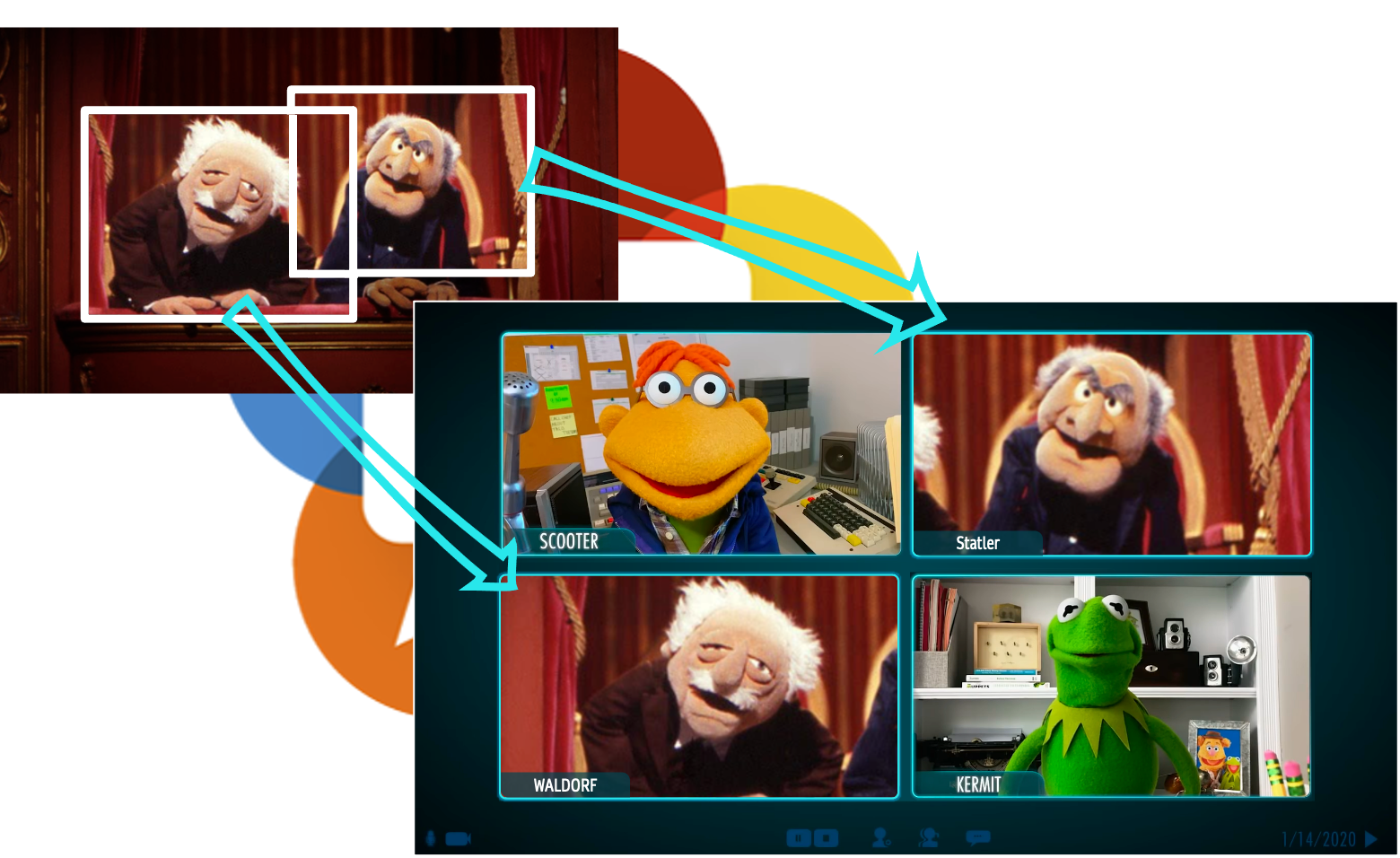
The pandemic has changed video conferencing. In the before times, it was the norm to have a room full of people in the office and a few remote participants. During the pandemic, everyone was remote. As a result, we’ve seen a massive increase in features like grid view that display a lot of participants at once.
These days some people are returning to the office. And sitting in those meeting rooms again. But our perception has changed. We have come to like the equality of everyone being displayed in their own video frame.
Zoom describes this nicely in the announcement for their smart gallery feature:

What if we could keep that experience? Fortunately, WebRTC in Chrome is aiming to provide an API that is well suited for this task. It is the MediaStreamTrack API for Insertable Streams of Media API, also known as breakout box. It follows a similar pattern as the insertable streams API we looked at last year to provide end-to-end encryption:

The API is currently being discussed in Chrome and there is an intent to ship being discussed on the blink-dev list. Which meant it was a good time to try it and check how it deals with use-cases such as the smart gallery.
The implementation
Our implementation has two main components:
- face detection to determine regions of interest
- cropping every video frame and creating one or more smaller video tracks from it
We’ll cover each in turn.
Face detection
We chose Google’s MediaPipe API for face detection. It is well documented and has a complete sample for face detection even. We decided not to use its Camera helper API as it is a bit too barebones and as heavy WebRTC users we are used to working with getUserMedia directly.
The initialization is pretty simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
let faces; const faceDetection = new FaceDetection({locateFile: (file) => { }}); faceDetection.setOptions({ model: 'short', minDetectionConfidence: 0.5, }); faceDetection.onResults(results => { console.log('update results', results); // For a real "product" one would have to track the different boxes and their // movement to prevent jumps. faces = results; }); |
We initialize it, let it load the model from the default CDN (which is not something you want to do in production obviously), and install a result handler that stores the results to a global variable. Next, we call getUserMedia, attach the resulting stream to a video element and periodically attempt to detect faces:
|
1 2 3 4 5 6 7 8 |
navigator.mediaDevices.getUserMedia({video: {width, height}}) .then(async (stream) => { localVideo.srcObject = stream; // Update face detection every two ѕeconds. setInterval(() => { faceDetection.send({image: localVideo}); }, 2000); }); |
How often you update the detection depends a bit on your use case. So far, that isn’t complicated. The library even provides debugging helpers that visualize the result.
One thing to note is that compared to our previous posts like Chad’s Computer Vision on the Web with WebRTC and TensorFlow one or my 2017 KrankyGeek talk on NSFW detection this no longer relies on a server for processing but is done fully in Javascript. The model size is reasonably small as well, mere 229 kilobytes to download.
Insertable streams
The previous example was incomplete. We actually need to do something with every frame. That is where the ” breakout box” API comes into play:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
if (!(typeof MediaStreamTrackProcessor === 'undefined' || typeof MediaStreamTrackGenerator === 'undefined')) { document.getElementById('notsupported').style.display = 'none'; navigator.mediaDevices.getUserMedia({video: {width, height}}) .then(async (stream) => { localVideo.srcObject = stream; // Update face detection every two ѕeconds. setInterval(() => { faceDetection.send({image: document.getElementById('localVideo')}); }, 2000); const [track] = stream.getTracks(); const generator0 = new MediaStreamTrackGenerator('video'); const generator1 = new MediaStreamTrackGenerator('video'); crop0.srcObject = new MediaStream([generator0]); crop1.srcObject = new MediaStream([generator1]); // to be continued... |
First, as with any new API you want to guard its usage with feature detection. Here we check for the existence of the MediaStreamTrackProcessor and MediaStreamTrackGenerator APIs. Then we call getUserMedia and create two MediaStreamTrackGenerator objects that, you might have guessed it from the name, can be used in some places a MediaStreamTrack can be used. We then attach those two generators to two video objects.
Why two? Because you might detect multiple faces and want to create multiple tracks. Doing this with multiple pairs of generators and processors is a bit more intuitive than using a single processor and multiple generators. Since the processors use the same underlying buffer the performance impact should be minimal.
Next, we create two MediaStramTrackProcessors, pipe them through a transform and into the generators, as we have done with encoded insertable streams last year:
|
1 2 3 4 5 6 7 8 9 10 11 |
const processor0 = new MediaStreamTrackProcessor(track); processor0.readable.pipeThrough(new TransformStream({ transform: (frame, controller) => transform(frame, controller, 0) })).pipeTo(generator0.writable); const processor1 = new MediaStreamTrackProcessor(track); processor1.readable.pipeThrough(new TransformStream({ transform: (frame, controller) => transform(frame, controller, 1) })).pipeTo(generator1.writable); }); } |
We use a single transform and tag it with an index.
The transform is where the magic happens:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
async function transform(frame, controller, index) { if (faces && faces.detections[index]) { //console.log('DETECTED', faces.detections.length, faces.detections, frame); const box = faces.detections[index].boundingBox; ctx.drawImage(frame, Math.min(Math.max( Math.floor(box.xCenter * frame.codedWidth) - boxWidth / 2, 0), frame.codedWidth - boxWidth), Math.min(Math.max( Math.floor(box.yCenter * frame.codedHeight) - boxHeight / 2, 0), frame.codedHeight - boxHeight), boxWidth, boxHeight, 0, 0, boxWidth, boxHeight); const newFrame = new VideoFrame(canvas); controller.enqueue(newFrame); } frame.close(); } |
We check if the faces variable is set, i.e. if the face detection has initialized and is yielding results. If so, we check if we have a detection result corresponding to the index. This implements support for multiple faces and segmented areas. If we have neither, we do not enqueue a frame so the resulting output stream will not be showing new pictures.
If we have a face detection result, we use an OffScreenCanvas and paint the frame to the canvas. This is where we choose the size of our bounding box. We use a fixed-width box centered around the current detection origin. This doesn’t fit all sizes but is much easier to understand than if we added features like re-scaling to the math. A way to crop (and re-scale) the frame as requested in this spec issue would be nice as this use-case seems pretty common.
Since we update the face detection every two seconds there will be small jumps that are quite noticeable. Finding a solution that provides a smooth output without too much movement is the challenging part of building an actual product. Overlapping boxes will also cause problems.
We enqueue the new frame that is created off the canvas and enqueue it. If you try this in Chrome 93 you might see a color distortion similar to the images below. This is a (now) known regression that should already be fixed.
Testing it
Try the demo here, the source code is available on github. It currently requires a recent Chromium-based browser with the “experimental web platform features” enabled in about://flags.
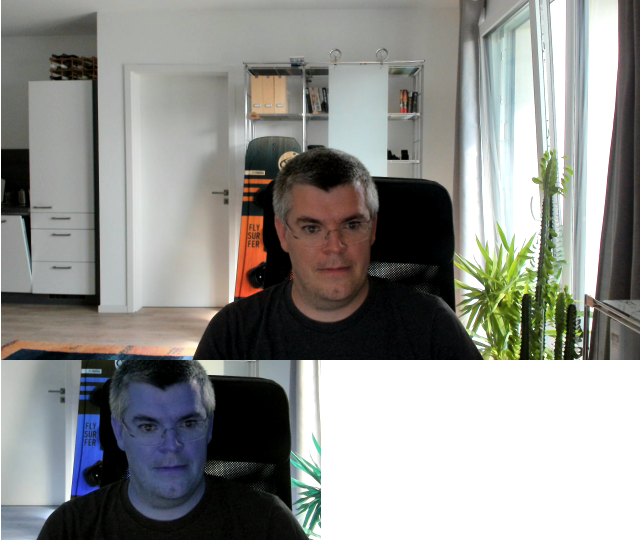
The demo allows you to get a good feeling for how things behave if you just sit in front of your computer or if you move around the room a bit. If you move too far away from the camera the face detection might stop working. That is certainly going to be an interesting point for larger meetings. How well the model detects people who are not looking into the camera is another question to ask.
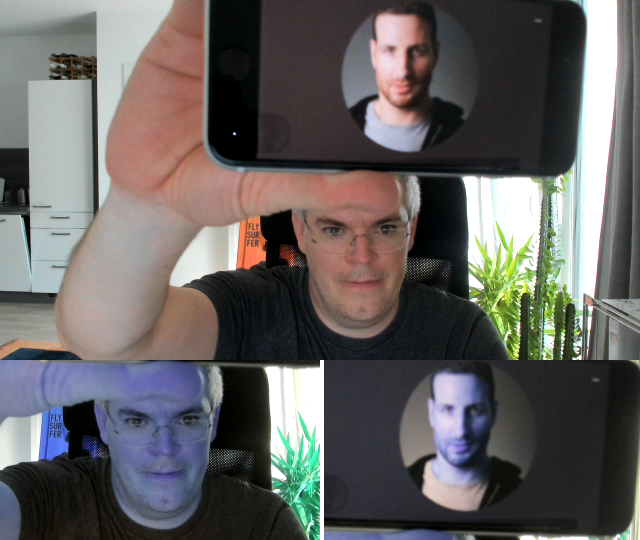
For testing with multiple persons, one can obviously invite friends. I wanted to show something with Chad, but unfortunately, we live quite far apart. So rather than having him fly here, I simply displayed his Twitter picture on my phone. Printed photos work quite well too.
One of the more interesting questions is what happens if someone leaves the room. This will cause the transform to no longer feed any frames into the generator. As a result, the generators change their muted states which can be detected with the mute and unmute events like this:
|
1 2 3 4 5 6 7 |
const [track] = stream.getTracks(); const generator0 = new MediaStreamTrackGenerator('video'); generator0.addEventListener('mute', () => console.log('first generator muted')); generator0.addEventListener('unmute', () => console.log('first generator unmuted')); const generator1 = new MediaStreamTrackGenerator('video'); generator1.addEventListener('mute', () => console.log('second generator muted')); generator1.addEventListener('unmute', () => console.log('second generator unmuted')); |
While this has a slightly higher delay than acting on changed results ourselves, it integrates nicely with the MediaStreamTrack API.
Summary
The smart gallery feature itself is a bit awkward. As you can see in the image above as well as in the screenshot in the Zoom post there may be some overlap between the boxes when two people are close to each other. It remains to be seen how well it is accepted and how it feels. It may cause some fun moments where you see a pot of coffee handed from one video to each other for sure. In the long run, more advanced techniques like Seam Carving as explained by Badri Rajasekar during KrankyGeek 2017 will be used to improve the experience.
This is a new use case and API that keeps me tinkering with WebRTC after all these years. As Tim Panton described it recently, the integration of WebRTC into the web platform is amazing, it only took me a couple of hours to write the essential code.
The MediaPipe library makes face detection in Javascript easy. The library’s integration with MediaStreamTracks could be improved a bit.
The MediaStreamTrack API for Insertable Streams of Media is a highly pleasant to use API for solving this problem which was a bit more complex than the simple background removal that only requires a single processor and generator. The whole sample takes less than 100 lines of Javascript and HTML. As with encoded insertable streams, Guido Urdaneta has been tremendously helpful whenever I had questions.
LGTM, ship it!
{“author”: “Philipp Hancke“}




Leave a Reply