Chrome recently added the option of adding redundancy to audio streams using the RED format as defined in RFC 2198, and Fippo wrote about the process and implementation in a previous article. You should catch-up on that post, but to summarize quickly RED works by adding redundant payloads with different timestamps in the same packet. If you lose a packet in a lossy network then chances are another successfully received packet will have the missing data resulting in better audio quality.
That was in a simplified one-to-one scenario, but audio quality issues often have the most impact on larger multi-party calls. As a follow-up to Fippo’s post, Jitsi Architect and Improving Scale and Media Quality with Cascading SFUs author Boris Grozev walks us through his design and tests for adding audio redundancy to a more complex environment with many peers routing media through a Selective Forwarding Unit (SFU).
{“editor”, “chad hart“}

Fippo covered how to add redundancy packets in standard peer-to-peer calls without any middle boxes like a Selective Forwarding Unit (SFU). What happens when you stick in a SFU in the middle? There are a couple more things to consider.
- How do we handle conferences where clients have different RED capabilities? It may be the case that only a subset of the participants in a conference support RED. In fact this will often be the case today since RED is a relatively new addition to WebRTC/Chromium/Chrome.
- Which streams should have redundancy? Should we add redundancy for all audio streams at the cost of additional overhead, or just the currently active speaker (or 2-3 speakers)?
- Which legs should have redundancy? In multi-SFU cascading scenarios, do we need to add redundancy for the SFU-SFU streams?
Here we will discuss these questions, present what we recently implemented in Jitsi Videobridge, and share some more test results.
Mixing RED clients with non-RED clients
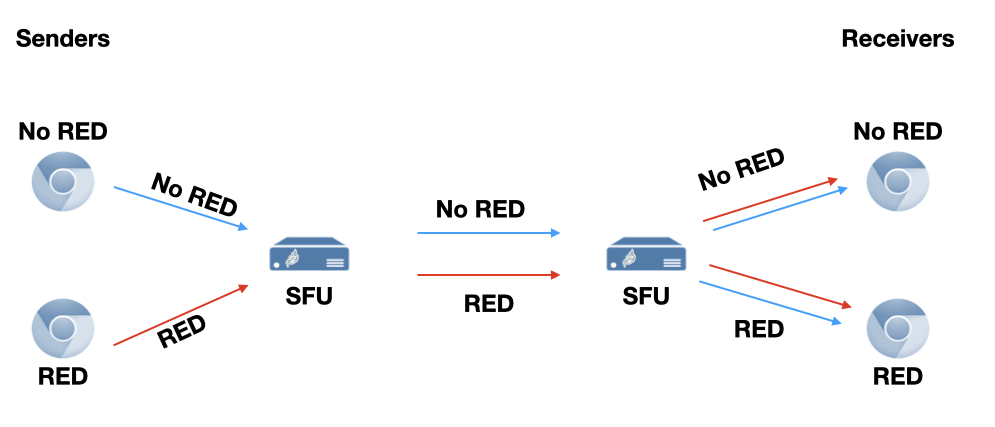
If all clients in the conference support RED, they can use it without any special handling on the server — the SFU just forwards audio streams as usual and they happen to contain redundancy. However, things get more interesting when some clients in a conference support RED and some do not. We need to consider four cases, based on whether the sender and/or receiver support RED:
- non-RED to non-RED
- RED to RED
- non-RED to RED
- RED to non-RED
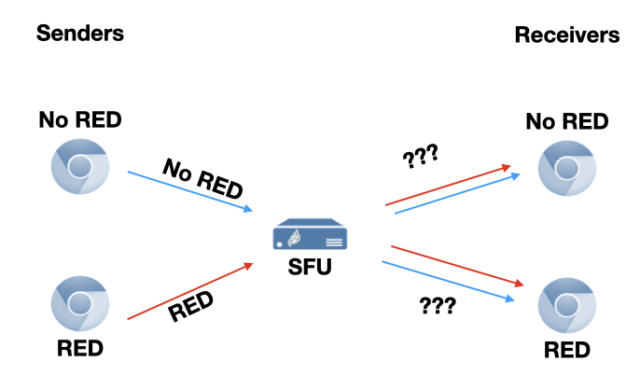
non-RED to non-RED
The first case is trivial: forwarding a stream from a non-RED client to a non-RED client. There’s no redundancy on the stream, and we are not allowed to add any. There is nothing we can do.
RED to RED
The second one is also simple: forwarding a RED stream to a client that supports RED. The easiest thing to do is to simply forward the stream unchanged, and it is also a reasonable solution. There’s no reason to re-encode the RED stream so we just forward it through.
non-RED to RED
The last case for the SFU is forwarding an Opus stream to a client with RED support, i.e. encoding RED. This reduces to the one-to-one case covered in Fippo’s article, with the addition of the limitation described below.
RED to non-RED
The third, more difficult case is forwarding a RED stream to a client without RED. Of course we can just strip RED and discard the redundancy, but that would not help improve the audio quality in case of packet loss between the SFU and client. This uncovers an interesting limitation of the RFC2198 RED format. In order for a middlebox SFU needs to produce a valid stream of RTP packets, it needs to know which RTP sequence number to use for packets recovered from redundancy blocks. Unfortunately, this information is not contained in the RED headers. This is because the format was designed to be interpreted by an endpoint and not an middlebox, where the timestamp is sufficient for playback, so only a “timestamp offset” (TO) field was included:
|
1 2 3 4 5 6 7 8 9 |
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |F| block PT | timestamp offset | block length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
If we always use distance 1, that is having one redundant packet (see more about distance in Fippo’s post), this is not a problem for the SFU. All RED packets have a single redundant block and its sequence number is the one preceding the RED packet’s sequence number. Similarly, if we always use distance 2 (two redundant packets) and add redundancy for all packets, there is no problem. The problem comes when the stream uses distance 2 with added redundancy only for packets that contain voice activity (the VAD bit is set).
VAD is bad (for RED)
Suppose the original stream has three packets (seq=1, 2, 3), one containing voice and the others no voice (no VAD). When the RED encoder processes packet 3, it adds redundancy for packet 1 only, because packet 2 contains no voice:
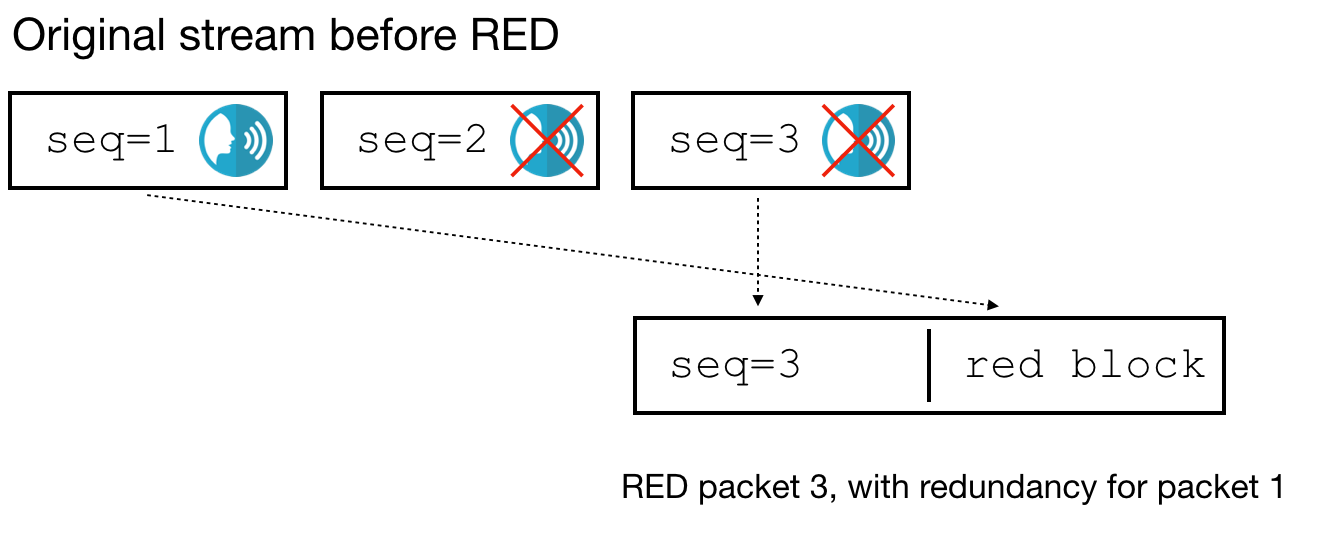
The problem is: when we receive such a packet on the SFU, how do we know whether the RED block contains a copy of packet 1 or packet 2? If the encoder is using distance 1, or the voice flag in packets 1 and 2 is flipped, the RED packet looks the same, but contains redundancy for packet 2 instead:
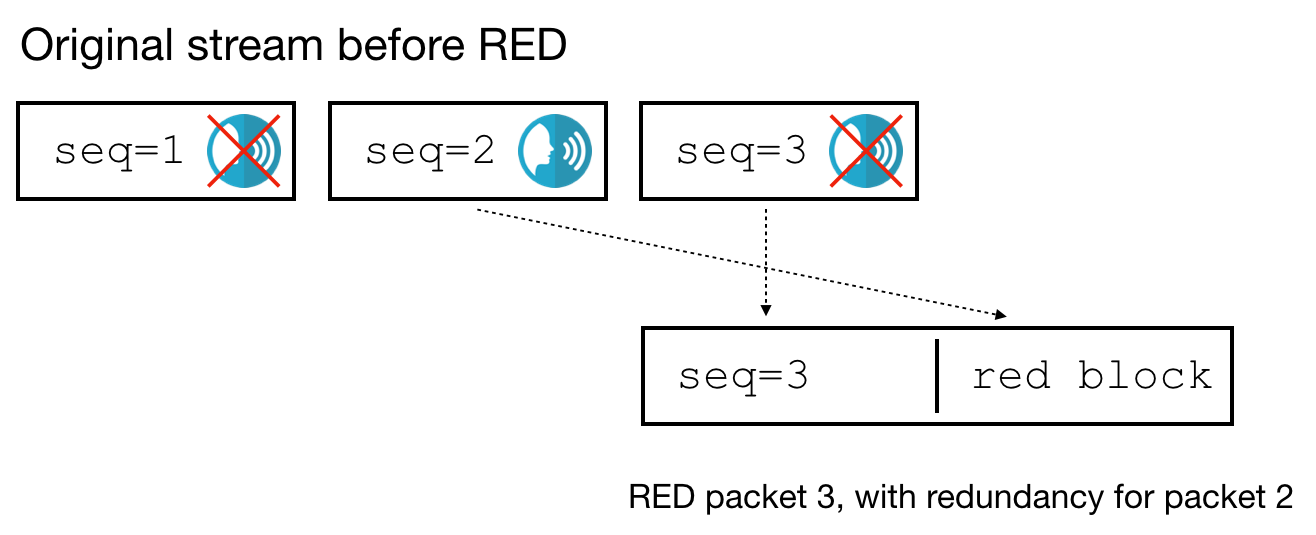
When we extract redundancy from a RED packet on the SFU, how do we decide what sequence number to use for it? One way is to look at the timestamps and make some assumptions about the packets’ duration. Since we use Opus with RTP clock rate 48000 and 20 ms frames, we can use red_seq = seq - timestamp_offset * (20 / 48000) . This makes a lot of assumptions. We could get fancier and read the duration of the Opus packet, so we don’t have to assume it’s 20 ms, but this has other problems:
- it will not work for e2e encrypted streams,
- it is codec-specific,
- technically opus streams can change the frame-size mid-stream.
Changing RED
We were not able to find a good resolution within the current specification. Instead, we added a new limit to the RED encoder sequence counter that makes sure that redundancy packets always have sequence numbers directly preceding the primary packet’s sequence number. For the example streams above, the RED encoder has three valid options:
- Don’t add redundancy
- Only add redundancy for packet 2 (second diagram)
- Add redundancy for both packets:
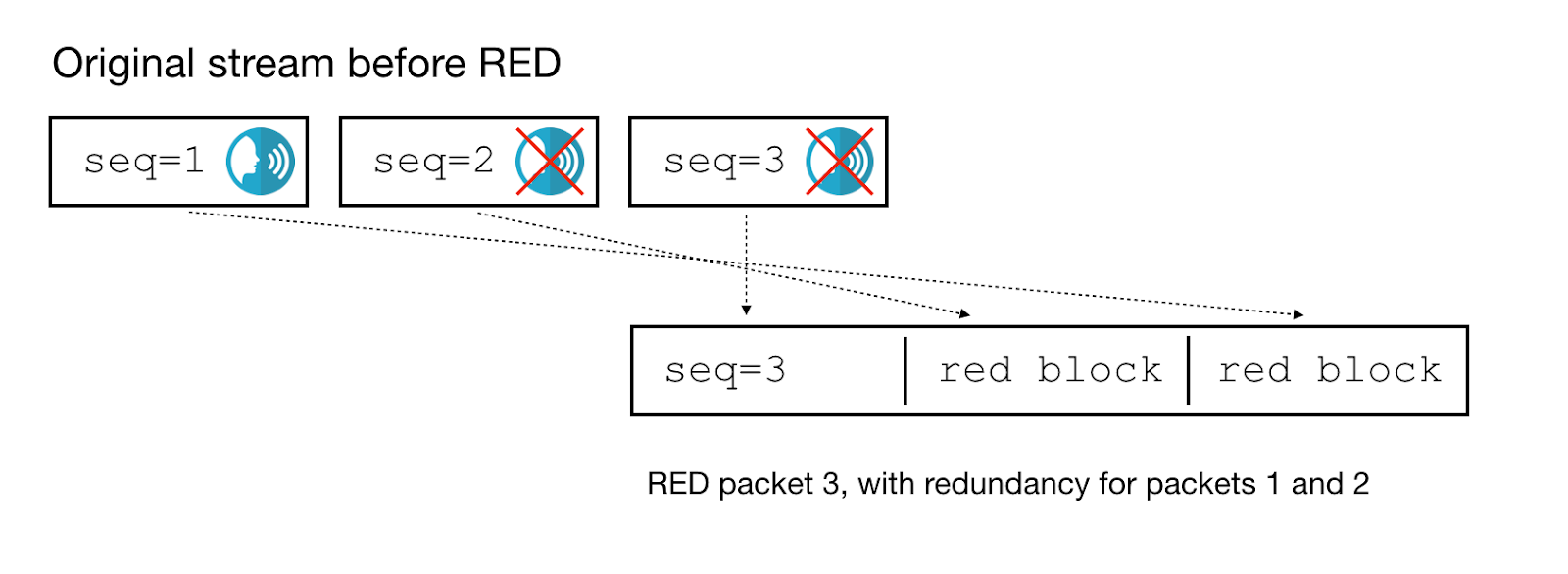
The option from the first diagram – add redundancy for packet 1 but not packet 2 – is no longer allowed. This is what Fippo’s latest patch to the WebRTC source implements.
Should all streams have redundancy?
In the one-to-one case the overhead of RED is small relative to the combined bitrate when video is also used. For a typical Opus stream of 32kbps, RED with distance 2 adds about 64kbps of overhead. A typical video stream in our service uses 2Mbps so the overall overhead is on the order of 3% – not insignificant, but relatively small.
However, in a multi-party conference when the SFU forwards multiple streams to each receiver and many of the video streams are low-bitrate (thumbnails) the overhead might become more significant.
We started our implementation with the simplest technical solution — add redundancy for all streams and assume most conferences have a small number of simultaneous speakers. Since the SFU doesn’t forward audio marked as silence, few simultaneous speakers means few audio streams. So in most cases each participant would only receive RED on a few audio streams, limiting the overhead. In fact, in our data from meet.jit.si, 78% of the time conferences have three or fewer speakers (i.e. streams with a non-zero audio level) so in most cases there is not much potential for RED overload at the receiving end points.
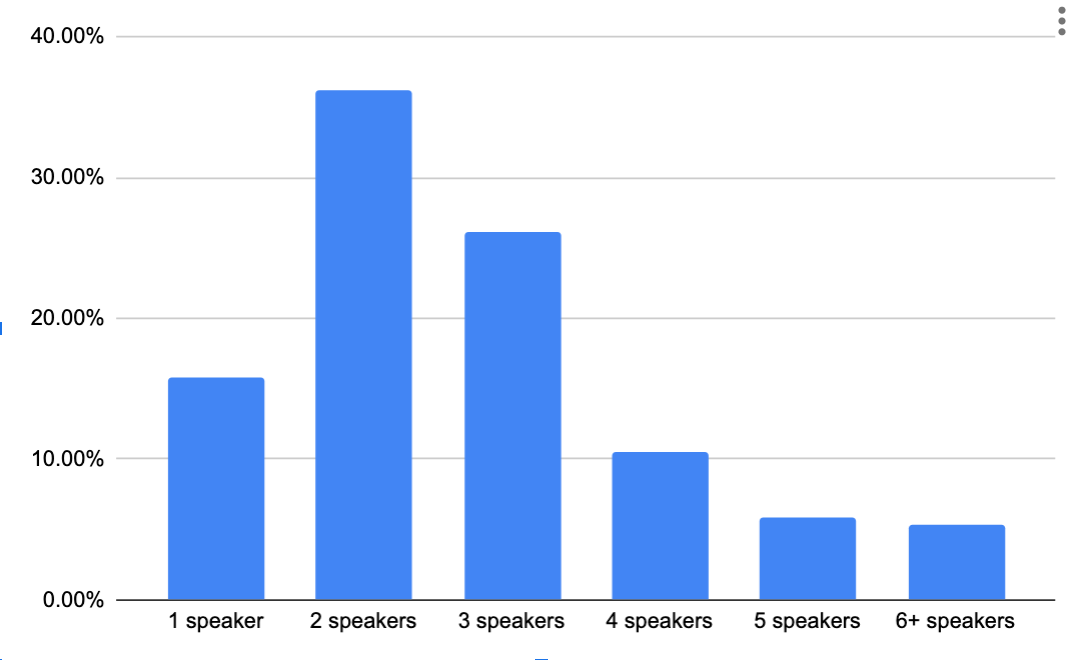
What else could we do to further reduce overhead in the future? We could add redundancy only for the active speaker, or the top 2-3 active speakers. In addition, we could also make more complicated decisions based on the available bandwidth and the video streams in the conference.
Cascaded SFUs
Another consideration is how to handle RED in the cascaded SFU case where we have SFU to SFU connectivity for better scale. In our deployments we have stable, high-bandwidth links with no significant packet loss between the SFUs. For this reason we chose not to actively add redundancy to streams that don’t have it. However, we don’t remove it either, since we have plenty of low-cost bandwidth. So the final flow looks like this:
Test results
To validate the new RED functionality, we created a test bed to measure how well the system behaves under different packet loss scenarios. Our default configuration was set to a distance=2, vad-only=true for the streams encoded on the SFU. We introduced 20%, 40% and 60% uniform packet loss to either of two links – (1.) between the sender and SFU and (2.) between the SFU and receiver. The location of packet loss did not make any noticeable difference. You can listen to all the test cases here and listen to the sender-side losss examples below:
| Packet Loss | Normal | With RED |
|---|---|---|
| Reference | N/A | |
| 20% | ||
| 40% | ||
| 60% |
As you can hear, there is a significant qualitative improvement with RED present.
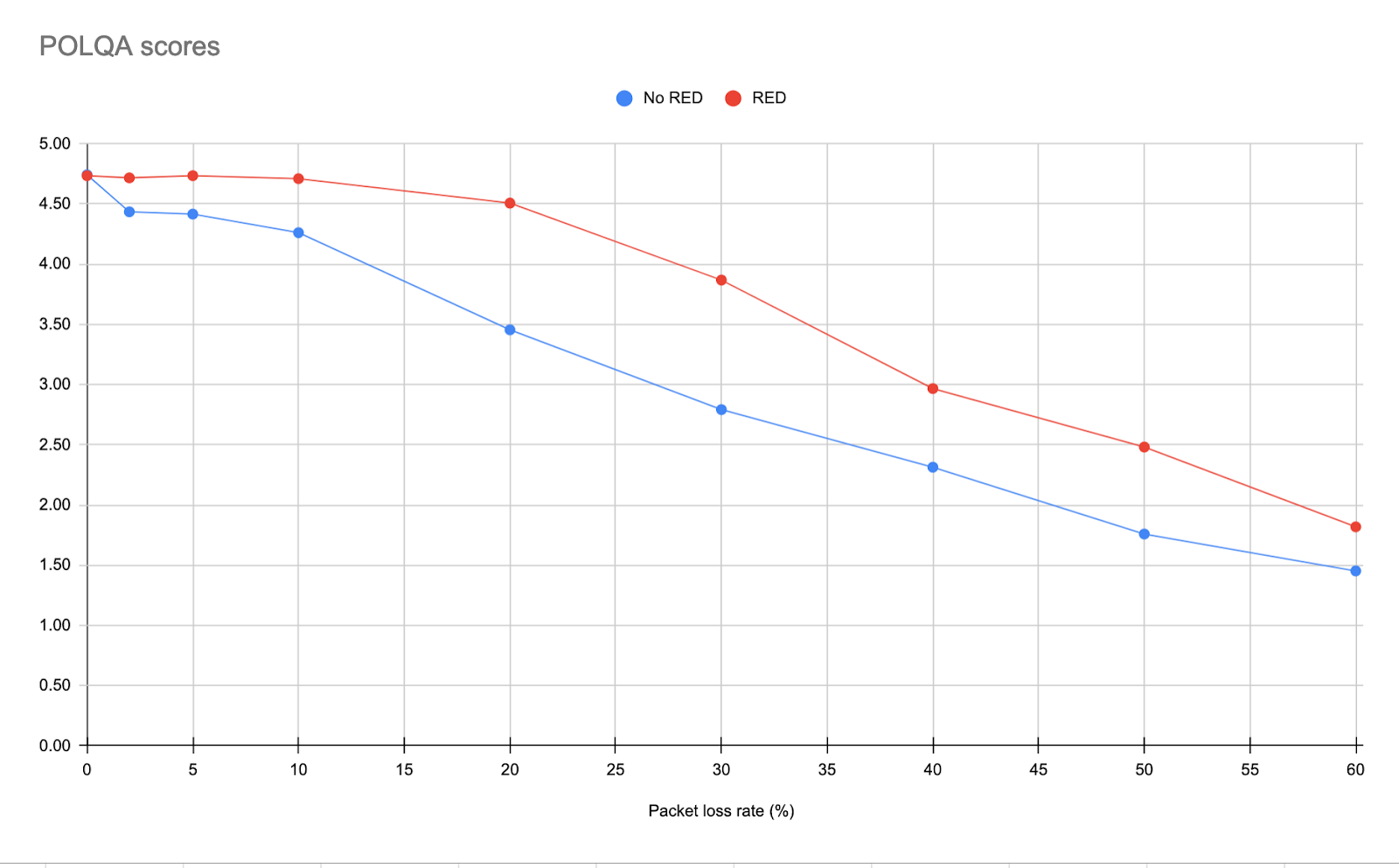
POLQA tests
In a separate experiment with a similar setup, my 8×8 colleague Garth Judge quantified these effects using the POLQA standard and toolset. Here are his results results:
Conclusions
The recently implemented field trial of WebRTC audio redundancy using the RED standard in Chrome shows significant promise. Using RED effectively in a multiparty conferencing environment requires additional server support on the SFU. Our tests show these SFU enhancements for RED yield practical results.
There is more work to be done in choosing a subset of the streams for which to add redundancy, using VAD to select which packets to add, and potentially using Opus Low Bit-Rate Redundancy (LBRR) to reduce the additional bitrate that redundancy introduces.
Tests in the lab show that audio quality under heavy packet loss is improved significantly. Stay tuned for the real world results!
{“author”, “Boris Grozev”}





Thanks for sharing this!
Does does it make sense to do the same for video streams in vp8 and vp9 codecs ?