebRTC WPT tests run on a single browser. We don’t have server tests in WPT for WebRTC, but there are server tests for things like WebTransport. So the WebRTC WPT tests don’t demonstrate interoperability between browsers or between a browser and a conference server, whereas the KITE tests are between a browser and potentially multiple entities.
Chad: And that is WebRTC specific – you are actually sending media to a different browser.
Bernard: To understand the level of WPT test coverage, we have annotated the specification. So beyond the test results, you also want to know how much of the specification is actually covered by tests.
Standards efforts slowed by the pandemic
WebRTC has had some interesting impacts for WebRTC. It has mostly made all of us in the WebRTC community incredibly busy with a greater focus on scaling and reliability with all the new traffic. However, this change in focus can be very disruptive to existing processes. Does that apply to standardization efforts too?
Bernard: The bottom line is we’re trying to amass all of this evidence that we are going to present to the W3C to claim that we are ready for the proposed recommendation stage. That is a very big step, but progress has been slowed by the virus. I mean, we thought we would get further along in the implementation process, but the virus has slowed everybody down.
Chad: Is that because people are busy doing things to support their products or is it because actually you couldn’t get together as frequently?
Bernard: The pandemic has upset a lot of things. For example, the KITE interop tests were often done in person at the IETF events but we haven’t been able to have an in-person IETF. We’ve been trying to scramble to figure out how we can get the tests done, but that it’s difficult without having everyone in the same place. The ability to organize everybody at the same place and same time if you’re all over the world is really hard. Imagine it’s 3AM in the morning for you and you need to do an interoperability test with someone on the other side of the world in a different time zone.
The virus has not only disrupted testing, but has also impacted implementation schedules, as reflected in the confluence maps. While almost all features in the Proposed Recommendation have been implemented in at least one browser, we originally believed we would have more features implemented across two or more browser code bases by Fall of 2020. So both implementation progress and testing is not where we expected to be.
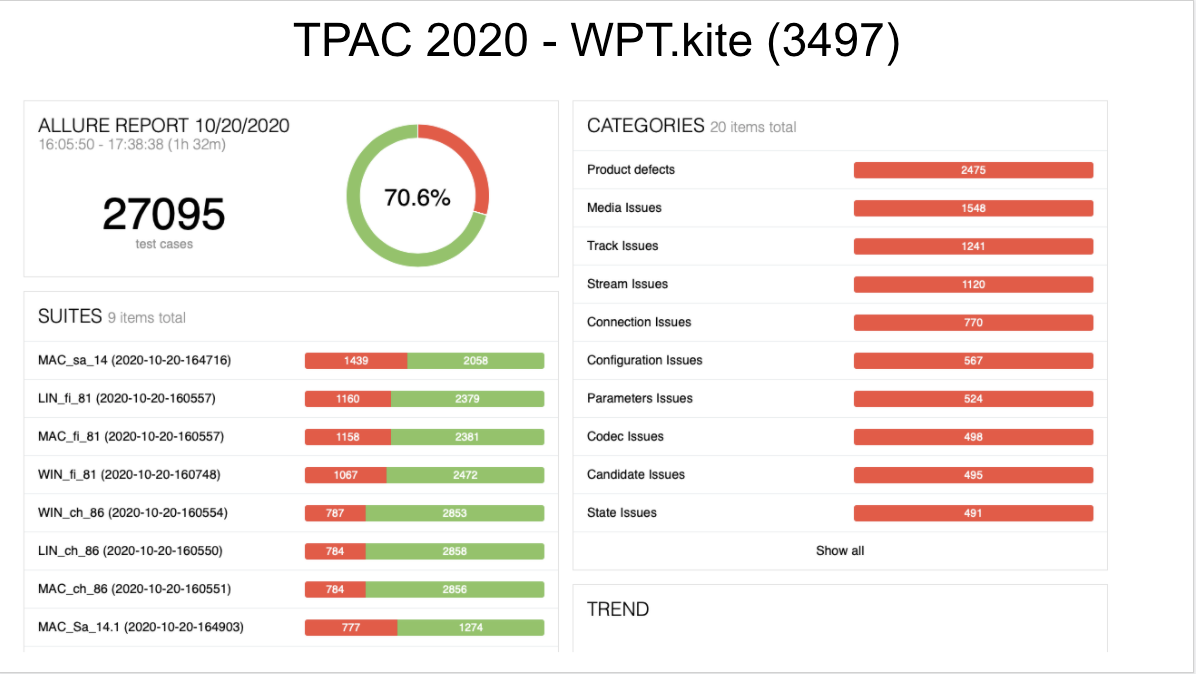
How much does standardization matter?
WebRTC is implemented in pretty much every web browser that’s had an update in the past few years. WebRTC is supporting a significant portion of the world’s voice over IP (VoIP) traffic. Does getting to the next stage of standardization even matter at this point?
Bernard points out standardization is more than writing specs – it is really about interoperability.
Bernard: Standardization focuses the mind on testing and stability. One of the biggest challenges of WebRTC Peer Connection is just the sheer breadth of it. We learn every day just from bugs that slip through – important bugs. We find our coverage is not where we’d ideally like it to be. And we also learn how difficult it is to have even what I would call acceptable test coverage. There’ve been a bunch of recent bugs to things like multiplexing that actually have a major impact on existing services and we didn’t have tests for them. What we see in a lot of these bugs is they’re not the kind of things that get picked up by WPT. They are things that inherently you need something like a KITE framework to do and we’re not close to a hundred percent test coverage in KITE.
I would say overall that one of the biggest differences that I’ve experienced in Real Time Communications versus other aspects of networking is the enormous size of test matrices. To even conceive of if I told you Chad, that I wanted to assign you to develop, get the 95% coverage. I think the process of going through testing is helpful, but it’s also made us appreciate the size of the challenge to really get everything covered. It’s very hard.
WebRTC Extensions
The list of things you could do with WebRTC keeps getting longer. As Bernard just mentioned, WebRTC 1.0 is progressing through the standards process so they have to draw a line on adding new features somewhere. As Bernard will explain, WebRTC Extensions is a home for some of the features that didn’t make it into WebRTC 1.0.
Bernard: There are a series of specifications that depend on the
RTCPeerConnection. WebRTC extensions is one of these. These are specifications that add functionality to WebRTC PC. And there’s a number of things in there for example, RTP header extension encryption. WebRTC SVC – Scalable Video Coding – is not in the WebRTC extensions document, but I consider it an extension. I would consider insertable streams to be an extension to WebRTC PC, the encoded version of it. These are all things that assume you haveRTCPeerConnection.
getCurrentBrowsingContextMedia
With the increased use of video conferencing, there have been several high profile stories about webcam’s gone wrong and accidental screen sharing. At the same time, rapid webcam access is often an issue for WebRTC services. Balancing speed of access with privacy controls is a hard problem. In addition, use of media device information provided by getMediaDevices for fingerprinting purposes has been an on-going privacy challenge.
The getCurrentBrowsingContextMedia proposal is one attempt to address some of these challenges.
Chad: Can we cover the
getCurrentBrowsingContextMediamedia proposal?Bernard: That is really an extension, I consider that an extension to screen capture. Let me just talk about the issues with [media] capture – a lot of the focus on capture has been on privacy and security. We’ve discovered that the media capturing streams isn’t really very good for privacy. The assumption there was that you would give the application all the information on devices, whether they were selected or not, then let it create its own picker. Well, that’s a real problem for fingerprinting because now I know all the devices that are on your machine. Even though you don’t want to use that camera, I know it’s there. So it really helps fingerprint you and Jan-Ivar has been proposing that we move to another model which is much more similar to screen capture.
In screen capture you only get access to the capture surfaces that the user selects. So it’s not like I get access to all your apps and I can see every window and then I get to decide as an application to buy what I want to look at. Now the user selects the source and you only get access to that. That’s the model that Jan-Ivar is proposing for media capture and streams. Essentially it would become part of a browser picker. The app would only get access to info on the device that the user selects. That is a big change though. It also brings into question some of the basics of media capture and screams. For example, what’s the purpose of constraints if the user’s just going to choose anyway?
Chad: Would that imply then more specifications around the device picker?
Bernard: Well, I think what it does is. However, we’ve decided that we’re going to advance the existing spec more or less than the model we have. Then Jan-Ivar is creating a separate spec for this new model that works through all of those issues. The tricky thing here is, it is a very different model. How do you transition that new model when people are used to the application pickers? It will probably take a very long time.

WebRTC NV
One consequence of battles within the standards was a reluctance to specify formal version names since everyone had different opinions on what constitutes a major release (i.e. 1.0, 2.0) vs. a minor one (i.e. 1.1, 1.2, etc.). There was also once an alternative recommendation called ORTC that was sometimes positioned as a WebRTC successor that we will discuss in a big. WebRTC 1.0 has coalesced around the current spec we discussed. Still, there was a lot of debate on what comes next. They eventually settled on naming everything that comes next with the very bland, imprecise term: “WebRTC Next Version” or WebRTC-NV.
Bernard explains what this means.
Chad: We talked a little about what we’ll see in the “next version” of WebRTC – I guess we’re not calling that 2.0 because 1.0 is not done?
Bernard: I think maybe it’s time we think of sunsetting that whole NV term because it really can refer to two potentially very different things. One is the as I mentioned the extensions to Peer Connection – things like insertable streams, WebRTC extensions, WebRTC SVC. The way I think about that is when you take all those specs together they add up to the same level of functionality that ORTC had. So we’ve already incorporated most of the ORTC object model in the WebRTC PC.
The other very separate track is what I call a standalone specs. That includes things like WebTransport, WebCodecs, WebRTC ICE – these are things that are completely separate and do not depend on
RTCPeerConnection. So that is really a next generation kind of break with the present.Still pretty early, obviously. WebTransport is an origin trial. WebCodecs is an origin trial in Chrome. Now this is very different because many of the things that you used to get as part of the monolithic WebRTC PC, you now have to write yourself in Web Assembly. So it’s a very, very different model of development.
There are pieces that are not there. For example, WebTransport is inherently client-server today. There is a peer-to-peer extension that we’ve written and there was an origin trial of that a while back, but currently it’s client server. So you cannot write the full range of WebRTC PC use cases with just WebCodecs and WebTransport as it exists.
I would say that the other thing that’s happened in WebRTC NV, which has become very important, is people have had a real focus on Machine Learning and access to raw media. This is something that ORTC did not provide. And in a sense, what I would say is that the WebTransport or WebCodecs model is even lower level in that respect than ORTC was. ORTC didn’t give you direct access to decoders and encoders. That’s what you’d get from WebCodecs. So I think we’ve taken the ORTC ideas and we’ve taken it even lower into transport.
We’ll talk about the intersection of ML and WebRTC in a moment, but first let’s check-in on ORTC.
What happened with ORTC?
Object RTC (ORTC) was an alternative model for WebRTC that provided low-level controls without the use of SDP. Bernard was one of its authors and Microsoft launched the original Edge with support for ORTC. We don’t hear much about ORTC anymore, so what happened to it? As Bernard explained a moment ago, much of it got sucked into the core WebRTC standard. Was this a defeat for the ORTC vision or a win?
Chad: You were one of the authors of the original ORTC spec. How would you compare where we are today versus your original ORTC vision?
Bernard: The object model is fully there in the Chromium browser. So we have almost all the objects from ORTC – Ice Transport, DTLS Transport, SCTP Transport from the data channel – all of those objects are now in WebRTC PC and the Chromium browser.
ORTC also had advanced functionality like simulcast and SVC that we have incorporated. Plus we have more than the original ORTC through end to end encryption which can be supported through insertable streams. So we’ve made WebRTC PC equivalent to ORTC with the object model and all of these extensions.
The kind of scenarios that we were looking forward to were things like the Internet of Things that were just focused on data transfer. You can see that’s reflected in the WebRTC and the use cases – those scenarios are there like peer to peer data exchange.
WebTransport
WebTransport is another W3C specification with its own Working Group and spec. You’ll see mostly familiar names from WebRTC involved there, including Bernard.
QUIC is an improved transport protocol – kind of like a “TCP/2” that can be used by WebTransport.
So what is WebTransport , where did it come from, and what does it have to do with WebRTC?
Bernard: WebTransport is both an API, which is in the W3C WebTransport group. It is also a series of protocols – a series of transports – which is in the IETF. The protocols include WebTransport over QUIC which has been called QUIC Transport and also WebTransport over HTTP/3 and potentially HTTP/2. So the WebTransport API that’s in W3C is only for QUIC and HTTP/3. HTTP/2 is considered a fail over transport, which would potentially have a separate API.
That API is a client server API. The constructors and everything resembles WebSockets quite a bit. In the constructor WebTransport constructor, you give it a URL and you’d get back a WebTransport. It is different though in the sense that you can create both reliable streams and datagrams.
Datagrams, like what is used in UDP for fast, but unreliable delivery.
Bernard: And it is bi-directional in the sense that once the WebTransport is initiated by the client, but once that connection is up, the server can initiate either a unidirectional bi-directional stream to the client and datagrams can flow back and forth.
Bidirectional – so like a websocket?
Bernard: Well, WebSocket is really only client side. WebSocket can’t be initiated by a server but a WebTransport can. In WebTransport over QUIC the connection is not pooled. In WebTransport for HTTP/3 it can be pooled – that creates a bunch of very interesting scenarios, some of which recovered an IETF BoFs. The way to think about it is you can be doing both HTTP/3 request-response and WebTransport, including streams, and datagrams over the same QIUC connection.
There was a scenario that Justin Uberti put together for what was called a RIPT BOF at IETF that kind of blew people’s minds. In that scenario, you had an RPC back and forth – request-response but RPC – that resulted in a stream from the server to the client. So think of it as a client saying, I want to play this movie or get into this game or get into this video conference, and then a stream which could be potentially a reliable, QUIC stream, or potentially a flow of datagrams comes from the server as a result of that.
I think WebTransport has the potential to bring revolutionary changes to the web. HTTP/3 itself is a revolutionary change to the web. Much of that revolution is in the more complex version, which is the HTTP/3 pooled transport. The QUIC transport is a lot simpler, it just gives me a socket and I’ll send stuff back and forth over it.
How far along is WebTransport?
Bernard: I’d say the WebTransport API is fairly polished now, and it’s just completing its origin trial, which is ending with M88. There are a few bugs, some things that don’t quite work right, but the API is relatively polished. You can write a fairly sophisticated sample code with it. I think it’s in we’ve got the spec up to date with the actual code. So if you read this spec, you can actually do this stuff in code. Hopefully we’ll put a complete example in there very soon and you can try it out.
On the server side there still are some QUIC interop issues. So I think the server that people are using is aioquic, the Python library, you can also use quiche as a server, but it isn’t as integrated into a framework. Unfortunately we do not have a Node.JS server, which would be really nice to have – that’s probably pretty far away.
As Bernard mentioned, WebTransport is client-server, not peer-to-peer (P2P) like WebRTC. However, we have seen a preview of P2P QUIC already. In fact, Fippo wrote a post on QUIC DataChannels back in February 2019. How does that compare to this new WebTransport approach?
Bernard: that was in the ORTC style. It didn’t support WHATWG/W3C streams, it was also based on the gQUIC protocol, not IETF’s QUIC. WebTransport – with the code that’s in Chrome – is based on what WHATWG streams and it is also based on IETF QUIC. So that
RTCQuicTransportcode was very outmoded because it was both an older API and an older protocol. That code has been removed from Chromium.
So how do we get to Peer-to-Peer WebTransport for low latency scenarios?
Bernard: We have a little extension spec, which is still in the ORTC CG. Basically think of it as just WebTransport, but you have it run over
RTCIceTransportinstead of over a URL. So to do the construction, you don’t give it a URL, you give it an ICE transport.
That’s how you construct it. There’s little ORTC things that are basically taken from theRTCDtlsTransportthat you add to do the peer to peer stuff. But the extension spec is only a couple of pages. It’s very, very small, like 95% of the WebTransport spec is exactly the same.Chad: Has anyone built that out?
Bernard: We haven’t got a working version with the new API and the new QUIC library. There isn’t a version with the new stuff. One of the features of
RTCQuicTransportwas that it was standalone. There is code there in Chromium today called WebRTC ICE. Think of the ICE transport from WebRTC PC – This is a standalone RTC version of this. When you construct anRTCQuicTransportfrom anRTCIceTransport, it is not multiplexed with your peer connection stuff.It’s on a separate port. Now we had to do that in the case of
RTCQuicTransportin the old days, because gQUIC could not be multiplexed with RTP/RTCP STUN and TURN. IETF QUIC can be multiplexed.
gQUIC being the original version of QUIC from Google.
This sounds like it could have a big impact on IP port usage and bundling help limit port usage and get through firewalls.
Bernard: Would developers want to use QUIC along on the same port as all of their other audio and video stuff? Today in WebRTC PC, bundling is very, very popular. Everybody pushes everything together on the same port – it’s well over 99% of all use of WebRTC. One might think that the QUIC would have a similar demand. If that’s what they really want, we don’t want to construct [
RTCQuicTransport] from a ORTC stylized transport; you want to be able to construct it from a WebRTC PC ICE Transport.This gets a little weird because now you’re saying parts of WebTransport depend on
RTCPeerConnection.

Simulcast
WebTransport looks to be a whole new potential way of doing things coming down the road. However, what about some of the thornier issues plaguing WebRTC implementations today, like simulcast for example? Simulcast is used in nearly every major WebRTC video conferencing service with more than a few participants and has long struggled with standardization and interop.
Chad: How are things doing the Simulcasts?
Bernard: It is in there. The claim is that in Chromium that all codecs are supported [with simulcast] – or at least all the codecs that are in there now. So in theory, you should be able to do it with H.264, VP8 and VP9.
We keep finding bugs. We had some really horrendous bugs where for example, H264, wasn’t working. We had the full KITE test, but we needed a simple loop back test where we can test basic operations where you can send simulcasts to yourself. So finally Fippo wrote a loopback test.
If you want to see that test, Fippo’s “simulcast playground” post is here.
Bernard: That test did not pass on all browsers. And the reason it didn’t pass was because you sent RIDs, fooled around with the SDP, and received them as MID. So you essentially, if you sent three streams, you would get the three streams back but they’d each be on a different MID.
Firefox didn’t support the MID RTP header extension. So that actually that loop back test did not work.
One of the things we discovered, whenever you write tests, you will find something that’s not quite there.
I’ll give you another weird little example – we’ve been doing some work on hardware acceleration. It turns out that when you use hardware accelerators, you can get different bitstreams. It doesn’t just make things faster, it actually changes the codec’s bitstream and then you can actually start breaking interop. You do a Simulcast test and suddenly your SFU can’t handle what’s coming in anymore. I really wish that we were able to meet in person at one of these IETF meetings to do another Simulcast tests, like what Dr. Alex was able to do and see where we are.
One way you would know that we were fine is if everyone was shipping Unified Plan.
Unified Plan being the new, standardized SDP format that among many other things, specifies how simulcast streams should be handled in SDP. Wasn’t Unified Plan supposed to be the spec that saves the day? Where are we on that?
Bernard: If everyone was using Unified Plan with all the codecs – and [the interop tests] were all happy then you would know that everything works. We are not anywhere near there yet. Let me put it this way – we are feature complete. I think that’s true, but things keep slipping through the test coverage. I wouldn’t say that every browser has all the features necessary to ship commercial apps. Like, for example, I think it’s true that a number of commercial apps ship on multiple browsers, but I think there are very, very few that ship on all browsers.
So one way to think of this, which might be a little easier than all these test results is if you did a matrix with all the major conferencing services and all the browsers they run on and all the different modes, that would give you probably the best look at where we are in fact.
That’s not very encouraging after all this time. It is good that most services support most browsers, but you do often see varied feature support and slightly different experiences across browsers.

Scalable Video Coding
Scalable Video Coding (SVC) is arguably a better way of handling multiple media streams from the same sender to handle varying conditions at each receiver in group calls. In many ways it is also considered more complex. Sergio & Gustavo have a great post on this topic.
If simulcast is not there yet, where does that leave us with SVC?
Bernard: SVC in some ways is a little bit easier than Simulcast. It is in Chromium today as an experimental implementation for temporal scalability. In plan B, there is also support for temporal scalability as well – so this is actually out there and there are conferencing servers that support it. So this is actually in some ways an easier advance for most conferencing services then for example, supporting both RID and MID.
MID being the SDP media identifier (see this our SDP Anatomy) and RID being the newer restriction identifier for limiting individual streams. I’ll leave it to the reader to look at the various SDP specs for more information on those.
A number of conferencing services do support both RID and MID I think – Medooze does, Janus does. One of the things about SVC to understand is that in both VP8 and VP9 it’s required – the decoder must support this. So there’s nothing to negotiate. The encoder can put it out. The SFU doesn’t even have to drop stuff [SVC layers] if it doesn’t want to, but that’s obviously better.
AV1
Long ago Chris Wendt wrote a post here about the codec wars between H.26X and VPX camps and the potential for one codec to rule them all. Today that codec exists and it is called AV1.
When will we get AV1 as a standard in WebRTC?

Bernard: The challenge [with AV1] is to try to figure out how to make it useful and usable before a large swath of devices can support encoding at full resolution.
Chad: I should have explained for the audience that AV1 is the next generation, open source, free codec.
Bernard: AV1 doesn’t require any changes to WebRTC PeerConnection per se. But as an example AV1 supports a lot of new scalability modes. So you want that control, which is where WebRTC SVC comes in.
The other thing is AV1 has a very efficient screen content coding tool and you want to be able to turn that on. So we added something called content hints that could cause that AV1 content coder tool to be turned on.
Florent [Castelli] has proposed a mixed-codec simulcast. And the idea of this is that you could have AV1 encoded at a low bit rate, for example, if you wanted to do 360P or 720P or something and you had the machine that could do it, fine. You could do that in software. You don’t need hardware acceleration for that. Then at the higher resolutions, you would use another codec. So you might use VP8 or VP9 for example.
That would allow you to introduce AV1 encoding right away without forcing it to be all or nothing. With mixed-codec simulcast and content hints basically as soon as AV1 encoder and decoder gets into WebRTC PC, it could be usable right away. I think people are not thinking much about AV1, but with these extensions – little tweaks to the API – our goal is to make it usable immediately.
We’re not that far away right now. Dr. Alex is writing the test suite. The encoder and decoder libraries are out there, so that’s not particularly complicated. Neither is the RTP encapsulation particularly complex – it’s very, very simple.
So what makes it hard?
Bernard: The trick is in what we call the dependency descriptor header extension, which is what the SFU uses to forward. That is the tricky part of it is building support into the conferencing server. The other part is that AV1 is inherently built to allow end-to-end encryption [e2ee], which is where insertable streams come in.
AV1 as a codec isn’t actually that big of a difference in terms of the [codec]. I think of it as the next in the lineage of VP8 VP9. and AV1. it has some H.264 kind of MAL unit semantics, so it’s a little bit like a cross between H.264 and VP9.
But from the point of the overall model of usage from the conferencing server, it’s very unique because you have this end-to-end encryption, you are not supposed to, for example, parse the AV1 OBU’s. The SFU should be making a forward decision purely based on the dependency to description to allow for end to end encryption. So with that essentially you’ve brought yourself to the next model where potentially an SFU can now be codec independent.
Insertable Streams & SFrame
One topic loosely related to codec independence and directly related to end-to-end encryption (e2ee) is insertable streams. In fact, we have had a post on that topic and Emil Ivov went into depth on e2ee at Kranky Geek a couple weeks ago.
I’ll let Berard talk about where we are at with the Insertable Streams API.

Bernard: End-to-end encryption is not just a simple use case. Insertable streams is really the idea was In the Insertable streams API model a way to think about it is you get access to a frame. You can do things to the frame, but you do not get access to the RTP headers or the RTP header extensions or anything like that. You are not supposed to dramatically change the size of the frame. So you can’t add for example, large amounts of metadata to it. You’re supposed to operate on the frame and then essentially give it back to the packetizer that then packetizes it into RTP and sends it out. So it’s somewhat linked to RTP.
There are other APIs that are being developed that also operate on the same idea of giving you a video frame. The more prominent of these is WebCodecs as well as insertable streams for raw media. The way to think about that is an extension to media stream track because Insertable streams, raw media does not depend on
RTCPeerConnection, whereas insertable streams and coded media does. In all of these APIs, you get access to a video frame either a raw frame or an encoded one, and you can then do things to it and then essentially give it back. In the case of Insertable Streams it gets packetized and sent over the wire.There are some tricky aspects to it. There were some bugs that have been filed. It works with VP8 and VP9 today. It does not work with H264 and I’m not sure it can’t be made to work with it, but we have a bug that we’re still dealing with there.
The idea here also that’s important is that we are not attempting to tell the developer how to do their encryption or what key management scheme to use. We’re developing standards for the format of the end to end encryption, that is SFrame and there’s IETF standardization work to be done there. What we don’t have yet is full agreement on the key management scheme. It turns out there are multiple scenarios that will probably require different key management.
Secure Frame or SFrame is a newer proposal for allowing end-to-end media through a SFU by encrypting an entire media frame, as opposed to encrypting individual packets. Since you can have multiple packets per frame, this can operate much more efficiently.
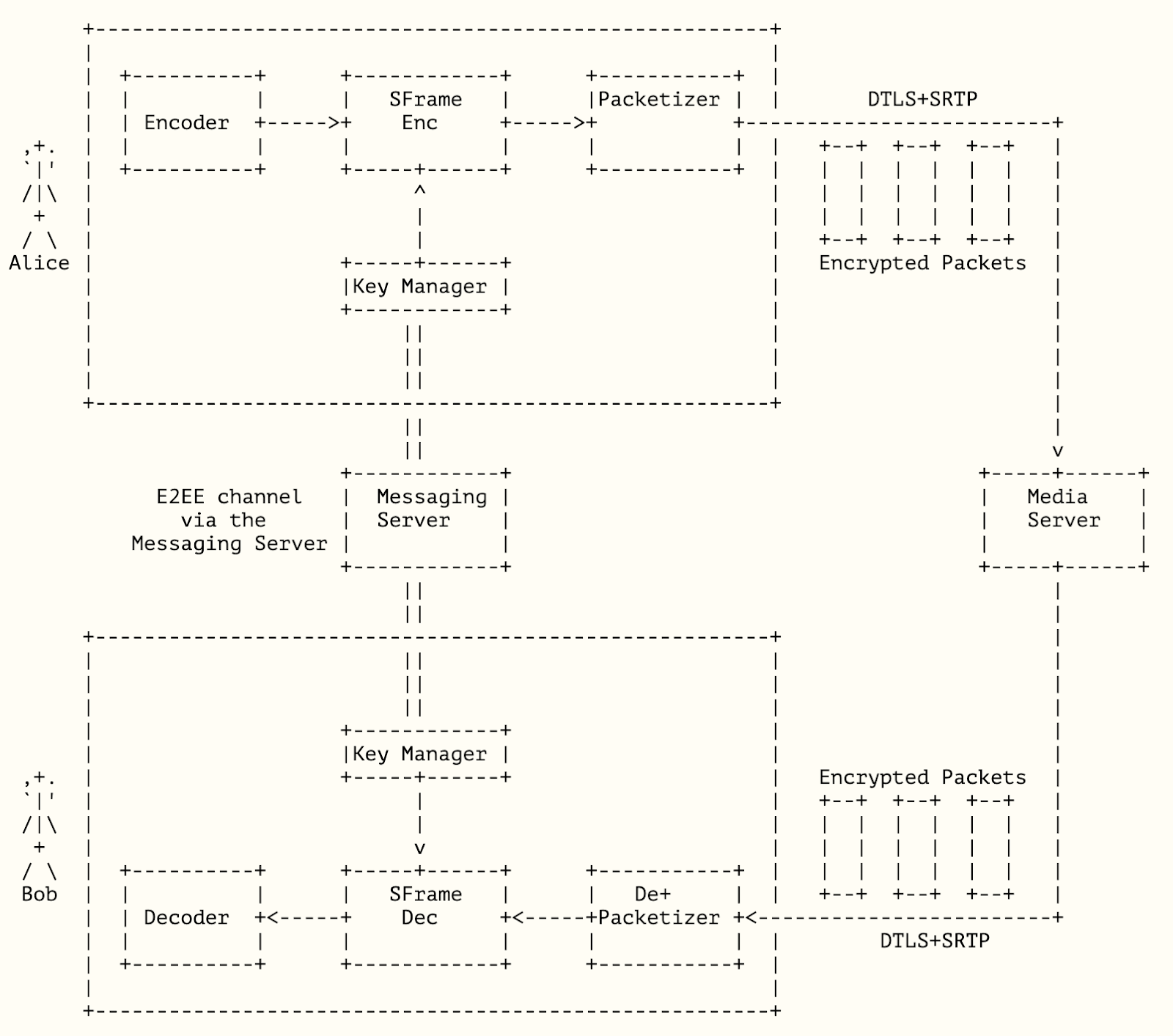
Bernard: One of the cool things about SFrame that makes it potentially much more extensible is that you are operating on an entire frame, not on packets. What that means is if you do a signature, you’re doing it once for the entire frame. It was considered infeasible to do a digital signature of each packet. For example, for a key frame that would imply you could be doing signatures for many packets. But for the SFrame, you’re only doing a signature per frame.
So it actually results in a dramatic decrease in the signature overhead. So it’s actually possible now to have essentially origin authentication – to know who each frame came from which has not been possible in the per packet model.
Everyone seems to agree that you need only one SFrame format, but then for key management that’s a trickier thing. We’ve had discussions at TPAC about potentially building SFrame into the browser – having a native implementation of SFrame. We are not yet at the point where we think we could have native key management. That is a much trickier thing because you could end up with five key management schemes that go into the browser.
WebCodecs
On the topic of giving developers deeper access and more control over the RTC stack is WebCodecs. I’ll let Bernard explain what that is:
Bernard: What [WebCodecs] does is it gives you access to the Codecs that are already in the browser at a low level. So essentially what you get the way to think about it is it has similarities to Insertable streams in that you get access to a frame. So for example, you can get access to an encoded frame, or you can feed in a raw frame and get an encoded frame.
Chad: Okay, so it’s more low-level, direct access to the encoder and decoder on the other end?
Bernard: Yeah. On the decoding side, it is similar to what we call MSE.
Chad: Media Source Extensions?
Media Source Extensions and the Media Source API replace much of what Flash did for streaming media in a standardized JavaScript. It allows a developer to play any containerized media out to the browser, even if it has DRM content protection on it. Here is a MDN link for more on that.
So how does this compare to MSE?
Bernard: the way to think of it as WebCodecs on the decode side is similar to that [MSE], except the media is not containerized. It would be in the encoded video frame. So they’re similar in that.
When people ask me, “how do you use these things together?”, as an example, if you’re going to do game streaming or a movie streaming or something, you could hook up WebTransport to receive the encoded media. And then you could render that with MSE, or you could render it WebCodecs. The difference in MSE is that you would have to transport containerized media. With WebCodecs it would not be containerized it would be packetized. So there’s that slight difference. And in functionality with MSE, you would actually get content protection support. Whereas in WebCodecs, at least today, you would not.
And what about MSE vs. WebCodecs on for encoding?
Bernard: That’s an interesting one, because if you think about it, if it’s a cloud game or a movie or something coming down from the cloud, you never do encoding on the browser, only decode. So that scenario actually doesn’t require WebCodecs to ever encode anything. The encode scenario would be for example, video upload. So if you wanted to do video upload, you can encode the video with WebCodecs and then send it up via WebTransport. You could send it up using a reliable stream, or you could do it with datagrams. If you do it with datagrams, you would then have to do your own retransmission and your own Forward Error Correction.
If you don’t care that much about the latency control for video upload, you might just use a reliable stream. So that’s a scenario where you use WebCodecs as the encoder and I think that scenario or that use case is one where WebCodecs has a real advantage because you wouldn’t have to do any weird tricks, like put it into canvas or something, or do whatever.
Does WebRTC have a future in the face of these alternatives?
Sending video is a big thing that WebRTC does. Will WebTransport with other API’s like WebCodecs or building your own codec in WASM replace WebRTC? In fact, this is what Zoom does (as we have covered) and some members of the Google Chrome Team even promoted this at the last web.dev live:
Is that a better approach? Is that where we are headed?
Chad: Is the direction to let people figure out and do that stuff on their own? Or do you think there also will be a parallel track to kind of standardize some of those mechanisms?
Bernard: Well, it is a real question. In a sense you get the freedom to do whatever you want, and that’s fine if everything is in your world end-to-end. As an example today, many people want to use an open source SFU. You can’t just send anything you want to an open source SFU – it has expectations on what it’s going to get. In simple scenarios where it’s just like a video upload or something, it may not matter, but certainly in something like a conferencing service, it would most certainly matter that you’d want to have a standard to know what to expect.
Now, the other thing to think about is performance, because I know people have raised the possibility of trying to do a conferencing server using WebTransport. And I would have a lot of trepidations about that, because particularly today, if you look at conferencing services, there’s a huge demand for bigger and bigger galleries like seven by seven, or maybe who knows how big they will get, 11 by 11 who knows.
So there seems to be insatiable demand – instructors want to see everybody in the class and the class could be enormous. So in a scenario like that, you’ve got an incredible number of streams, which could potentially be HD coming in. In that kind of scenario the performance actually matters an enormous amount. And so there were real questions about this kind of dis-aggregated model, where much of the code is running in WASM whether it’ll copy everything all over the place zillion times. And that’s how it seems to work today. For example, in WebTransport, you have two copies on receive. You have a copy whenever you send anything to WASM. Not everything gets offloaded to a separate thread.
Chad: I guess there’s a lot of potential for inefficient use of resources – and a lot for the browser to do to manage all those resources.
Bernard: Right. So people do complain that WebRTC is monolithic, but on the other hand there are enormous opportunities for optimization when it’s one monolithic code base that doesn’t have all of this JavaScript running in it. You can eliminate a huge number of copies that might exist in the disaggregated model.
Machine Learning
ML is a topic that pervades Computer Science in general. A couple of years ago we even dedicated most of the Kranky Geek 2018 event to AI in RTC. We have seen improvements in ML inside JavaScript like my Don’t Touch Your Face experiment and progressions on background removal/replacement in various WebRTC apps. Most of these operate around WebRTC instead of directly with it. In fact, ML seems to be conspicuously absent in WebRTC at a lower-level. I asked Bernard about this.
Bernard: One of the things we did when we started the discussion on WebRTC-NV was to do the NV use cases and try to gauge what people were enthusiastic about doing. It turned out that one of the things people were most enthusiastic about aside from the end to end encryption stuff was access to raw media because that opened up the entire world of Machine Learning.
Chad: Let me clarify too – access to the raw media just for the lower latency? In my experiments I’ve found it’s hard to get this stuff to run real time when there’s a lot of inherent latency in the stack.
Bernard: A lot of the scenarios we see involve processing done locally. So as an example, you have capture and you want to do things on the captured media before you send it out. A lot of the effects in Snapchat for example, are done that way. That’s what we call the funny hats where you look at the facial position and you put a hat on it or something. An enormously popular feature is custom backgrounds where you detect the background and change it in some way – have dynamic backgrounds, all of that kind of stuff.
Today, many of the other aspects of machine learning are done in the cloud. For example, typically speech transcription or translation is done in the cloud. So you send it up to the cloud. I don’t know that we’re that close to being able to do that natively, let alone in a web browser. There’s other kinds of things that can be probably done locally – certainly facial position and body positioning stuff like that.
The overall goal long-term is to be able to do anything that you can do natively that you can also do on the web. That not only requires access to the raw media, but raw media in an efficient way. So for example, in native implementations, we often see everything stay on the GPU and have all the operations done there. We’re not quite there. To do that we would need to have capture to the GPU without a copy then allow the machine learning operations to be done without copying it back to main memory, uploading, and downloading.
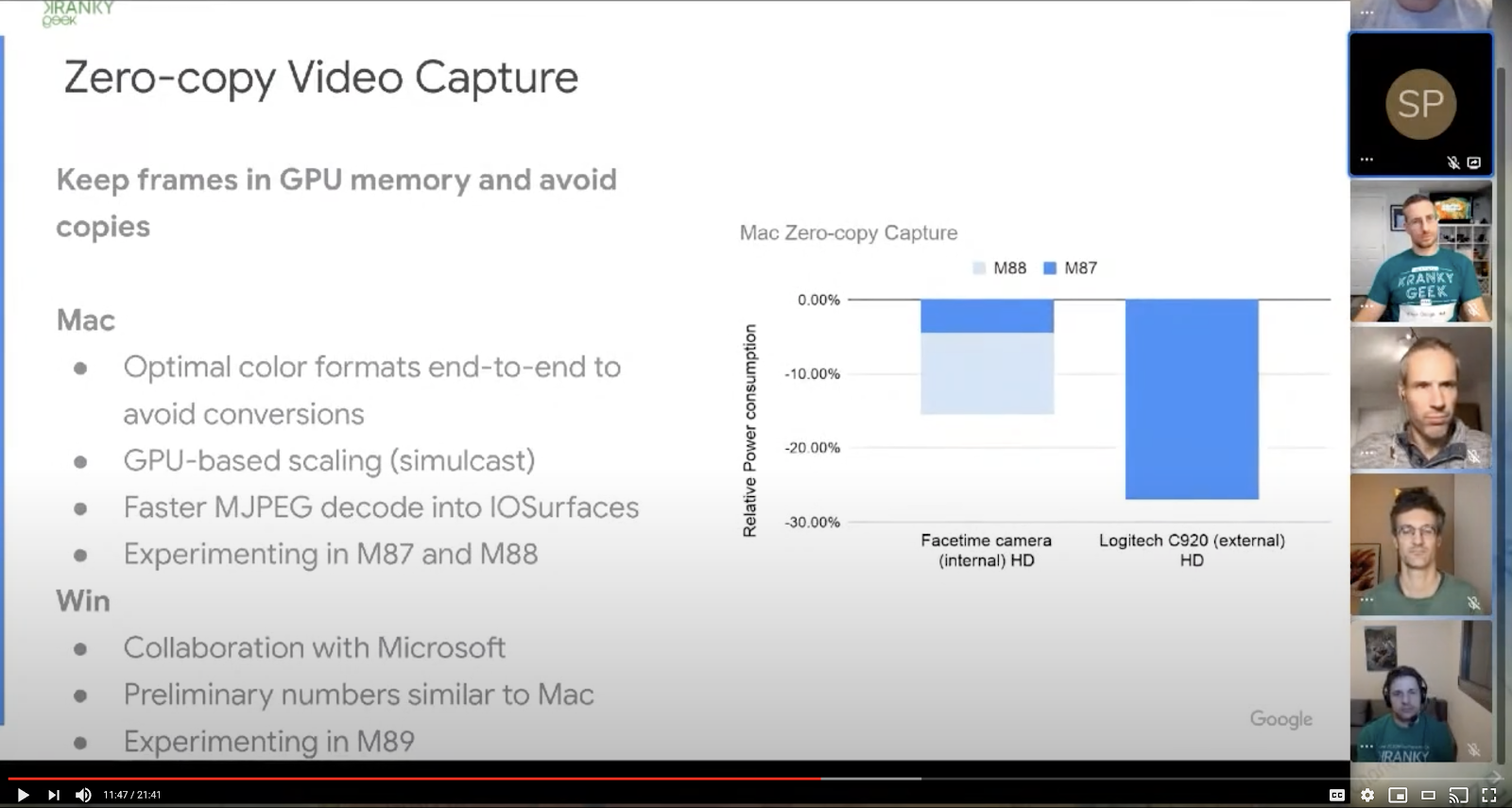
The context was a bit different, Google actually mentioned “zero-copy video capture” to keep frames in the GPU at this past Kranky Geek:
Bernard: So that was a topic that came up at the W3C workshop. One of the concepts that came out was the web neural network API. Previously what you’ve seen is a lot of the libraries like TensorFlow using things like WebGL or WebGPU. But if you think about that, that’s not an entirely efficient way to do it. Really what you’re trying to do is get basic operations like matrix multiply to operate efficiently and just giving it the WebGPU or WebGL operations isn’t necessarily the way to do it. So WebNN really attempts to tackle those operations at a higher level – like to have an operation for a matrix multiplier.
One of the key things here is all the APIs have to work in concert so that they deliver the data to the right place where it doesn’t have to be copied and another API. So as an example, you’ll see WebCodecs does support the idea of GPU buffers, but there are limitations because a lot of times those GPU buffers are not writeable – they’re read only. So if your goal is to do machine learning and change, what’s in the GPU buffer, well, you’re not going to be able to do that without a copy, but maybe you try to get as much performance as you can.
One 2020 product announcement that really caught my attention was NVIDIA’s Maxine. NVIDIA uses a Generative Adversarial Network (GAN) on its GPUs to grab a small number of keyframes and then a continuous stream of extract facial keypoints. It then combines the keyframe data with the facial keypoints to reconstruct the face. NVIDIA claims this approach uses one-tenth of the bandwidth of H.264. It also provides new capabilities since the reconstruction model can be adjusted to do things like superresolution, facial realignment, or simulated avatars.
This seems to be a more revolutionary use of ML for RTC. Is this where the standards are headed too?
Bernard: If you’re looking at the next-generation of codec research, an enormous amount of it is now being done with Machine Learning – just from the codec point of view.
The way I think about it is to look around you in the pandemic. What we’re seeing is a convergence of entertainment with real-time conferencing. So you’ll see a lot of your shows – your Saturday Night Live right – were produced with conferencing. I’ve seen theater put on where the characters had custom backgrounds. We’re even seeing some movies now incorporating conference technology. From Microsoft teams, we’ve seen what we call together mode, which is essentially taking the user input from the conference service and transporting this into a new event that’s entirely synthetic. The basketball players are real, but it’s combining the game with the fans who are actually not really there.
So you have constructed environments – AR/VR. I see a convergence between entertainment and real time scenarios. And that is reflected in the tools like WebTransport and WebCodecs. It’s both RTC and streaming. All these scenarios are one.
Machine Learning can be the director, it can be the cameraman, it can be the editor and it’s kind of holding the whole thing together. Every aspect of it is potentially being impacted by Machine Learning.
I don’t think of this as just a conventional media. I don’t think we should think of any of this as just trying to do the same old conferencing stuff with new APIs. That’s not very motivating for anybody just rewrite your conferencing service using this entirely new set of stuff. But I think it enables a whole new set of combined entertainment and conferencing scenarios that we can’t even imagine today. A lot of it seems to have flavors of AR/VR in it.
Ok, so a lot more convergence of real time media types controlled by AI.
What now?
Chad: any other thoughts you want to give before we close?
Bernard: The thing about this new technology is a lot of it is available in Origin Trial. It’s very instructive to use it and try to put together things and see how well it works together because you’ll certainly find a lot of weaknesses. I’m not saying all these APIs are coherent in any sense – they’re not. But it’ll I think give you a sense of what is possible out there and what you can do. People will be surprised at how soon some of these technologies will be available. I would say in 2021 it’s likely a bunch of these things will actually start shipping and you’ll see some of this out there in commercial apps. So people often treat it as something that’s not here today, or I don’t have to think about it and I think they’ll be wrong. People who think about it that way are going to be very surprised in an unpleasant way.
That was Bernard’s very informed view on the status and direction of WebRTC. If you want to hear more on the general direction of WebRTC there are a few Kranky Geek Virtual 2020 talks from November 19th, 2020 you should check out, a couple of which I linked to in this post. The WebRTC Team from Google covered a number of topics, including WebRTC NV and codecs. In addition, Bernard joined the WebRTC browsers panel to represent Edge along with leads from Chrome, Firefox, and Safari to talk about the state of WebRTC in browsers and what each is working on.
Stay tuned or subscribe to the Kranky Geek YouTube channel for more content like that.
{
“Q&A”:{
“interviewer”:“chad hart“,
“interviewee”:“Bernard Aboba“
}
}





Leave a Reply