
Most folks that set out to write an application, or build an architecture, begin with nothing but features and functionality in mind. Many might start out assuming they will be traversing flat, reliable, and secure networks. Inevitably, reality sets in as one starts to demo or prototype much beyond the friendly confines of the lab, and suddenly you begin finding scenarios not working properly, quality issues cropping up, or your stuff gets hacked. “Phase 2” of the design emerges, backing in all the necessary tools to cover the gaps.
Thankfully, WebRTC comes equipped with a pretty robust set of tools built right into the engine, which can allow a web developer to remain relatively oblivious when their WebRTC call “just works”. In the standards work behind WebRTC , these tools are still being defined as we speak. This entry will hopefully be the first of several examining these tools in greater detail. It’s true that the goal of WebRTC is to sufficiently abstract these tools from a web developer, so they don’t have to care. But for those who are curious, those possibly building media stacks to work with WebRTC, or perhaps those struggling to troubleshoot WebRTC interoperability issues (gasp!)…we’ll begin by looking at how WebRTC deals with the problem of NAT and Firewall traversal, using a trio of tools called ICE, STUN, and TURN.
To best understand these tools, I think it’s best to start with the basics of NAT. If you are already a NAT expert, bear with me since this will be a superficial review. As we discuss the tools of WebRTC in future posts, I want to make sure the challenges and reasons for having the tools are properly introduced and understood – particularly for developers not used to thinking about what’s going on over the network when they make a PeerConnection.
What is NAT?
NAT stands for Network Address Translation (https://en.wikipedia.org/wiki/Network_address_translation). It is a widely used mechanism for preserving precious IPv4 addresses and giving local network admins control of their local topology. There is actually quite a wide variety of NAT’ing techniques, but without going into too great of detail, the most common NAT device works by changing IP header information of packets passing through it. It is also often the case, such as in most home routers, that NAT’ing is done in conjunction with Firewalling. These common home routers often kill two birds with one stone, providing security and preserving IPv4 address space at the same time. But as we will see, this can also cause problems for some applications and protocols, especially those like WebRTC that attempt to communicate Peer-to-Peer.
A common NAT/Firewall scenario is one featuring a private, or protected subnet of IP endpoints, separated from the wilds of the public Internet.
Typically a host on the LAN can send a packet to a host on the Internet, but firewalling occurs when any packet from the Internet tries to reach a host on the LAN. In other words, the NAT/Firewall device blocks the packet from passing through. Clearly this creates a problem, because if no packets could come from the Internet to a host on the LAN, WebRTC and any other IP based communication would not work.
A Typical NAT Scenario
Thankfully most firewalls will allow certain packets from the internet to pass, but only when a host from the LAN has sent a packet out through the firewall first. Essentially, the communication must be initiated by the host on the LAN. At the same time, for the packets proceeding through the NAT/Firewall device, it will apply a NAT to the packet. Lets look at an example: Hopefully you know that every packet on the wire has a five-tuple of key TCP/IP information: source IP, source port, destination IP, destination port, transport protocol (UDP/TCP/SCTP). As the packet passes through the NAT/Firewall device, it changes the source IP and source port of the packet, to a new source IP and source port. It then saves this binding between the “inside” source IP and source port, and the “outside” source IP and source port. This is known as a NAT binding, and the NAT/Firewall stores this mapping in a table.
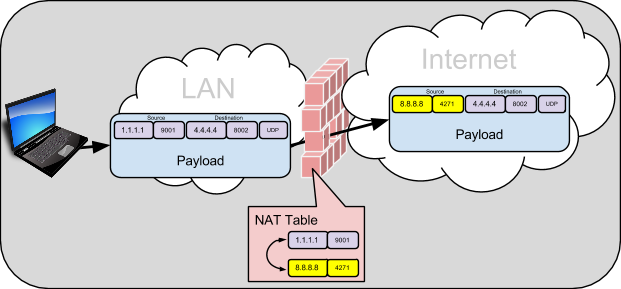
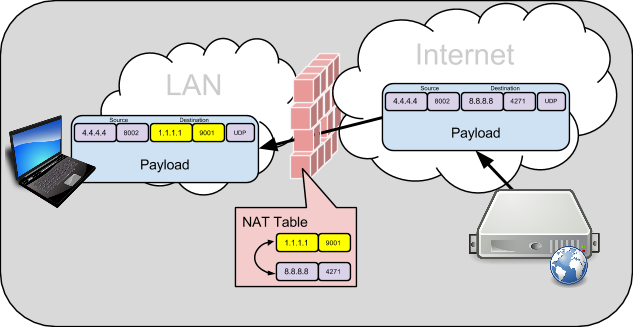
Hosts out on the Internet will only see and know of the changed “outside” IP:Port. If a host on the internet learns of this outside IP:Port, and wants to send packets to it, they will first arrive at the NAT/Firewall device. The NAT/Firewall device will do a look-up in it’s NAT Table, and based on the NAT binding, forward the packet to the inside host by changing the destination IP:Port.
This is fairly common NAT/Firewall behavior, and it doesn’t cause trouble for most client/server communications. The host behind the NAT typically punches a hole out through the Firewall with a request, and the server can simply respond to the IP:Port of the packet it received. Both client and server host would not even know there was a NAT/Firewall in between.
NATs and Peer-to-Peer: What’s the Problem?
While client/server communications works well through NAT/Firewalls, it wreaks havoc on peer-to-peer communications. Peer-to-peer typically works by endpoint applications opening up, or listening with a particular IP:Port on the host operating system. It can then communicate or signal to another host, what IP:Port it is prepared to exchange data on. The signaling of the application’s peer-to-peer IP:Port is typically done separately from the actual peer-to-peer data, using a server or possibly some other peer discovery mechanism. Here is an example:
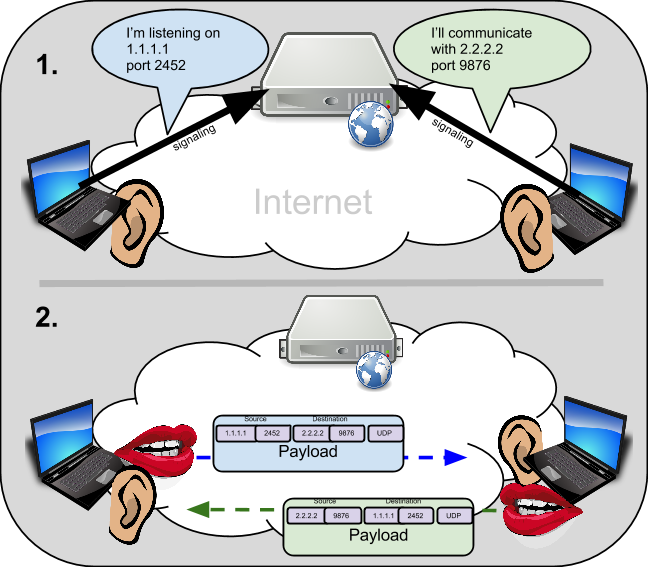
This is all well and good when no NAT/Firewall devices are around. However, in many cases where the World Wide Web is used to communicate, it is likely there are NAT/Firewall devices between the endpoints. What is more, the endpoint has no way to know what sort of network topology is between itself and the peer it wants to communicate with. So, when it signals that it wishes to communicate on an IP:Port at the local host operating system, it would be completely unaware that the signaling connection info it provides for the other endpoint will be blocked by its Firewall. Additionally, the address being reported by the endpoint is not even reachable by the other peer because of NATs in between. In other words, the endpoint THINKS it is reachable on one address, but because of NAT, the rest of the world outside the NAT only knows about, and can reach the NAT device address. Because the peer doesn’t know the topology, it may be signaling bad connection information.
Here is a look at the same example, with NAT/Firewall devices involved:
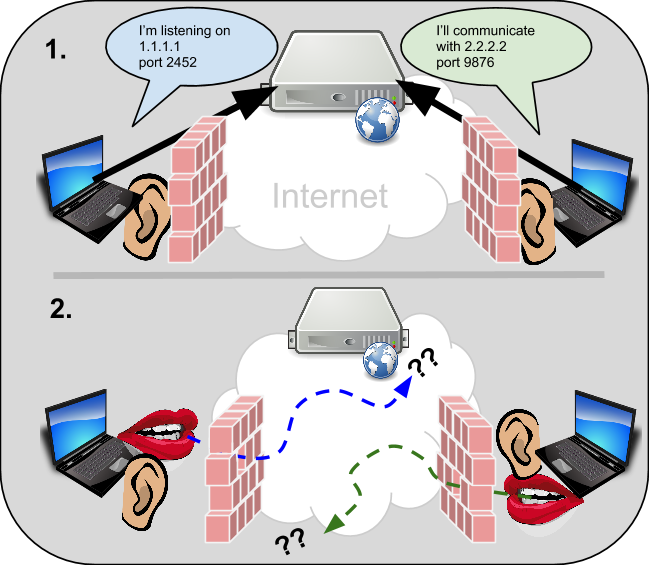
Clearly having NAT/Firewall devices involved results in an epic fail for peer-to-peer communications in this case. And this is only one possible topology scenario that might exist. In reality, many combinations of NAT types, firewalls, and topologies are possible scenarios that could cause the peer-to-peer connection to fail in different ways. So, what’s a peer to do?
WebRTC tools for NAT/Firewall Traversal
Peer-to-peer communications is essential for many (maybe most) WebRTC applications to minimize latencies and server-side costs. We have properly introduced the serious challenges that NAT/Firewall devices pose to peer-to-peer communications, so WebRTC must have mechanisms to overcome these challenges. The mechanisms for WebRTC need to provide the browser with a few key capabilities:
- Learn as best it can, the topology between itself, and the peer it wants to communicate with
- Establish connectivity on the best path through a given topology
- Have a fallback mechanism if all else fails.
WebRTC standards require the use of three IEFT NAT traversal standards to address these issues:
- Interactive Connectivity Establishment (ICE) – RFC 5245
- Session Traversal Utilities for NAT (STUN) – RFC 5389
- Traversal Using Relay NAT (TURN) – RFC 5766
Every WebRTC session requires the use of these tools when communicating with peers. Once the WebRTC sessions is properly signaled, and accepted, the process of NAT/Firewall discovery and traversal begins. When it is finished, a communication path is established and media can flow. Thanks to these tools, a good chunk of the problematic topology possibilities can be dealt with, and WebRTC can just work.
However, still not all cases are covered. If you have spent much time relying on WebRTC, you may have encountered times when no talk path was able to be established. The scenarios described in this post are the more common home broadband router cases, and they tend to be relatively easy for STUN, ICE, and TURN to overcome. Restrictive NATs and Firewalls found in enterprises, or hotel or courtesy WiFi hotspots can still cause issues.
At this point, I realize I have spent most of an entire post talking about why NAT and Firewalls can kill peer-to-peer communications like WebRTC…and just begun to scratched the surface of how ICE/STUN/TURN mechanisms for WebRTC avoid this fate in most scenarios. In subsequent posts, we will get into the details how these tools work, and some of the more problematic scenarios for them to overcome.
{“author”:”reid“}



Thank Reid! Excellent article focusing one some of the key challenges of bringing WebRTC to the masses. I look forward to your follow-up posts when you dive further into the world of ICE/STUN/TURN.
Thanks, excellent article. You indicate that NAT & Firewall exist only for preserving precious IPv4 addresses. Does that mean that one might not these NAT traversal mechanisms if once chooses to move to IPv6? Gradually everyone will be forced to move to IPv6 (though very, very slowly), so then ICE, STUN and TURN are not required practically once everyone moves to IPv6?
Hi sthustfo! You point out an interesting topic. Certainly the need for address conservation goes away with IPv6, so address translation may very well go with it. However, many feel that the security mechanisms of the firewall will still exist in an all IPv6 world. Perhaps the topology discovery component of these tools will be made much easier, but likely the connectivity establishment and fallback may still be needed to traverse firewalls.
Reid, thanks for the clarification. From your response, I deduce that – Even with IPv6, the NAT might go away but firewall will still persist for security reasons. And ICE, STUN & TURN would still be required for firewall traversal in such a scenario also.
Please correct me if my understanding above is correct or not. I just am trying to understand the relevance of these webrtc protocols in an IPv6 world.
Yep, I would agree with your understanding. I think ICE will definitely play an important role in an IPv6 world.
thanks a lot Reid for this good article! But I want to ask a little question i built a webRTC app an i’ve set up STUN/TURN server for NAT traversal but it still not work when clients are connected to internet with 2 different routers. So what can be my problem here?