WebRTC’s peer connection includes a getStats method that provides a variety of low-level statistics. Basic apps don’t really need to worry about these stats but many more advanced WebRTC apps use getStats for passive monitoring and even to make active changes.
Extracting meaning from the getStats data is not all that straightforward. Luckily return author Balázs Kreith has a solution for that. Balázs is the lead developer of the open-source WebRTC monitoring project, ObserveRTC. Within that project, the client-monitor-js repo has become its most popular. client-monitor-js aggregates getStats data into a more useful form, directly inside your JavaScript client.
In this post, Balázs shares some of his learnings building this tool. After some intro and background to the WebRTC Statistics API, he provides useful insights with code for using getStats data for common WebRTC issues – network congestion, CPU overuse, stuck tracks, and frozen video. Check it out below!
Many thanks to Vittorio Palmisano for his technical review help.
{“editor”, “chad hart“}

Contents
- WebRTC Stats Introduction
- Making effective use of getStats
- Detecting common WebRTC client issues
- Conclusion
This blog post explores how to effectively use WebRTC stats to identify, detect, and expose common issues such as video freezes, and network congestion. We will look at the getStats API and show where additional aggregation is needed for in-depth analysis. As a reference, I will use the client-monitor-js from the ObserveRTC project, an open-source tool that helps to collect and use WebRTC-related stats in your web-client code.
WebRTC Stats Introduction
As you delve deeper into WebRTC, you will explore the WebRTC Statistics API – better known as getStats – to understand underlying RTC performance metrics. getStats provides detailed metrics about the RTCPeerConnections that facilitate RTC communications. Monitoring these performance metrics and usage statistics can offer invaluable insights into the efficiency and effectiveness of your WebRTC applications.
getStats outputs different reports such as inbound-rtp, outbound-rtp, remote-inbound-rtp, and more. Each report contains specific metrics relevant to the media streams, data channels, and peer connection states. For instance, inbound-rtp reports provide information about received streams, including bytes received, packets lost, jitter, and frames per second for video. outbound-rtp reports include details about the sent streams, such as bytes sent, packets sent, and bitrate. Additionally, remote-inbound-rtp reports give insights into the receiving end, reporting metrics like round-trip time (RTT) and packet loss. Understanding and analyzing these stats can help developers optimize performance, troubleshoot issues, and enhance the overall quality of their WebRTC applications.
Here are some of the major stats you should care about:
- Round-Trip Time (RTT) – low latency is essential for real-time applications, as it affects the timeliness of communication.
- Packet Loss – lost packets directly impact audio and video quality; monitoring helps adjust quality dynamically.
- Jitter – indicates the variability of packet arrival times, affecting the stability of audio and video streams.
- Bandwidth Usage – understanding this helps optimize data flow and maintain efficiency, especially under bandwidth constraints.
- Frame Rate and Resolution – key indicators of video quality that affect user satisfaction that are typically adapted based on network conditions and device capabilities.
Regularly tracking these stats facilitates quick diagnostics and troubleshooting and can also be used to ensure optimal operation.
Previewing stats with built-in browser tools
In addition to programmatically accessing these stats via the WebRTC API by calling getStats() on RTCPeerConnection object, browsers also expose them (or variants of them) via their own built-in debugging tools:
- Chrome – load chrome://webrtc-internals in the URL bar
- Edge – load edge://webrtc-internals in the URL bar
- Firefox – load about:webrtc in the URL bar
- Safari – you need to enable WebRTC Logging in the Developer Settings; webrtcHacks’ Reeling in Safari on WebRTC post mentions how to do this
RTCPeerConnection.getStats API overview
When you invoke getStats on a PeerConnection, it retrieves an array of statistics objects. Each object represents a different aspect of the RTC connections and offers a comprehensive set of base metrics. For example, the inbound-rtp stats object consolidates all data relevant to receiving an RTP stream, including:
- Total bytes and packets received associated with a specific SSRC
- Forward Error Correction (FEC) packets that may have been sent to the stream
- Concealed samples count for audio streams
- Picture Loss Indicators (PLI) count for received video streams
Understanding all the metrics available may seem overwhelming at first, but starting with a few of the basic ones can really help you monitor the health of a stream effectively. With some simple adjustments, these key metrics can provide valuable insights into the performance and stability of your stream. Once you have the basics established, then you will find you can use getStats to go much deeper to start detecting common client issues.
Making effective use of getStats
getStats provides a snapshot of various statistics at a given point in time. It is up to the developer to:
- calculate how these values change over time,
- performance statistical measures over samples – like averaging,
- identify problematic thresholds, and
- report issues back to other parts of the system or display them to users.
As you get more advanced, a wrapper for getStats becomes helpful to:
- Reduce stats collection overhead – you can slow down your app if you collect these too often,
- Calculate derived metrics like bitrate variations and packet loss as a percentage of all traffic (fractional loss)
- Manage event reporting to your application and observability systems
- Provide a consistent reporting methodology within your application and across applications
The client-monitor-js project
client-monitor-js is the getStats wrapper I wrote for the ObserveRTC project. It is available in a straightforward npm package that is simple to integrate into your WebRTC application. client-monitor-js can detect potential client issues using “detectors”. These detectors emit anomaly events, helping your app to proactively manage and effectively troubleshoot streaming quality issues. Additionally, you can create a snapshot of the collected stats and send it to your server as samples for later analysis.
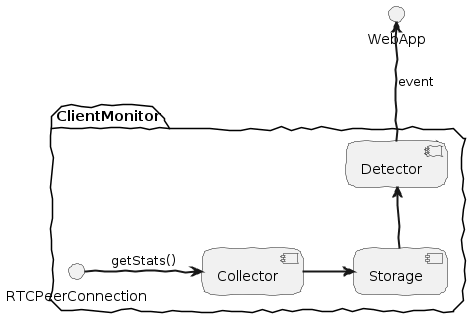
Detecting common WebRTC client issues
Now let’s get into some specific details of common issues encountered in WebRTC implementations and provide guidance on how to detect them. Each issue is linked to specific getStats properties that can be monitored to identify problems. The issues covered include:
- Congested Network – Identifying signs of network congestion that can affect stream quality.
- CPU Limitation – Spotting performance degradation due to insufficient CPU resources.
- Stucked Inbound RTP Flow – Understanding how to detect when RTP does not start flowing.
- Frozen Video – Detecting interruptions that cause video streams to freeze.
I will explain the relevant getStats properties, problem detection, and the potential implications for each of these issues.
Network Congestion
Network congestion is a topic I find particularly fascinating. Congestion occurs when an endpoint’s data output exceeds the available network bandwidth. As a result, routers may drop packets, leading to missing audio and video data on the remote client’s end.
Types of Congestion
Over the years, I’ve explored various methods to detect and respond to congestion at both the low-level RTC transport layer and the higher-level application layer. The key difference between these layers lies in the timing of congestion detection. In low-level streaming, monitoring is granular, relying on RTCP feedback intervals (typically 20-40ms), allowing for the detection of incipient congestion. In contrast, high-level application layer detection relies on getStats polling and RTCP Receiver Report intervals, meaning detection often occurs after congestion has already had some performance impact.
To simplify, low-level detection occurs during congestion, while high-level detection happens mostly after congestion has started (and possibly finished). Consequently, the reactions differ: at the low level, the focus is on adjusting the bitrate to avoid serious quality degradation. At the higher level, the response might involve informing the user. If congestion is severe enough, the app may even forcibly shut down sources (such as stopping media tracks) to address the problem.
Congestion Detection Challenges
At the application level, congestion detection techniques mirror those used at the lower RTP stream levels, such as analyzing latency volatility and checking for bursts of packet loss. The challenge is to accurately identify congestion without being too sensitive to minor RTT fluctuations, which might be caused by unrelated network activity, or too insensitive, which would mean only reacting to severe packet losses when quality degradation is already noticeable.
In practice, consider creating a small client-side process that informs the user about quality degradation due to congestion. If we inform the user too frequently about network problems it can lead to annoying false positives. This is especially true when they do not sense any quality degradation. Conversely, if the video has been frozen for the last 10 seconds, informing the user about a possible quality problem might be too late, as it is already obvious. Most likely, the user would have already started solving the problem in their own way, such as refreshing the page.
qualityLimitationReason
To detect congestion in the application using WebRTC stats, we leverage the qualityLimitationReason property of the outbound-rtp stats to provide early indications of bandwidth issues. The qualityLimitationReason property indicates the most likely reason (CPU, bandwidth, other) why the bitrate is reduced. This stat only exists for video. This property originates from the low-level RTC transport layer.
According to the native source code, bandwidth quality limitation occurs when either the quality scaler or bandwidth scaler is activated. This happens when the resolution or frame rate has been reduced due to resource overuse. Additionally, if simulcast layers are disabled due to low available bandwidth, or the internal encoder has scaled the output accordingly.
Validating qualityLimitationReason=bandwidth
Many factors go into reporting qualityLimitationReason and the true cause may be misreported. See here for a good explanation for this. To verify bandwidth limitation is indeed due to congestion, we need to observe other metrics such as round-trip time (RTT).
To refine our approach to detecting congestion:
- Monitor the qualityLimitationReason property: If it indicates bandwidth as the limiting factor, this may suggest network congestion.
- Track RTT volatility: To reduce false positives where CPU limitations might be misidentified as bandwidth issues, also track RTT volatility. Only claim congestion if the reason is bandwidth-related and there is a concurrent increase in RTT.
This dual-factor approach helps balance sensitivity and specificity, allowing for more accurate detection and timely network congestion management.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
const outbTraces = new Map<string, { qualityLimitationReason: string }>(); const remoteInbTraces = new Map<string, { totalRoundTripTime: number, roundTripTimeMeasurements: number }>(); let ewmaRttInMs: number | undefined; let congested = false; setInterval(async () => { const roundTripTimeMeasurements: number[] = []; (await (peerConnection.getStats())).forEach((report: any) => { if (report.type === 'outbound-rtp') { const newTrace = { qualityLimitationReason: report.qualityLimitationReason, }; outbTraces.set(report.id, newTrace); } if (report.type === 'remote-inbound-rtp' && report.totalRoundTripTime && report.roundTripTimeMeasurements) { let trace = remoteInbTraces.get(report.id); if (!trace) { trace = { totalRoundTripTime: 0, roundTripTimeMeasurements: 0, }; remoteInbTraces.set(report.id, trace); } const diffMeasurements = report.roundTripTimeMeasurements - trace.roundTripTimeMeasurements; const diffTotalRoundTripTime = report.totalRoundTripTime - trace.totalRoundTripTime; if (diffMeasurements > 0 && diffTotalRoundTripTime > 0) { const avgRttInInterval = diffTotalRoundTripTime / diffMeasurements; trace.totalRoundTripTime = report.totalRoundTripTime; trace.roundTripTimeMeasurements = report.roundTripTimeMeasurements; roundTripTimeMeasurements.push(avgRttInInterval * 1000); } } }); const avgRoundTripTimeInMs = roundTripTimeMeasurements.reduce((a, b) => a + b, 0) / roundTripTimeMeasurements.length; if (!Number.isNaN(avgRoundTripTimeInMs)) { if (!ewmaRttInMs) { ewmaRttInMs = avgRoundTripTimeInMs; } const isBandwidthLimited = [ ...outbTraces.values() ].some((trace) => trace.qualityLimitationReason === 'bandwidth'); if (!congested && isBandwidthLimited && (avgRoundTripTimeInMs - ewmaRttInMs) > 50) { console.warn('Congestion detected, the network is bandwidth limited and the round trip time is increasing (ewmaRtt: %d, avgRoundTripTime: %d)', ewmaRttInMs, avgRoundTripTimeInMs); congested = true; } else if (congested && (avgRoundTripTimeInMs - ewmaRttInMs) < 30) { console.info('Congestion resolved, the round trip time is back to normal (ewmaRtt: %d, avgRoundTripTime: %d)', ewmaRttInMs, avgRoundTripTimeInMs); congested = false; } ewmaRttInMs = (0.9 * ewmaRttInMs) + (0.1 * avgRoundTripTimeInMs); // eslint-disable-next-line no-console console.info(`avgRoundTripTime: ${avgRoundTripTimeInMs}, ewmaRttInMs: ${ewmaRttInMs}, bandwidthLimited: ${isBandwidthLimited}`); } }, 1000); |
The process takes stats every second, keeping track of bandwidth limitations for each outbound track and calculating the average RTT (in milliseconds) using the remote-inbound-rtp. It collects the round trip times from all outbound video tracks. Since the measured RTT originates from the same peer connection, and the peer connection uses one ICE candidate to send traffic, the measured RTTs are close to the true RTT of the peer connection. To approximate the actual RTT, we calculate the average. A slight note here: taking the median would better approximate the value, but I do not want to make this code snippet longer.
If any underlying layer reports bandwidth limitation, and the round trip time has also increased (we are tracking an exponentially moving average of the measured RTT and comparing the newly measured RTT), then we claim congestion has occurred. The congestion event is considered resolved if the RTT returns to normal.
Here is an output from a local test where I suddenly throttled my outbound network interface and then released it:
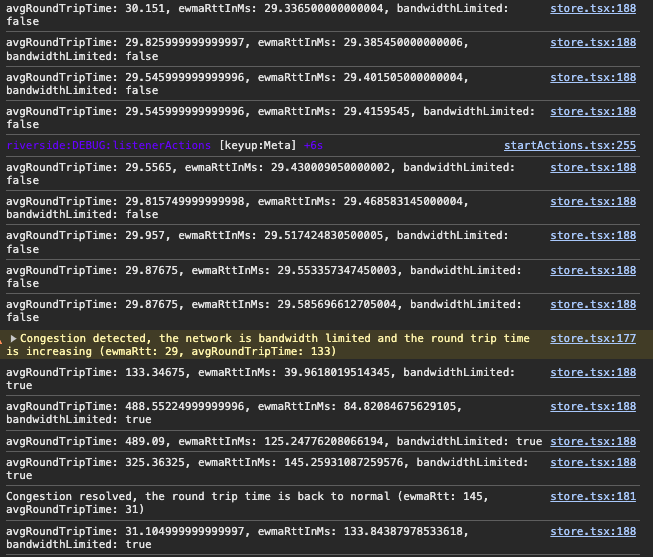
Please note that this is a very rudimentary algorithm to detect congestion. It does not clean tracks from traces if they are stopped or take into account edge cases such as switching new network connection for which the RTT might differ significantly.
A slightly modified version of this algorithm is built into the client-monitor, which you can use like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const monitor = createClientMonitor(); const detector = monitor.createCongestionDetector({ // high sensitivity will trigger congestion alert based on quality limitation reason equal to bandwidth. // medium sensitivity will trigger congestion alert based on quality limitation reason and RTT increase. // low sensitivity will trigger congestion alert based on quality limitation reason and fraction lost. sensitivity: 'medium', }); detector.on('congestion', (event) => { console.log('Available outgoing bitrate before congestion:', event.outgoingBitrateBeforeCongestion); console.log('Available outgoing bitrate after congestion:', event.outgoingBitrateAfterCongestion); console.log('Available incoming bitrate before congestion:', event.incomingBitrateBeforeCongestion); console.log('Available incoming bitrate after congestion:', event.incomingBitrateAfterCongestion); }); |
Additionally, you can obtain the target bitrate before and after the monitor detects congestion. This gives some hints to estimate the bandwidth saturation point.
CPU limitation
If your computer’s processor is overrun, you may have issues sending a quality stream and decoding the streams sent to you. We discussed qualityLimitationReason property from the video outbound-rtp stats in the Network Congestion section. This property also has a cpu value that we can leverage.
qualityLimitationReason is not enough
As mentioned in the previous section, CPU and bandwidth issues can occur at the same time, but qualityLimitationReason can only report on one at a time. If both are occurring, bandwidth is reported. Therefore, if CPU limitation is assigned as the reason, it confirms that the issue is indeed related to CPU constraints and not bandwidth. However, qualityLimitationReason will miss reporting CPU issues if there are also bandwidth issues.
There was a notable talk from Kranky Geek in 2021 about managing CPU and network resources in the browser for large video grids. The approach Agora uses in that video focuses on the decoded frames per second variability from the inbound-rtp stats and the time the browser spends collecting all stats. This approach is beneficial for detecting computational strain caused by decoding too many streams at too high a resolution. By combining this with the qualityLimitationReason for the outbound-rtp, we can cover both encoding and decoding, making issue detection more accurate.
What this looks like in code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
const traces = new Map<string, { lastNFramesPerSecond: number[], avgFramesPerSecond: number }>(); let cpuLimited = false; setInterval(async () => { let gotCpuLimited = false; (await (peerConnection.getStats())).forEach((report: any) => { // if we got limited in any case there is no need to go through the rest of the reports if (gotCpuLimited) return; if (report.type === 'inbound-rtp') { if (!report.framesPerSecond) return; let trace = traces.get(report.id); if (!trace) { trace = { lastNFramesPerSecond: [], avgFramesPerSecond: 0 }; traces.set(report.id, trace); } trace.lastNFramesPerSecond.push(report.framesPerSecond); while (trace.lastNFramesPerSecond.length > 8) { trace.lastNFramesPerSecond.shift(); } if (trace.lastNFramesPerSecond.length > 0) { const avgFramesPerSecond = trace.lastNFramesPerSecond.reduce((a, b) => a + b, 0) / trace.lastNFramesPerSecond.length; const avgDiff = trace.lastNFramesPerSecond.reduce((acc, fps) => acc + Math.abs(fps - avgFramesPerSecond), 0) / trace.lastNFramesPerSecond.length; const fpsVolailityInPercentage = (avgDiff / avgFramesPerSecond) * 100; trace.avgFramesPerSecond = avgFramesPerSecond; if (cpuLimited && fpsVolailityInPercentage < 5) { return; } else if (!cpuLimited && fpsVolailityInPercentage > 10) { return (gotCpuLimited = true); } } } if (report.type === 'outbound-rtp') { if (report.qualityLimitationReason === 'cpu') { return (gotCpuLimited = true); } } }); if (!cpuLimited && gotCpuLimited) { // eslint-disable-next-line no-console console.warn('CPU Limitation detected'); cpuLimited = true; } else if (cpuLimited && !gotCpuLimited) { // eslint-disable-next-line no-console console.info('CPU Limitation resolved'); cpuLimited = false; } }, 500); |
Here we go through the inbound-rtp and outbound-rtp reports. With outbound-rtp, our observation is straightforward – we simply check if the qualityLimitationReason is CPU. With inbound-rtp, we calculate the so-called FPS volatility, as discussed by Ben Weekes in the aforementioned Kranky Geek talk.
First, we sample the frames per second (FPS) property, which indicates how many frames the decoder was capable of decoding per second. We calculate the average FPS, which we expect the decoder to maintain each second, and then calculate the average deviation from this expected value. Lastly, we compare the average deviation with the expected value to gauge the actual volatility. If this volatility exceeds 10%, we consider the CPU to be constrained.
To avoid unnecessary flip-flopping around a threshold, I introduced a high and low watermark technique. If constrained CPU was previously detected, we only call it “not constrained” if the FPS volatility goes below a smaller threshold than what previously indicated the problem.
Here’s how you can detect such issues using the createClientMonitor method in client-monitor-js:
|
1 2 3 4 5 6 7 8 |
const monitor = createClientMonitor(); const detector = monitor.createCpuPerformanceIssueDetector(); detector.on('statechanged', (alertState) => { console.log(`CPU performance alert state changed to ${alertState}`); // switch to a lower simulcast layer and/or reduce the video grid }); |
This is not for audio or general CPU issues
Please note that this solution only works with video tracks, as outbound-rtp stats for audio do not have the qualityLimitationReason property, and inbound-rtp stats for audio do not have the framesPerSecond property.
Additionally, while this method focuses on detecting CPU limitations using purely WebRTC stats, there are other ways to indicate CPU issues to the client. For example, if you are using only Chrome, a reliable way is to utilize the Compute Pressure API.
Stuck Audio or Video tracks
Sometimes you may find you have a peer connection open that is not receiving anything. Typically, this is not due to a problem at the endpoints of the peer connection—if that were the case, the peer connection itself would likely not be established. Instead, it may indicate issues such as problems with SDP negotiation for a new track or control issues between peers, such as an SFU receiving but unexpectedly pausing a subscriber stream.
To detect a stuck track, we can utilize inbound-rtp stats from WebRTC and monitor the bytesReceived property. If bytesReceived remains at 0 for a certain period while the publisher is known to be sending RTP traffic, then we likely have a stuck inbound audio or video track.
Avoiding false positives
It is important to address situations where the remote media track pauses as the local track is created. Although a media track has a mute property, the PeerConnection does not relay that event to the remote ends. When creating a media track subscribed to a remote publisher, no built-in property or signaling exists to determine if the remote track is muted or if an intermediate server has stopped publishing the media to remote clients.
Therefore, to avoid false positive detection, it’s crucial to ensure that the remote end has not intentionally muted or paused the track, such as a paused microphone from a publisher when a remote client joins the room.
Stuck track detection code example
Here is a code snippet to detect a stuck track:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
const traces = new Map<string, { detected: number }>(); const remotePausedTracks = new Set<string>(); setInterval(async () => { (await (rcvTransport.getStats())).forEach((report: any) => { if (report.type !== 'inbound-rtp') return; if (report.bytesReceived === undefined || !report.trackIdentifier || remotePausedTracks.has(report.trackIdentifier)) return; if (report.bytesReceived > 0) { if (traces.has(report.trackIdentifier)) { traces.delete(report.trackIdentifier); } return; } const trace = traces.get(report.trackIdentifier); if (!trace) { return traces.set(report.trackIdentifier, { detected: Date.now() }); } else if (trace.detected + 5000 < Date.now()) { // eslint-disable-next-line no-console console.warn(`Track ${report.trackIdentifier} is not receiving any data`); } }); }, 1000); |
It’s a fairly straightforward algorithm: simply check if the number of received bytes is greater than 0. If the track is not in the remotePausedTracks list, we expect to receive traffic on it within 5 seconds after detecting that it is not receiving any.
Here’s how you can set up a detector for stuck tracks using client-monitor-js:
|
1 2 3 4 5 6 7 8 9 10 11 |
const monitor = createClientMonitor(); const detector = monitor.createStuckedInboundTrackDetector({ minStuckedDurationInMs: 3000 }); detector.on('stuckedtrack', ({ peerConnectionId, trackId }) => { console.log(`Stucked track detected on peer connection ${peerConnectionId}. trackId: ${trackId}`); }); const pausedTrackId = ''; // local track id consuming rtp stream from a remote paused publisher. detector.ignoredTrackIds.add(pausedTrackId); |
4. Frozen Video Track
We can detect video freezes with the freezeCount property within inbound-rtp stats. This property tracks the total accumulated number of freezes for a particular RTP stream. An increasing freezeCount signals a potential issue. This increase can be used to notify the web application with the affected track identifier for further action with a mapping to a remote participant.
Before 2022, I relied on the framesPerSecond metric and monitored for drops to zero to identify freezes. This approach, however, was susceptible to false positives, especially when the publisher intentionally paused the video stream. With the introduction of the freezeCount and totalFreezesDuration metrics into WebRTC stats, I transitioned to these more reliable indicators.
Here’s a JavaScript function to detect video freezes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
function detectFreezes(peerConnection: RTCPeerConnection) { const traces = new Map<string, number>(); setInterval(async () => { const collectedStats = await peerConnection.getStats(); collectedStats.forEach((stats) => { if (stats.type !== 'inbound-rtp') return; if (stats.kind !== 'video') return; const { trackIdentifier, freezeCount } = stats; if (!trackIdentifier || freezeCount === undefined) return; let lastFreezeCount = traces.get(trackId); if (lastFreezeCount === undefined) { traces.set(trackIdentifier, freezeCount); return; } if (freezeCount > lastFreezeCount) { console.log('Freeze detected on track:', trackIdentifier); } traces.set(trackIdentifier, freezeCount); }) }, 1000) } |
In client-monitor-js, we can set up a freeze detector as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
const monitor = createClientMonitor(); const detector = monitor.createVideoFreezesDetector(); detector.on('freezedVideoStarted', (event) => { console.log(`Video is freezed on peer connection ${event.peerConnectionId}, track ${event.trackId}`); }); detector.on('freezedVideoEnded', (event) => { console.log(`Video freeze ended on peer connection ${event.peerConnectionId}, track ${event.trackId}, duration ${event.durationInS}`); }); |
Conclusion
Through my work with WebRTC stats by developing ObserveRTC, I have learned that creating an effective monitoring and debugging tool is a long and intricate process. This involves deep dives into the complexities of the RTC transport layer and the nuances of client-side performance monitoring.
Through the journey of developing ClientMonitor, I have learned several key lessons:
- Effective issue detection depends on both provided metrics and custom calculations to generate meaningful insights.
- Fine-tuning metrics helps better understand and address the root causes of performance issues.
- WebRTC stats offer more potential than we currently utilize – we often request metrics that appear useful for future applications, but it can take years to fully leverage these.
- WebRTC stats can be confusing and unclear:
- Various tricks and adjustments are needed to make them useful.
- Understanding these intricacies is crucial for developing reliable monitoring tools.
- Simplicity is essential for wider adoption:
- Initially, I provided numerous configuration options to fine-tune ClientMonitor.
- The monitor API had to be simplified, and configuration options were reduced multiple times to prevent developer confusion.
In the future, I will focus on optimizing the creation and transmission of samples for server post-processing. ClientMonitor will include more client-issue detectors and additional calculated properties. For example, I want to add an estimated Mean Opinion Score (eMOS) and a basic client score, to provide deeper insights into service quality and user experience.
The project is open to suggestions via GitHub issues and pull requests if you have enhancement ideas!
{“author”: “Balázs Kreith“}





Hello, there is something that left me wondering if my understanding of RTCP is correct.
> In low-level streaming, monitoring is granular, relying on RTCP feedback intervals (typically 20-40ms)
> …
> high-level application layer detection relies on getStats polling and RTCP Receiver Report intervals
In most RTP+RTCP applications I’ve seen, the RTCP SR/RR interval is at least 1 second, with a tendency towards 5s for audio only applications. Is it expected to have such low values for video apps? Or did I misunderstand which interval is discussed?
Your observations regarding RTCP SR (Sender Reports) and RR (Receiver Reports) are correct, with the interval calculation being between 1 and 5 seconds as specified in RFC 3550, Appendix A.7. However, Sender and Receiver Reports are not considered RTCP feedback messages; they are standard RTCP control packets used in RTP sessions to report transmission and reception statistics.
RTCP feedback messages serve different purposes and can be issued by applications for various reasons. For example, Google introduced the REMB (Receiver Estimated Maximum Bitrate) message as part of its congestion control strategy, as outlined in the REMB draft.
High-frequency RTCP feedback messages can be used to monitor network conditions. RFC 8888 describes a congestion control feedback mechanism from the receiver to the sender, supporting sender-side congestion control. The frequency of these messages typically ranges from 20 to 400 milliseconds, often triggered after each frame is received.