As WebRTC implementations and field trials evolve, field experience is telling us there are still a number of open issues to make this technology deployable in the real world and the fact that we would probably do some things differently if we started all over again. As an example, see the recent W3C discussion What is missing for building (WebRTC) real services or Quobis‘ CTO post on WebRTC use of SDP.
Tim Panton, contextual communications consultant at Westhawk Ltd, has gone through some of these issues. During the last couple of years we had the chance to run some workshops together and have some good discussions in the IETF and W3C context. Tim’s expertise is very valuable and I thought it would be a good idea to have him here to share some of his experiences with our readers. It ended up as a rant.
{“intro-by”,”victor”}

The worst of all worlds or why compromise can be a bad idea (by Tim Panton)
Let’s be honest, this is a rant. Hopefully measured and well informed, but a rant none the less.
I’ve been working on WebRTC since before it existed. Embedding realtime voice and data into webpages has been what I’ve been obsessed with for the last 5 years. The weird thing is that despite the huge success of reaching 1 billion webRTC devices, it hasn’t got any easier.
Why – principally the decision by the IETF WG to support what I call ‘future legacy interop’ but more on that in a moment.
Consider the following problem: I want to get realtime data from a sensor connected to my Raspberry Pi and display it in a browser. The Pi and the browser are behind NATs and the data is both private and time sensitive, so I don’t want to bounce off a public web server.
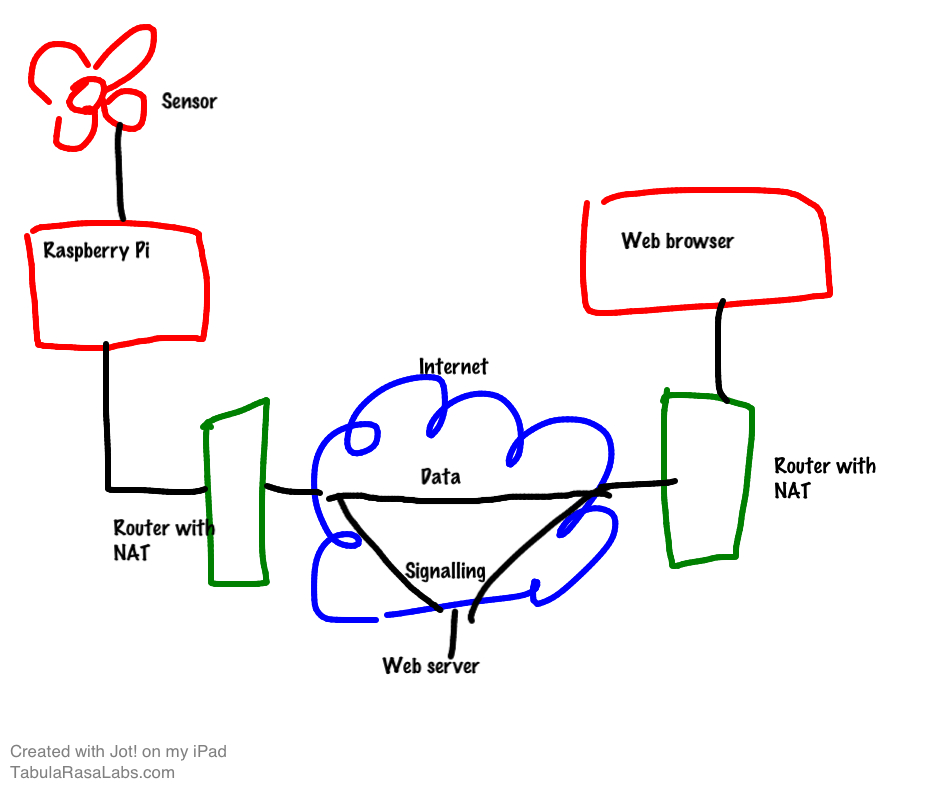
Back in my PhoneFromHere.comdays, I’d have embedded our spiffy Java applet into a web page, then used the same java code as a library to build an application on the Pi. The two would have spoken IAX2, mediated via a convenient Asterisk server which would have sorted out the NAT for them (if possible) and then stepped out of the way.
With WebRTC, sure, I can use the data channel in the browser, so the applet is redundant, but as for the Pi…. I’m kinda stuck because it doesn’t come with a library that speaks the SCTP/DTLS/ICE/UDP layered protocol the webRTC data channel uses.
In theory I could build google’s WebRTC code drop and cross compile it onto the Pi after removing all the audio and video dependencies and the browser assumptions.
Judging from the grumbling I hear from everyone who is going down that route, I wouldn’t enjoy it and it would be a lot of work (I suspect more than a few of the new Mac pros are being bought as WebRTC developer’s build servers, to try and get some productivity back from a build that seems to take forever).
I’m a standards guy and I implement protocols. I’ve done SNMPv3, IAX2 and WebRTC media before. The DataChannel can’t be that hard?
Indeed it isn’t (caveat – I haven’t got the project working yet, so I may be wrong here). There is a nice open source library in Java that implements ICE/Stun/TURN from my friends at Jitsi.
There is a tested DTLS stack from the wonderful BouncyCastle crew, so I’m all set. It’s just a matter of gluing it all together, surely.
So what have I spent the last week doing? Struggling with the depths perfect forward secrecy public key crypto? Debugging errant ICE packets? No – the complex stuff just worked, they had well thought through APIs. I’ve spent my time trying to derive the correct Session Description Protocol (SDP) incantation to start the process off.
Seriously, writing the SDP manipulation, parsing and transport has taken days, as compared to the hours the crypto and ICE took.
Let’s examine how this could possibly be true.
In order to get a DataChannel session going, the peers need to exchange 4 things
- An ICE username
- An ICE password
- A list of possible IP addresses and ports that ICE needs to test
- A DTLS fingerprint
Four lines of JSON you’d think.
The current WebRTC spec says I should exchange this information with the browser API in a format called SDP, which has been used in the VoIP world for the last 10 years.
Here is the absolute minimum SDP stanza that encapsulates it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
type: offer, sdp: v=0 o=- 3147944783490393471 2 IN IP4 127.0.0.1 s=- t=0 0 a=msid-semantic: WMS m=application 1 DTLS/SCTP 5000 c=IN IP4 0.0.0.0 a=ice-ufrag:Kt22onMAiX4RHZ8Y a=ice-pwd:pwXwBMH3qEbgQ/ArA8sSnNvl a=ice-options:google-ice a=fingerprint:sha-256 7B:AA:A6:89:0F:DC:3C:07:0C:31:84:05:96:54:38:83:35:79:49:AB:42:55:6F:C1:D6:60:64:92:E5:4B:6F:62 a=setup:actpass a=mid:data a=sctpmap:5000 webrtc-datachannel 1024 a=candidate:3486758882 1 udp 2113937151 192.67.4.33 55059 typ host generation 0 |
That’s 15 impenetrable lines. To derive them you’d need to read, mark, learn and inwardly digest some thing of the order of 15 RFCs (hint: you can check now WebRTChacks’ SDP interactive tutorial). I didn’t do that, I tinkered with Chrome Canary getting it to talk to itself and grabbed the SDP that worked.
Of those lines, only 4 actually convey any useful information. But all 15 have to be _exactly_ right or the SDP will be rejected (with nary a clue as to why).
Is there a simple opensource parser for this stuff I can use?
Yes there are many.
But no – none of them actually work. Because you see, the IETF are making this stuff up as they go along. I have no clue what
|
1 |
a=msid-semantic: WMS |
is or does and I defy you to find a parser that does (except the one in Chrome Canary).
As for parsing this mess, each line has it’s own baroque little format. For example candidate lines have a fixed sequence of values, up to the 6th, after which it reverts to name value pairs.
The 1 in m= line is a port number, except that the 1 is a magic value, meaning that you should ignore it.
Oh, and the m line functions as a scope delimiter, so the
|
1 |
a=ice-pwd:pwXwBMH3qEbgQ/ArA8sSnNvl |
line means something different if it is before or after the first m=.
There’s also a 3rd possible place to set the ice password, you can put it in the candidate line too, where it has yet a different scope and syntax, thusly:
|
1 |
a=candidate:2 1 UDP 2130706431 192.67.4.33 4570 typ host name rtp network_name en0 username lrjh password pwXwBMH3qEbgQ/ArA8sSnNvl generation 0 |
Does this matter? Well yes – it does. It means that your code has to look in all those places (in the correct order) to find the ICE password to apply to a given candidate, that’s probably 10 lines of parser (with ifs etc) instead of 1, so an order of magnitude of extra scope for errors.
None of this set off my rant, I’d seen it all before while I was implementing the Phono.com WebRTC support, I thought I knew what I was getting into.
The straw that broke this camel’s back was :
|
1 |
a=setup:actpass |
It is typical of SDP that 15 characters can efficiently sum up what is wrong with the whole ‘API’ without actually being decipherable by more than 15 people on the planet.
This attribute was a new one on me, according to RFC5763 it indicates which peer is going to initiate the DTLS connection (DTLS is an asymmetric protocol, so in a Peer to Peer call one side has to agree to be the server).
This is odd, because I thought we already had 2 ways to specify who was the DTLS server, either based on who sent the SDP offer, or who ever set ICE-CONTROLLING in the successful ICE packet exchange. Why might we need a 3rd way to establish the same thing ? (I’m still trying to work out the precedence rules here).
The reason according to the RFC is to support ‘early media’.
Early media is a ‘feature’ of ISDN systems, It was designed to allow the far end to send their local ringback tone before the call got connected or billed. So if you called a Russian number from the USA, you’d hear the Russian ringback tone once the callee’s phone started ringing. Because it happens _prior_ the start of billing, it got ruthlessly abused by folks trying to squeeze a little more time for their money. Many IVRs attached to 800 numbers will use early media to play the welcome and first prompt, before they actually answer the call.
Why would the WebRTC datachannel want to support this weird legacy PSTN billing quirk? I have _no_ idea, but it does.
Future legacy interop
As I said, the problem is ‘future legacy interop’. Let’s be clear. There are no legacy devices that speak this protocol, or can understand this SDP. We’ve been burdened with this floppy, ill specified, un paresable mess for the sake of some fictional devices that may in the future be built to function both as traditional SIP endpoint and also as native WebRTC citizens, with no gateway between them and the outside world.
When some of us pointed this out 18 months ago, we were told that it would be much quicker not to try and create a new session description format, re-using SDP would save time, as a group the IETF had solved all the necessary problems. We put up a fight, but in the end we caved in order to get the standard out quicker. Now, I find that we are still adding stuff the SDP and worse it is becoming increasingly clear that, yes, you do need an API surface to manipulate the session description (See the recent discussion about APIs for BUNDLE and the doohicky discussion.
I know, I know, WebRTC wasn’t meant for raspberry Pi’s or to be embedded in Doorbells or weather stations, so this rant shouldn’t matter, but that is what is happening, so it does matter.
(For comparison, HTML wasn’t supposed to be a router control mechanism, but how did you configure your domestic DSL device – from an embedded web page ?)
So. Deep breath–
Don’t let this rant diminish the achievement that WebRTC represents, high quality realtime on 1 billion endpoints is great. I just wish it could be easier. So the weekend Pi hackers could pick it up and use it, not just the big companies with the money to wade through a heap of RFCs. The underlieing protocols and technology are fine, but this API surface is a deterrent.
What is the lesson here? We’ve forgotten the most important rule of API and protocol design – as stated by Albert Einstein “Everything should be made as simple as possible, but no simpler.” – We need to draw a line under WebRTC 1.0 quickly, get it signed off – let it be used, flourish, spread etc and we need to get back to the drawing board and come up with an API design we won’t be ashamed of.
P.S. For a slightly calmer view on the state of WebRTC standards you might want to read some slides I did for WebRTC expo and Victor’s WebRTC standards update
{“author”,”Tim Panton”}




Well written post and an understandable rant. I’m working on a WebRTC gateway implementation myself, and I can confirm that dealing with SDP so far has proven to be, well, harsh at times, and certainly the harshest “beast” in the portfolio of protocols WebRTC mandates right now. Even now it is what is limiting the gateway itself, as it is hard to parse all possible combinations correctly (and as Tim pointed out, without much help from existing stacks unfortunately) without taking into account potentially unpredictable results. This forces me (and probably others) to keep things simple/simpler, despite what we could actually achieve with such a promising technology.
SDP is not that complex, per se, but it is indeed overly verbose and ambiguous, and the fact that an apparently harmless mismatch in what you said and what you meant can cause underexplained errors when involving them in browsers certainly doesn’t help. Just to say the latest, the simple fact that I only placed a c-line at the session level and none at the media level caused an obscure “m-lines not matching” error in Chrome, that forced me to try and remove one line at a time to debug where the problem actually was.
And I have trouble understanding how we got here in the first place: I was not against relying on SDP to ease the process of legacy interoperability, but we’ve added so much stuff to it in the meanwhile that (ignoring the ICE/DTLS stuff that few or no legacy endpoint supports anyway) this is not going to happen anyway.
Anyhow, I agree with Tim on his conclusion: WebRTC is great and promises to be even greater, and we shouldn’t give up on it just because of SDP. Let’s just hope that things will get simpler in that respect in the future.
Hi, I’m a ‘weekend pi hacker’ and was kind of looking forward to playing around with Webrtc datachannels but my initial Google for Java libraries isn’t inspiring too much confidence, do you have any recommendations/did you manage to write one and post it on github :-)?
Thanks,
Rob
Rob – no I didn’t get around to finishing my data channel stuff in Java (yet) – I think that
most of what you need is in libjitsi – but perhaps not all of it.
I am still working on the project, but it is very much on the back burner at the moment.
I’m also not completely sure it would be open source, since it has turned out to be quite hard to do.
The missing component is the sctp stack in java. I believe Jitsi used the one from the linux kernel and some jni – which works I guess, but isn’t what I had planned.
Tim.