Multi-party calling architectures are a common topic here at webrtcHacks, largely because group calling is widely needed but difficult to implement and understand. Most would agree Scalable Video Coding (SVC) is the most advanced, but the most complex multi-party calling architecture.
To help explain how it works we have brought in not one, but two WebRTC video architecture experts. Sergio Garcia Murillo is a long time media server developer and founder of Medooze. Most recently, and most relevant for this post, he has been working on an open source SFU that leverages VP9 and SVC (the first open source project to do this that I am aware of). In addition, frequent webrtcHacks guest author and renown video expert Gustavo Garcia Bernando joins him.
Below is a great piece that walks through a complex technology and yet-to-be documented features in Chrome’s WebRTC implementation. Take notes!
{“editor”, “chad hart“}

One of the challenges of WebRTC multiparty solutions has always been how to adapt the video bitrate the for participants with different capabilities. Traditional solutions are based on the Multi-point Control Unit (MCU) model. MCU’s transcode (fully decode the stream and then re-encode it) to generate a different version of the stream for each participant with different quality, resolution, and/or frame rate.
Then the Selective Forwarding Unit (SFU) model based on forwarding packets without any re-encoding began to become very popular. This was largely due to its scalable and relatively inexpensive server-side architecture. SFU’s were particularly popular for WebRTC. For the past couple of years, Chrome’s unofficial support for simulcast and temporal scalability within the VP8 codec provided one of the best ways to implement a WebRTC SFU. Simulcast requires the endpoints send two or three versions of the same stream with different resolutions/qualities so that the SFU server can forward a different one to each destination. Fortunately when enabling simulcast in Chrome you get support for temporal scalability automatically (explained below). This means the SFU can also selectively forward different packets to provide different frame rates of each quality depending on the available peer bandwidth.
However, simulcast does have some drawbacks – its extra independently encoded streams result in extra bandwidth overhead and CPU usage.
Is there something better? Yes. Scalable Video Coding (SVC) is a more sophisticated approach to minimize this overhead while maintaining the benefits of the SFU model.
What is SVC?
Scalable Video Coding (SVC) refers to the codec capability of producing several encoded layers within the same bit stream. SVC is a not a new concept – it was originally introduced as part of H264/MPEG-4 and was later standardized there 2005. Unlike Simulcast which sends multiple streams with redundant information and packetization overhead, SVC aims to provide a more efficient implementation by encoding layers of information representing different bitrates within a single stream. Use of a single stream and this novel encoding approach helps to minimize network bandwidth consumption and and client CPU encoding costs cost while still providing a light weight video routing architecture.
3 Layer Types
There are three different kinds of layers:
- Temporal – different frame rates.
- Spatial – different image sizes.
- Quality – different encoding qualities.
VP9 supports quality layers as spatial layers without any resolution changes, so we will only refer to spatial and temporal layers from now on.
The SVC layer structure specifies the dependencies between the encoded layers. This makes it possible to pick one layer and drop all other non-dependant layers after encoding without hurting the decodability of the resulting stream.
In VP9 each layers are defined by an integer ID (starting at 0). Layers with higher IDs have dependency on lower layers.
Encoding & SFU Selection
VP9 SVC produces a “super frame” for each image frame it encodes. Super frames are composed of individual “layer frames” that belong to a single temporal and spatial layer. When transmitting VP9 SVC over RTP, each super frame is sent in a single RTP frame with an extra payload description in each RTP packet that allows an SFU to extract the individual layer frames. This way, the SFU can select the only ones required for the current spatial and temporal layer selection.
Controlling Bandwidth
An SFU can downscale (both temporally and spatially) at any given full layer frame. It is only able to upscale on the escalation points signaled on the payload description header.
Downscaling a temporal layer will produce a decrease on the decoded frames per second (FPS). Downscaling on a spatial layer will produce a reduction on the decoded image size. Upscaling will provide the inverse effect.
Status of VP9 SVC in Chrome
Currently VP9 SVC is enabled in standard Chrome for screensharing only. However, VP9 SVC support for any encoded stream (at least since M57) can be enabled with a field trial command line parameter:
chrome --force-fieldtrials=WebRTC-SupportVP9SVC/EnabledByFlag_2SL3TL
If you do that, Chrome will SVC encode every VP9 stream it sends. With the above setting, the VP9 encoder will produce 2 spatial layers (with size and size/2) and 3 temporal layers (at FPS, FPS/2 and FPS/4) and no quality layers. So for example, if encoding a VGA size image (640×480) at 30 FPS, you could switch between the following resolutions and framerates:
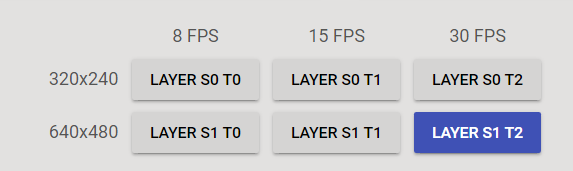
VP9 Payload format
Each RTP packet carrying a VP9 stream contains data from only one layer frame. Each packet also starts with a VP9 Payload Description. This payload description provides hints to the SFU about the layer frame dependencies and scalability structure.
Modes
Currently, Chrome Canary (58) uses 2 types of payload formats for VP9 SVC:
- Flexible mode – provides the ability to change the temporal layer hierarchies and patterns dynamically. The reference frames of each layer frames are provided on the payload description header. This mode is currently only used for screen sharing.
- Non-flexible mode – the reference frames of each frame within the group of frames (GOF) are specified in the scalability structure of the payload description and they are fixed until a new scalability structure is sent. This is currently the mode used for real time video.
Structure
This is the actual scalability structure of layer frame dependencies used by Chrome Canary for real time video in the non-flexible mode:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
<VP9ScalabilityScructure numberSpatialLayers=3 spatialLayerFrameResolutionPresent=2 groupOfFramesDescriptionPresent=1 > <SpatialLayerFrameResolution width=320 height=240/> <SpatialLayerFrameResolution width=640 height=480/> <VP9InterPictureDependency temporalLayerId=0 switchingUpPoint=0> <ReferenceIndex diff=4/> <VP9InterPictureDependency/> <VP9InterPictureDependency temporalLayerId=2 switchingUpPoint=1> <ReferenceIndex diff=1/> <VP9InterPictureDependency/> <VP9InterPictureDependency temporalLayerId=1 switchingUpPoint=1> <ReferenceIndex diff=2/> <VP9InterPictureDependency/> <VP9InterPictureDependency temporalLayerId=2 switchingUpPoint=0> <ReferenceIndex diff=1/> <ReferenceIndex diff=2/> <VP9InterPictureDependency/> <VP9ScalabilityScructure> |
The frame dependencies are required by the decoder in order to know if a frame is “decodable” or not given the previously received frames.
Dependency descriptions
Luckily, the payload description also provides hints for an SFU in order to decide which frames may be dropped or not according to the desired temporal and spatial layer it decides to send to each endpoint. The main bits of the payload description that we will be needed to check are:
- P: Inter-picture predicted layer frame, which specifies if the current layer frame depends on previous layer frames of the same spatial layer.
- D: Inter-layer dependency used, which specifies if the current layer frame depends on the layer frame from the immediately previous spatial layer within the current super frame.
- U: Switching up point, which specifies if the current layer frame depends on previous layer frames of the same temporal layer.
It is possible to up-switch up to a higher temporal layer on a layer frame which S bit is set to 0, as subsequent higher temporal layer frames will not depend on any previous layer frame from a temporal layer higher than the current one. When a layer frame frame does not utilize inter-picture prediction (P bit set to 0) it is possible to up-switch to the current spatial layer’s frame from the directly lower spatial layer frame.
Dependency Model
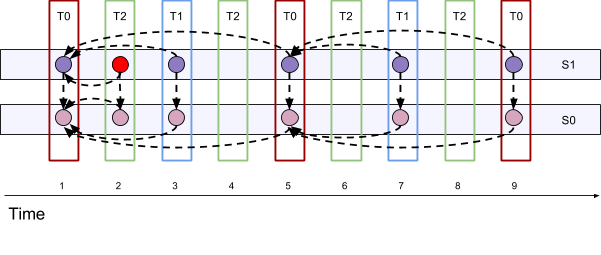
Now let’s us look as how an actual VP9 SVC encoded stream looks that was taken from a recent Chrome Canary capture. For each frame of the RTP stream we have decoded the payload description and extracted the representative bits and used the scalability structure to draw the layer frame dependencies.
It looks like this:

T indicates temporal layers. S indicates spatial layers. S0 and T0 are the base layers. Super frames 1 to 4 comprise a group of frames, as does 5 to 8. You can see that each layer frame of the spatial layer S1 is dependent of the S0 layer frame of the same super frame. Also, it is clear that the second T2 frame of each scalability group is not scalable as it depends on the previous T2 and T1 frames.
Examples of selective forwarding
Using this model, let’s see how layers are selected for a given frame.
Downscaling
Let’s then downscale to T1 S1 at the T2 S1 layer frame of super frame 2 (in red), the result is that the size is not changed but the FPS are halved as expected:
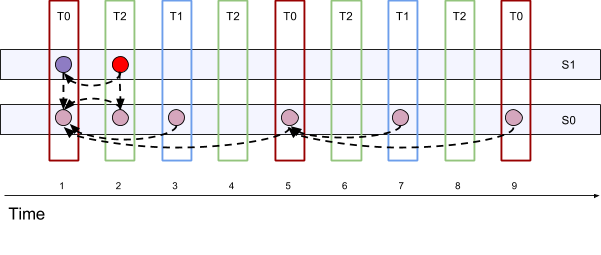
We could downscale further to T1 S0 at the same layer frame and the result will be a reduced image size (width and height halved) and also halved FPS:
Upscaling
To upscale temporally the SFU should have to wait for a layer frame with the switching point flag (U bit set to 1) enabled. In the non-flexible mode this happens periodically according to the scalability structure. The SFU needs to wait for a layer frame that is not an inter picture predicted layer frame (P bit set to 0) before it can upscale spatially.
One way the the SFU is able to force the encoder to produce a non inter picture predicted layer frame is by sending an RTCP feedback Layer Refresh Request (LRR) message or by a Picture Loss Indicator (PLI)/Full Intra Request (FIR). In our RTP example stream, we had to wait until frame 68 to see it. This happens to be initiated by an FIR between frames 67 and 68. Spatial layer S0 is not dependent on the previous temporal layer T0, so the scalability structure is restarted after that with a new Group of Frames.
So in the previous VP9 Stream the SFU will be able to upscale spatially on frame 68 and later temporally on frame 73.

What’s missing
Today it is possible to enable VP9 SVC in Chrome (including stable) by passing a command line flag and automatically getting 2 spatial layers plus 3 temporal layers (as illustrated above). There are at least four issues that Google needs to solve before they make it a default option:
- Decide the best combination of Temporal and Spatial layers when enabling VP9 SVC or provide an API to configure that (but that probably requires part of the new ORTC-like APIs that are not yet available).
- Provide a way to enable or disable SVC in a per session basis, so you can have a multiparty call with SVC and a 1:1 call using traditional VP9 to avoid the overhead of SVC encoding.
- Denoising (blurring of frames to remove imperfections) was disabled and it is still not yet enabled by default for VP9.
- CPU usage when using VP9 SVC is still very high – on mid to high end devices it takes some time to detect CPU overuse and scale down the resolution being sent.
Results / Demos
As stated earlier, the main goal behind using SVC codecs is to be able to generate different versions of a stream without having to transcode it. That means we need to generate many different stream versions of various bitrates to adapt to the changing bandwidth availability of the participants.
In the next figure we show a stream being sent at 2Mbps using VP9 SVC. With the 2SL3TL configuration above, we can generate 6 different versions by selecting different temporal and spatial layers. The lower layer (¼ resolution at ¼ frame rate) is around 250kbps and the other ones have more or less 200kbps difference between them.

You can test this by yourself using the new open source Medooze SFU or contact TokBox for further information on their VP9 SVC support.
Medooze has created also a demo to live test the VP9 layer selection that is publicly available here: https://sfu.medooze.com/svc/ Remember to enable SVC on Chrome in order to make it work properly!
{“Authors”: [“Sergio Garcia Murillo“,”Gustavo Garcia”]}





Hi Sergio. Fantastic blogpost! Now both Firefox and Chrome seem to support SVC by default which makes me wonder about this:
> Provide a way to enable or disable SVC in a per session basis, so you can have a multiparty call with SVC and a 1:1 call using traditional VP9 to avoid the overhead of SVC encoding.
We are exactly in this situation and I can’t find a way to disable SVC. Any ideas of how to do it?
Hi Alfonso,
AFAIK, SVC is still under a flag for Chrome :
https://chromium.googlesource.com/external/webrtc/+/master/media/engine/webrtcvideoengine.cc#341
Note that by default VP9 in both firefox and chrome are using a single temporal and spatial layer (tl0 and sl0), so SVC is off by default.
If what you want is to disable VP9 altogether, just mangle the SDP returned by the createOffer method.
The post says:
“To upscale temporally the SFU should have to wait for a layer frame with the switching point flag (Ubit set to 1) enabled.”
However the definition of flag U is:
“U: Switching up point, which specifies if the current layer frame depends on previous layer frames of the same temporal layer.”
So shouldn’t the SFU wait for a frame with U set to 0?
Also, after flags definition (P, D and U flags) the text says:
“It is possible to up-switch up to a higher temporal layer on a layer frame which S bit is set to 0, as subsequent higher temporal layer frames will not depend on any previous layer frame from a temporal layer higher than the current one. ”
No idea what the “S bit” is. Should it be “U flag” instead?
Yes, seems an editorial typo, the info is correct on the upscale section:
“To upscale temporally the SFU should have to wait for a layer frame with the switching point flag (U bit set to 1) enabled. ”
U: 1 -> frame does not depend on previous layer frames of same temporal layer, so upswitch is possible