Note: we have a Chinese translation of this post available here thanks to Xueyuan Jia and Xiaoqian Wu of the W3C.
Earlier this month, W3C web standards specialists, François Daoust and Dominique Hazaël-Massieux (Dom) joined us to discuss Real-Time Video Processing with WebCodecs and Streams. There they focused on how to setup a pipeline to handle low-latency processing of video frames as they come in from your camera, WebRTC stream, or other source. Their demo shows some example applications of this processing – changing colors, overlaying images, and even changing video codecs. Other use cases referenced include machine learning processing, like adding a virtual background.
Today they return to focus on the many technology options available to do actual video processing part. There are a lot of options for reading and changing the pixels inside a video frame. They review their experiments with every web-based option available today – JavaScript, WebAssembly (wasm), WebGPU, WebGL, WebCodecs, Web Neural Networks (WebNN), and WebTransport. A few of these technologies have been around for a while but many of them are newly available.
There is something here for anyone doing any kind of video analysis or manipulation. Thank you to François and Dominique for sharing their research testing the whole catalog of video processing options available on the web!
Contents
- Video Frame Processing Options
- Takeaways
{“editor”, “chad hart“}

In our post last week, we explored the creation of a real-time video processing pipeline using WebCodecs and Streams, playing with dominoes to create streams of VideoFrame objects. We discussed how to create a pipeline to do various processing of video frames, but we did not dig into the details of how to do that processing. In this post, we will investigate several technologies you can use to do that!
We start by reviewing each technology and conclude with some of our takeaways.
Note: This article is focused on the processing of video frames. While some of the technologies and considerations outlined here also apply to audio, the processing of audio frames would best be done using the Web Audio API, which this article does not cover.
Video Frame Processing Options
The following table summarizes technologies that can be used to process pixels of individual video frames represented as VideoFrame objects. It includes some high-level considerations to guide selection of the most appropriate one. See the more detailed sections on each of these technologies for more.
As seen in part 1, the performance of a processing workflow heavily depends on the need to make memory copies, which depends on where the video frame exists in the first place, which in turn depends on how it was created by the browser. With the types of workflows envisioned in part 1, it seems likely that video frames will exist in GPU memory at some point. This is what performance related pros/cons assume here.
| Method | What it can do | Pros | Cons |
|---|---|---|---|
| JavaScript | Manipulate pixels or entire images with the CPU |
|
|
| WebAssembly | Manipulate pixels or entire images with the CPU |
|
|
| WebGL | Manipulate pixels or entire images leveraging a GPU |
|
|
| WebGPU | Manipulate pixels or entire images leveraging a GPU |
|
|
| WebCodecs | Encode/Decode or change codec |
|
|
| WebTransport | Send encoded media stream data over the wire |
|
|
| Web Neural Network | Run neural network models to analyze or process images |
|
|
Using JavaScript
The obvious starting point to process pixels is to use regular JavaScript. JavaScript data is in CPU memory while video frame pixels usually reside in GPU memory. Accessing the frame pixels from JavaScript code first means copying them to an ArrayBuffer, and then processing them somehow:
|
1 2 3 4 5 6 7 8 9 |
// Copy the frame to a large enough (for a full HD frame) buffer const buffer = new Uint8Array(1920*1080*4); await frame.copyTo(buffer); // Save frame settings (dimensions, format, color space) and close it const frameSettings = getFrameSettings(frame); frame.close(); // Process the buffer in place and create updated VideoFrame process(buffer, frameSettings); const processedFrame = new VideoFrame(buffer, frameSettings); |
Pixel formats
What do the bytes in the ArrayBuffer represent? Colors for sure, but the pixel format of the frame (exposed in frame.format) may vary. Roughly speaking, applications will either get some combination of red, green, blue, and alpha components (RGBA, BGRA), or some combination of a luma component (Y) and two chrominance components (U, V). Formats with an alpha component have an equivalent opaque format (e.g., RGBX for RGBA), where the alpha component is ignored.
There is no way to request a specific format, and the provided format will typically depend on the context. For example, a VideoFrame generated from a camera or an encoded stream may use a YUV format called NV12, while a VideoFrame generated from a canvas will likely use RGBA or BGRA. Formulas exist to convert between frame formats, see for example the YUV article on Wikipedia.
How should you interpret the colors? That depends on the color space of the frame. There, we must acknowledge lack of expertise. Depending on the transformation you are applying to pixels, you may need to take that into account. At a minimum, you need to pass that information over to the VideoFrame constructor when you create the resulting frame after transformation is over. Also note that support for high-dynamic range (HDR) and wide color gamut (WCG) is on-going but not yet included in WebCodecs or supported by browsers. This is partly because there are other areas that first need to be extended before that becomes possible, such as adding canvas support for HDR content.
Performance
Performance-wise, the call to copyTo is expensive. Paul Adenot, from Mozilla, detailed key figures worth keeping in mind in the Memory access patterns in WebCodecs talk he presented during a W3C workshop on professional media production on the web, at the end of 2021. A C++ copy of a full HD frame (1920*1080) in standard dynamic range (SDR) takes ~5ms on a high-end system unless the frame is already in CPU cache.
Source: Paul Adenot’s Memory access patterns in WebCodecs talk
On a typical desktop computer, without actual process, the above logic takes between 15 and 22ms in Chrome. This is significant, especially if the transformed frame also needs to be rendered and thus written back to the GPU memory (that copy seems to be considerably faster though). Consider the timing budget per frame is 40ms at 25 frames per second (FPS). It needs to be ready in 20 ms at 50 fps. Support for WebCodecs is still nascent, performance of the copyTo function may well continue to improve. As illustrated by Paul, copies cannot be instantaneous in any case.
Once the copy has been made, looping through all pixels of a full HD frame in JavaScript generally takes 10-20ms on desktop computers and 40-60 ms on a smartphone. Now that SharedArrayBuffer is available in web browsers, we can use parallel processing across different workers to boost performance.
The code sample actually makes two copies in practice, one when copyTo is called, and one when the new VideoFrame object is created. These copies cannot be avoided because WebCodecs does not (yet?) have a mechanism to transfer ownership of the incoming ArrayBuffer to the VideoFrame. This is being considered, see for instance the Detach codec inputs issue. In practice, even without such a mechanism, browsers may be able to reduce the number of copies in some cases. For example, it is common for GPUs and CPUs to be integrated on mobile devices and to share the same physical RAM. On such devices, copies can, in theory at least, be avoided!
Using WebAssembly
WebAssembly (WASM) promises near-native performance for CPU processing. That makes it a suitable candidate to process frames. If you are not familiar with WebAssembly, I would summarize it in four points:
- As its name suggests, WebAssembly is a low-level assembly-like language, compiled to a binary format that runs in the browser (and other runtimes). On top of offering near-native performance, there are plenty of compilers available that can generate WebAssembly code from common source languages (C/C++, Rust, C#, AssemblyScript, etc.), making WebAssembly fantastic to port existing codebases to the web.
- WebAssembly only has number types (well, reference types also exist, but they are not relevant for the problem at hand, let’s ignore them). Anything else, from strings to more complex objects, are abstractions that applications (or compilers) need to create on top of number types.
- WebAssembly can export/import functions to/from JavaScript, so integration with JavaScript is straightforward.
- WebAssembly code operates on linear memory, i.e., an
ArrayBufferthat can be accessed both by the JavaScript code and the WebAssembly code.
To process a VideoFrame with WebAssembly, the starting point is the same as when JavaScript is used: the pixels need to be copied to the shared JavaScript/WebAssembly memory buffer with copyTo. Then you need to process the pixels in WebAssembly and create a new VideoFrame out of the result (which triggers another memory copy).
Demo code
We wrote the transformation function, a simple green background converter, in WebAssembly text format, a direct textual representation of the binary code. See resulting code in the GreenBackgroundReplacer.wat file. Compilation to binary WebAssembly can be done running wat2wasm from the WebAssembly Binary Toolkit. In practice, these transformations would most often be written in C++, Rust, C#, etc. and then compiled into WebAssembly bytecode.
Speed
Is WebAssembly faster? The cost of memory copies is the same as with pure JavaScript processing. Looping through pixels of a full HD frame in WebAssembly then takes a few milliseconds on a desktop browser, slightly less than pure JavaScript code. In total, processing per frame takes ~25ms on average on our desktop computers, ~50ms on our smartphones.
Code could be further optimized though:
- Pixels could be processed in parallel using WebAssembly threads (like JavaScript workers). WebAssembly threads are still at the proposal phase and not yet part of the core WebAssembly standard, but they are already supported across browsers.
- Single instruction multiple data (SIMD) instructions could be used to process up to four pixels at once, see Vector instructions in the WebAssembly specification for details.
Other considerations
Professional video editing applications that leverage WebAssembly tend to do everything in WebAssembly – muxing/demuxing, encoding/decoding, and processing to save time. It helps that these apps often share the same C/C++ code as their native counterparts that already do it like this. Aside from performance, this approach gives them more flexibility to support codecs that browsers may not natively support. The old How Zoom’s web client avoids using WebRTC post on this blog shows Zoom as an example here.
Other notes:
- WebAssembly reads/writes numbers using little-endian byte ordering. The WebAssembly code in the demo reads the four-color components at once, effectively reversing the order of the bytes in the resulting number (RGBA becomes ABGR).
- As with JavaScript, the WebAssembly code also needs to handle all different pixel formats. Our code only deals with RGBA-like formats because we use WebGPU to convert the incoming frame to RGBA (see below) before it reaches the WebAssembly transformation.
Using WebGPU
The main drawbacks of processing frames using JavaScript and WebAssembly are the cost of the read back copy from GPU memory to CPU memory, and the limited amount of parallelism that can be achieved with workers and CPU threads. These constraints do not exist in the GPU world, making WebGPU a great fit for processing video frames.
Demo code
WebGPU exposes an importExternalTexture method to import video frames as textures directly from a <video> element. While that is not in the specification yet (see Define WebCodecs interaction in an extension proposal), that same method may also be used to import a VideoFrame. That is the hook we need, the rest of the code being… obscure if you are not familiar with GPU concepts but mostly boilerplate.
The WebGPU transformation in the demo is in VideoFrameTimestampDecorator.js. It overlays the timestamp of the frame using a color code in the bottom right corner of the frame.
The idea is to create a render pipeline that imports the VideoFrame as texture and processes pixels one by one. A render pipeline is roughly composed of a vertex shader stage that produces clip space coordinates that get interpreted as triangles. Then a fragment shader stage takes those triangles and computes the color of each pixel in the triangle. Shaders are written in the WebGPU Shading Language (WGSL).
Unless the transformation intends to change the shape and dimensions of the video frame, it is easiest to call the vertex shader six times to produce two triangles that cover the entire frame. Coordinates are also produced in so-called uv coordinates, which match regular frame coordinates. The core of the vertex shader, in WGSL, is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@vertex fn vert_main(@builtin(vertex_index) VertexIndex: u32) -> VertexOutput { var pos = array<vec2<f32>, 6>( vec2<f32>(1.0, 1.0), vec2<f32>(1.0, -1.0), vec2<f32>(-1.0, -1.0), vec2<f32>(1.0, 1.0), vec2<f32>(-1.0, -1.0), vec2<f32>(-1.0, 1.0)); var uv = array<vec2<f32>, 6>( vec2<f32>(1.0, 0.0), vec2<f32>(1.0, 1.0), vec2<f32>(0.0, 1.0), vec2<f32>(1.0, 0.0), vec2<f32>(0.0, 1.0), vec2<f32>(0.0, 0.0)); var output : VertexOutput; output.Position = vec4<f32>(pos[VertexIndex], 0.0, 1.0); output.uv = uv[VertexIndex]; return output; } |
The fragment shader then looks at the coordinates of the pixel it needs to color. If it is in the bottom-right corner, the shader computes the overlay color. Otherwise, the shader outputs the pixel as it exists in the original video frame using a texture sampler provided by WebGPU and the textureSampleBaseClampToEdge function. The core of the fragment shader, in WGSL, is
|
1 2 3 4 5 6 7 8 9 10 11 |
@fragment fn frag_main(@location(0) uv : vec2<f32>) -> @location(0) vec4<f32> { if (uv.x > 0.75 && uv.y > 0.75) { let xcomp: f32 = (1 + sign(uv.x - 0.875)) / 2; let ycomp: f32 = (1 + sign(uv.y - 0.875)) / 2; let idx: u32 = u32(sign(xcomp) + 2 * sign(ycomp)); return timestampToColor(params.timestamp, idx); } else { return textureSampleBaseClampToEdge(myTexture, mySampler, uv); } } |
From a JavaScript perspective, the GPU device is initialized to write the result to a canvas that can then be used to create the final VideoFrame. The transformation logic once parameters and GPU commands have been prepared looks like:
|
1 2 3 |
gpuDevice.queue.submit([commandEncoder.finish()]); const processedFrame = new VideoFrame(canvas, …); controller.enqueue(processedFrame); |
Some additional notes on the demo code:
- The call to
submitruns the commands on the GPU, which is obviously an asynchronous process. No need to wait for anything though, the browser will automatically await the completion of the GPU commands linked to the canvas before any attempt to read it (here in the call to the VideoFrame constructor). - A canvas is not strictly required from a WebGPU perspective since the goal is not to display the result on screen but rather to produce a new
VideoFrameobject. Rather, we could render to a plain texture made fromgpuDevice.createTexture. The problem is that there is no direct way to create aVideoFrameout of aGPUBuffer, so the canvas is needed from a WebCodecs perspective to avoid copying the result to CPU memory.
GPU programming is very different
Unless you are already familiar with GPU programming, the learning curve is very steep. Some examples include:
- The memory layout in WebGPU Shading Language (WGSL) imposes constraints on values in terms of alignment and size. It is easy to get lost when you want to pass parameters to the GPU along with the texture.
- Memory locations are partitioned into address spaces. The difference between uniform and storage is not clear to me. When should either be used? What are reasonable amounts of memory?
- There are many ways to achieve the same result. Is there a right way? For example, as currently written, the fragment shader is far from efficient, as it checks pixel coordinates for each pixel it receives. It would be more efficient to extend the vertex shader to divide the entire frame into a set of triangles and return an additional parameter for each coordinate that clarifies whether the point is to be taken from the original frame or whether it is one of the color-coded points. Is it worth the effort?
WebGPU is fast!
While the learning curve is steep, the results are worth it! To start with, the sampler provided by WebGPU comes with magic inside: regardless of the frame’s original pixel format, the sampler returns a color in RGBA format. This means that applications do not have to worry about conversion, they will always process RGBA colors. It also makes it easy to convert any incoming frame to RGBA, simplifying the fragment shader to a simple call to the sampler, as done in ToRGBXVideoFrameConverter.js:
|
1 2 3 4 |
@fragment fn frag_main(@location(0) uv : vec2<f32>) -> @location(0) vec4<f32> { return textureSampleBaseClampToEdge(myTexture, mySampler, uv); } |
Note: Technically speaking, while the shader will see RGBA colors, the output format is determined by the canvas’ format, which can also be BGRA, but that is under the control of the application.
More importantly, with no copy needed to import the texture, no copy needed on the resulting frame, and individual pixels being processed in parallel, processing with WebGPU goes fast, ~1ms on average (with small variations) in our simple scenario on a desktop computer, ~3ms on a smartphone. That said, it is not entirely clear to us that the times we measure are really the right ones when WebGPU is used: it is quite possible that Chrome only blocks JavaScript to await completion of the GPU work when it absolutely needs to, and not upon creation of the VideoFrame. Still, processing with WebGPU runs smoothly across devices.
WebGPU samples may be broken
The WebGPU API and WGSL language continue to evolve. For instance, the layout parameter is now required in the object passed to createComputePipeline, see https://github.com/gpuweb/gpuweb/issues/2636.
This and other changes may affect WebGPU samples found on the Web, including the WebGPU samples in the official WebRTC repo samples. I reported the issue in: https://github.com/webrtc/samples/issues/1602
Using WebGL
We used WebGPU in the demo because we wanted to become more familiar with the API. WebGL could similarly be used to process frames. More importantly, being implemented across browsers, WebGL would be a much saner choice until WebGPU becomes available! (See the links in part 1 for help tracking WebGPU availability).
While WebGL is different from WebGPU, the overall approach is going to be the same. The Media Working Group maintains a WebCodecs sample that includes a WebGL renderer of VideoFrame objects. You will recognize the vertex and fragment shaders in this code doing the same sampling of the VideoFrame pixels. This time they are imported as a 2D texture through:
|
1 2 3 4 5 |
gl.texImage2D( gl.TEXTURE_2D, 0, gl.RGBA, gl.RGBA, gl.UNSIGNED_BYTE, frame); |
Our demo does not integrate with Streams but the approach we followed for WebGPU would work just as well.
Unless you are looking into using advanced GPU features that are only exposed by WebGPU, the resulting WebGL VideoFrame processing performance should be like WebGPU.
Using WebCodecs
WebCodecs can of course be used to encode and decode video frames through the VideoEncoder and VideoDecoder interfaces. While WebCodecs does not allow one to modify individual pixels or examine an image by itself, it does include many tweakable encoding/decoding parameters that do adjust the stream. See the spec for details on options here.
Sample logic to encode a video stream in H.264 and decode an H.264 video stream can be found in the worker-transform.js file.
TransformStream
VideoEncoder and VideoDecoder both use an internal queue, but it is easy to connect this to a TransformStream and propagate backpressure signals: just tie the resolution of the promise returned by the transform function to the output of the encode or decode function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
const EncodeVideoStream = new TransformStream({ start(controller) { // Skipped: a few per-frame parameters this.encodedCallback = null; this.encoder = encoder = new VideoEncoder({ output: (chunk, cfg) => { if (cfg.decoderConfig) { // Serialize decoder config as chunk const decoderConfig = JSON.stringify(cfg.decoderConfig); const configChunk = { … }; controller.enqueue(configChunk); } // Skipped: increment per-frame parameters if (this.encodedCallback) { this.encodedCallback(); this.encodedCallback = null; } controller.enqueue(chunk); }, error: e => { console.error(e); } }); VideoEncoder.isConfigSupported(encodeConfig) .then(encoderSupport => { // Skipped: check that config is really supported this.encoder.configure(encoderSupport.config); }) }, transform(frame, controller) { // Skip: check encoder state // encode() runs async, resolve transform() promise once done return new Promise(resolve => { this.encodedCallback = resolve; // Skipped: check need to encode frame as key frame this.encoder.encode(frame, { … }); frame.close(); }); } }); |
Note the encoding configuration applies to subsequent encoded frames. You need to send the encoding configuration to the logic that is going to decode the stream afterwards. The easiest I found to do this is to send that configuration as a specific chunk in the stream as done in the code. This has the bonus of allowing configuration changes mid-stream.
WebCodecs performance
Encoding performance highly depends on the codec, resolution, and underlying device. Full HD video frame encoding in H.264 on typical desktop devices may take anywhere between 8-20ms. Decoding is usually much faster, 1ms on average. On a smartphone, encoding of the same frame may take 70ms, while decoding typically takes 16ms. In all cases, the first few frames usually take longer to encode and decode, up to a few hundreds of milliseconds. This is likely due to the time needed to initialize the encoder/decoder.
CPU vs. GPU
For encoding, our time measures are different depending on whether the frame is in GPU memory or CPU memory. Encoding takes ~8ms when the frame first goes to WebAssembly (which moves it to CPU memory), ~20ms when the frame stays on the GPU. That likely means that this encoding is done in CPU memory on our machines, requiring a read back from GPU memory to CPU memory.
Side note: it is useful to visualize GPU memory and CPU memory as separate. GPU memory and CPU memory may be the same in some architectures, like on smartphones but they are typically disjointed in desktop architectures. In any case, browsers may isolate them in different processes for security reasons.
Using WebTransport
We mentioned WebTransport already as a mechanism for sending and receiveing encoded frames to/from the cloud. We did not have time to dig into this in our demo. However, Bernard Aboba, co-editor of the WebCodecs and WebTransport specifications, wrote a WebCodecs/WebTransport sample that mixes WebCodecs and WebTransport.
The sample code does not link the VideoEncoder and VideoDecoder queues to WHATWG Streams. It instead monitors the VideoEncoder’s queue, dropping incoming frames that cannot be encoded in time. Depending on the application’s needs, backpressure signals could be propagated to the encoder or the source instead.
Applications may typically want to only drop incoming frames when absolutely needed in the presence of backpressure. Instead, they may want to change encoding settings e.g., to lower the quality of the encoded video and reduce bandwidth.
The difficulties of managing backpressure are precisely the reason the encode and send steps are entangled in the core WebRTC API (see beginning of Part 1). Encoding needs to react to fluctuations of the network in real-time.
Also, as noted in Real-Time Video Processing with WebCodecs and Streams: Processing Pipelines (Part 1), real-life applications will be more complex to avoid head-of-line blocking issues, and use multiple transport streams in parallel, up to one per frame. On the receiving end, frames received on individual streams need to be reordered and merged to re-create a unique stream of encoded frames.
Note: Sending and receiving encoded frames with an RTCDataChannel would work similarly. Backpressure signals would also need to be handled by the application.
Using Web Neural Network (WebNN)
A key use case for processing video frames in real time is for blurring or removing the user’s background. Nowadays, this is typically done through machine learning models. WebGPU exposes GPU computing capabilities and could be used to run machine learning algorithms. That said, devices now commonly embed dedicated neural network inference hardware and special instructions that WebGPU cannot target. The more nascent Web Neural Network API provides an hardware-agnostic abstraction layer to run machine learning models.
Ningxin Hu, co-editor of the WebNN API, developed sample code to highlight how WebNN could be used to blur the background. The sample code is also described and discussed in a GitHub issue.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
SOURCE: https://www.w3.org/TR/webnn/#example-99852ef0 const context = await navigator.ml.createContext({powerPreference: 'low-power'}); /* The following code builds a graph as: constant1 ---+ +--- Add ---> intermediateOutput1 ---+ input1 ---+ | +--- Mul---> output constant2 ---+ | +--- Add ---> intermediateOutput2 ---+ input2 ---+ */ // Use tensors in 4 dimensions. const TENSOR_DIMS = [1, 2, 2, 2]; const TENSOR_SIZE = 8; const builder = new MLGraphBuilder(context); // Create MLOperandDescriptor object. const desc = {type: 'float32', dimensions: TENSOR_DIMS}; // constant1 is a constant MLOperand with the value 0.5. const constantBuffer1 = new Float32Array(TENSOR_SIZE).fill(0.5); const constant1 = builder.constant(desc, constantBuffer1); // input1 is one of the input MLOperands. Its value will be set before execution. const input1 = builder.input('input1', desc); // constant2 is another constant MLOperand with the value 0.5. const constantBuffer2 = new Float32Array(TENSOR_SIZE).fill(0.5); const constant2 = builder.constant(desc, constantBuffer2); // input2 is another input MLOperand. Its value will be set before execution. const input2 = builder.input('input2', desc); // intermediateOutput1 is the output of the first Add operation. const intermediateOutput1 = builder.add(constant1, input1); // intermediateOutput2 is the output of the second Add operation. const intermediateOutput2 = builder.add(constant2, input2); // output is the output MLOperand of the Mul operation. const output = builder.mul(intermediateOutput1, intermediateOutput2); |
source: https://www.w3.org/TR/webnn/#example-99852ef0
Note the sample above broke sometime during the making of this post 🙁 As mentioned in the WebGPU samples may be broken section, these APIs are works in progress. WebNN is not implemented anywhere, so the WebNN sample code is built on top of WebGPU for now.
Takeaways
To Stream or not to Stream
The backpressure mechanism in WHATWG Streams takes some getting used to but appears simple and powerful after a while. It remains difficult to reason about backpressure in the video processing pipelines described in these 2 articles because WHATWG Streams are not used throughout the pipe chain. For example, the use of MediaStreamTrack in WebRTC divides the pipe chain into distinct parts with different backpressure mechanisms. From a developer perspective, this makes mixing technologies harder. It also creates more than one way to build processing pipelines, with no obviously right approach to queuing and backpressure.
We found the use of WHATWG Streams natural when we wrote the code, but the demo remains basic. The use of WHATWG Streams may not work well when lots of corner cases need to be handled. The Media Working Group, which standardizes WebCodecs, decided against coupling WebCodecs and Streams. They documented the rationale for that in Decoupling WebCodecs from Streams. The reasons included the need to send control signals along the chain. We saw the need to send the decoding configuration as a chunk for example. Other signals such as flush and reset cannot easily get mapped to chunks. Does the approach we took scale to real-life scenarios? It would be interesting to explore a more realistic video conferencing context.
Pixel formats and color spaces
WebCodecs exposes raw video frames as they exist in memory. That puts the onus on applications to handle the different video pixel formats and interpret colors correctly. Conversion between pixel formats is neither easy nor hard, but it is tedious and error prone. We found the ability provided by WebGPU to convert everything to RGBA quite useful. There may be value in exposing a conversion API as raised in the How to handle varying pixel formats and API for conversion between pixel formats issues.
Technologies and complexity
This exploration provided us with a good excuse to become more familiar with WebGPU, WebAssembly, Streams and WebCodecs. Each has its own concepts and mechanisms. It took serious effort to navigate the APIs, write the code, and learn where to look to debug. For example, pipeline layouts, memory alignment concepts, shader stages and parameters in WebGPU and WGSL require some hard thinking – that is unless you are used to GPU programming. So do WebAssembly memory layout and instructions, video encoding and decoding parameters, streams, and backpressure signals, etc.
Said differently, combining technologies creates cognitive load, even more so because these technologies live in their own ecosystem with disjointed concepts and communities. There is little that can be done on top of a documentation effort. Standard specifications tend to be a bit dry on explanations and, not surprisingly given how recent these technologies are, there are few articles that talk about media processing with WebGPU, WebTransport and WebCodecs yet. This will no doubt improve over time.
Copies and hidden copies
The data from this demo provides some video frame processing performance numbers for each technology. The main takeaway is that raw frame copies from GPU memory to CPU memory are the costliest operations. As such, applications will want to make sure that their processing pipeline requires one GPU-to-CPU copy at most.
That is easier said than done. From a pure frame transformation perspective, staying on the GPU keeps performance under control, and WebGPU proves extremely powerful. At least for now, unfortunately two copies are needed to process a frame with JavaScript or WebAssembly.
That said, counter-intuitively, frame encoding may incur a copy when the initial frame is in GPU memory, even when hardware acceleration is used (depending on the user’s device, hardware acceleration may be CPU-bound). Performance gains obtained by using WebGPU to process frames can be offset during a follow-up encoding phase. Conversely, the copy cost associated with WebAssembly may not be a problem if WebAssembly processing is followed by an encoding phase.
This is illustrated in the demo when you compare encoding times that follow a transform operation in WebAssembly with encoding times when the encode/decode transformation is the only one being applied:
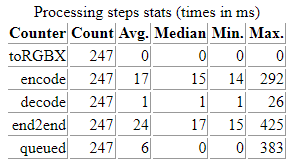 |
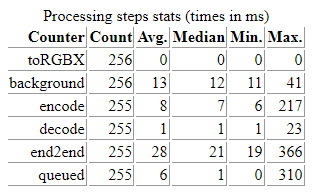 |
| encoding takes ~17ms on a GPU-backed frame | encoding only takes ~8ms on a CPU-backed frame |
We may not be measuring what we think we are… Some copies may be made under the hoods and not exactly when times get recorded, especially when WebGPU is used.
Regardless, it remains hard to reason about when copies are made, and about settings that may improve processing times. Copy is explicit when the copyTo method is called but browsers may also make internal copies at other times. These copies may introduce significant delays in live stream scenarios where the time budget per frame is small. A joint effort to discuss memory copies started in the WICG/reducing-memory-copies repository some time ago, with ongoing discussions in the Working Groups responsible for the technologies at hand. Whether solutions materialize in that space, we note that, while significant, the delays we measured do not prevent processing of reasonable video frames (e.g., HD at 25fps) in real-time across devices.
{“author”: “François Daoust“}





Thank you for the article. I thought that processing video frames without “getImageData()” or “VideoFrame.copyTo()” is impossible. There are some examples on webrtchacks on how to make a virtual background, but those examples use “getImageData()”, which is a very expensive operation. Just recently I learned about selfie_segmentation.js by MediaPipe which probably uses WebGL+WASM (from what I saw in Chrome performance inspector). The difference in performance is significant. BTW, it would be useful if webrtchacks published some articles about how to use such tools (e.g. Face mesh) to create specific effects like face filters, etc.
Note I did do a post using TensorFlow.js here: https://webrtchacks.com/stop-touching-your-face-with-browser-tensorflow-js/
MediaPipe is the more modern approach – I did that here: https://webrtchacks.com/how-to-make-virtual-backgrounds-transparent-in-webrtc/ and Fippo did something similar here: https://webrtchacks.com/smart-gallery/