Note: Chinese translation thanks to Xueyuan Jia and Xiaoqian Wu of the W3C. See the English version here.
W3C Web 技术标准专家 François Daoust 和 Dominique Hazaël-Massieux(Dom)先前与我们探讨了如何使用 WebCodecs 和 Streams 进行实时视频处理。那篇文章重点介绍了如何设置流水线以应付来自摄像头、WebRTC 流或其他来源的视频帧低延迟处理。演示了一些处理示例 — 改变颜色、覆盖图像,甚至是改变视频编解码。引用的其他用例还包括机器学习处理,例如添加虚拟背景。
今天,他们将重点讨论可用于进行实际视频处理的诸多技术选项。有很多技术用来读取和更改视频帧内的像素。他们全面回顾了当前基于 Web 的所有技术选项 — JavaScript、WebAssembly (wasm)、WebGPU、WebGL、WebCodecs、Web 神经网络(WebNN)和 WebTransport。其中一些技术已经存在一段时间,许多则是新出现的。
这是一篇关于与视频分析与操作的文章。感谢 François 和 Dominique 与我们分享他们的研究,测试 Web 上可用的进行视频处理的完整技术目录。
正文内容
{“editor”, “chad hart“}

在上一篇文章中,我们探索了使用 WebCodecs 和 Streams 创建实时视频处理管线,玩多米诺骨牌来创建 VideoFrame 对象的流。我们讨论了如何创建一个管线来对视频帧进行各种处理,但我们没有深入探讨如何进行处理的细节。在这篇文章中,我们将研究可以使用的几种技术!
我们先回顾每种技术,并总结一些相应收获。
注意: 本文主要讨论视频帧的处理。虽然这里概述的一些技术和事项也适用于音频,但对音频帧的处理最好使用 Web audio API 来完成,本文对此不做介绍。
进行视频帧处理的选项
以下表格总结了可用于处理表示为 VideoFrame 对象的单个视频帧像素的技术。它包括一些高阶考虑因素,以指导选择最合适的一个。请参阅有关每种技术的详细介绍以获得更多信息。
如第一部分所讲,处理工作流程的性能在很大程度上取决于内存复制的需求,这取决于视频帧最初存在的位置,而这又取决于浏览器如何创建它。根据第一部分所设想的工作流类型,视频帧在某些时候可能会存在于 GPU 内存中。这是与性能相关的优缺点所假设的。
| 方法 | 它能做什么 | 优点 | 缺点 |
|---|---|---|---|
| JavaScript | 利用 CPU 处理像素或整个图像 |
|
|
| WebAssembly | 利用 CPU 处理像素或整个图像 |
|
|
| WebGL | 利用 GPU 操纵像素或整个图像 |
|
|
| WebGPU | 利用 GPU 操纵像素或整个图像 |
|
|
| WebCodecs | 编码/解码或更改编解码器 |
|
|
| WebTransport | 通过网络发送编码的媒体流数据 |
|
|
| Web 神经网络 | 运行神经网络模型来分析或处理图像 |
|
|
使用 JavaScript
处理像素的明显起点是使用常规的 JavaScript。JavaScript 数据位于 CPU 内存中,而视频帧像素通常位于 GPU 内存中。从 JavaScript 代码访问帧像素首先意味着将它们复制到 ArrayBuffer,然后以某种方式处理它们:
|
1 2 3 4 5 6 7 8 9 |
// Copy the frame to a large enough (for a full HD frame) buffer const buffer = new Uint8Array(1920*1080*4); await frame.copyTo(buffer); // Save frame settings (dimensions, format, color space) and close it const frameSettings = getFrameSettings(frame); frame.close(); // Process the buffer in place and create updated VideoFrame process(buffer, frameSettings); const processedFrame = new VideoFrame(buffer, frameSettings); |
像素格式
ArrayBuffer 中的字节代表什么?颜色是肯定的,但是帧的 像素格式(暴露在 frame.format 中)可能会有所不同。粗略地讲, 应用程序将得到红、绿、蓝和 alpha 组件 (RGBA, BGRA)的某种组合,或者一个亮度组件(Y)和两个色度组件(U, V)的某种组合。带有 alpha 组件的格式具有等效的不透明格式(例如RGBA 的 RGBX),其中 alpha 组件被忽略。
无法请求特定格式,提供的格式通常取决于上下文。 例如,从相机或编码流生成的 VideoFrame 可能使用称为 NV12 的 YUV 格式,而从画布生成的 VideoFrame 可能使用 RGBA 或者 BGRA。存在用于帧格式之间进行转换的公式,参见维基百科上 YUV 文章中的示例。
应该如何解释颜色?这取决于框架的色彩空间。我们必须承认缺乏这方面的专业知识。根据你对像素应用的转换,你可能需要考虑到这一点。至少在转换结束后创建结果帧时,你需要将该信息传递给 VideoFrame 构造函数。还要注意的是,对高动态范围 (HDR)和宽色域(WCG)的支持工作正在进行中,但尚未包含在 WebCodecs 中也没有得到浏览器支持。部分原因是需要先扩展其他领域,例如为 HDR 内容添加画布支持。
性能
在性能方面,对 copyTo 的调用代价很高。来自 Mozilla 的 Paul Adenot 在2021年底 W3C 的专业媒体制作研讨会上发表了关于 WebCodecs 中内存访问模式的演讲,详细介绍了值得记住的关键数值。标准动态范围(SDR)中的全高清帧(1920*1080)的 C++ 副本在高端系统上大约需要5毫秒,除非该帧已经在 CPU 缓存中。
资料来源:Paul Adenot 关于 Memory access patterns in WebCodecs 的演讲
在典型的台式电脑上,如果没有实际进程,上述逻辑在 Chrome 中需要15到22毫秒。这很重要,特别是如果还需要渲染转换后的帧并将其写回 GPU 内存时(该副本似乎要快得多)。考虑每秒25帧(FPS)时每帧的时间预算为40毫秒。它需要以50fps 的速度在20毫秒内准备就绪。对 WebCodecs 的支持仍然处于萌芽阶段,copyTo 函数的性能可能会继续提升。正如 Paul 所说,副本在任何情况下都不可能是即时的
复制完成后,在 JavaScript 中循环遍历全高清帧的所有像素在台式计算机上通常需要10-20毫秒,在智能手机上需要40-60毫秒。既然在 Web 浏览器中可使用 SharedArrayBuffer ,我们可以在不同的 worker 之间使用并行处理来提高性能。
代码示例实际上制作了两个副本,一个是在调用 copyTo 时,另一个是在创建新的 VideoFrame 对象时。这些副本无法避免,因为 WebCodecs 没有(还没有?)一种机制将传入的 ArrayBuffer 的所有权转移到 VideoFrame。这部分正在考虑中,参见分离编解码器相关问题示例。实际上,即使没有这样的机制,浏览器在某些情况下也可以减少副本数量。例如 GPU 和 CPU 集成在移动设备上并共享相同的物理 RAM 是很常见的。在这样的设备上,至少在理论上可以避免副本。
使用 WebAssembly
WebAssembly(WASM)承诺为 CPU 处理提供接近原生的性能。这使其成为处理帧的合适候选。如果您不熟悉 WebAssembly,我将其总结为四点:
- 顾名思义,WebAssembly 是一种类似汇编的底层语言,被编译为在浏览器(和其他运行时)中运行的二进制格式。除了提供接近原生的性能之外,还有许多编译器可以从常见的源语言(C/C++、Rust、C#、AssemblyScript 等)生成 WebAssembly 代码,这使得 WebAssembly 非常适合将现有代码库移植到 Web。
- WebAssembly 只有数字类型(也存在引用类型,但它们与手头的问题无关,因此让我们姑且忽略)。其他任何东西,从字符串到更复杂的对象,都是应用程序(或编译器)需要在数字类型之上创建的抽象。
- WebAssembly 可以从 JavaScript 导出/导入函数,因此与 JavaScript 的集成非常简单。
- WebAssembly 代码在线性内存上运行,例如
ArrayBuffer,JavaScript 代码和 WebAssembly 代码都可以访问。
要使用 WebAssembly 处理 VideoFrame,起点与使用 JavaScript 时相同:需要使用 copyTo 将像素复制到共享的 JavaScript/WebAssembly 内存缓冲区。然后,需要在 WebAssembly 中处理像素并从结果中创建一个新的 VideoFrame(这会触发另一个内存副本)。
演示代码
我们以 WebAssembly 文本格式(二进制代码的直接文本表示)编写了转换函数,这是一个简单的绿背景转换器。参阅 GreenBackgroundReplacer.wat 文件中生成的代码。编译成二进制 WebAssembly 可以从 WebAssembly Binary Toolkit 运行 wat2wasm。在实践中,这些转换通常是用 c++、Rust、c# 等语言编写的,然后编译成 WebAssembly 字节码。
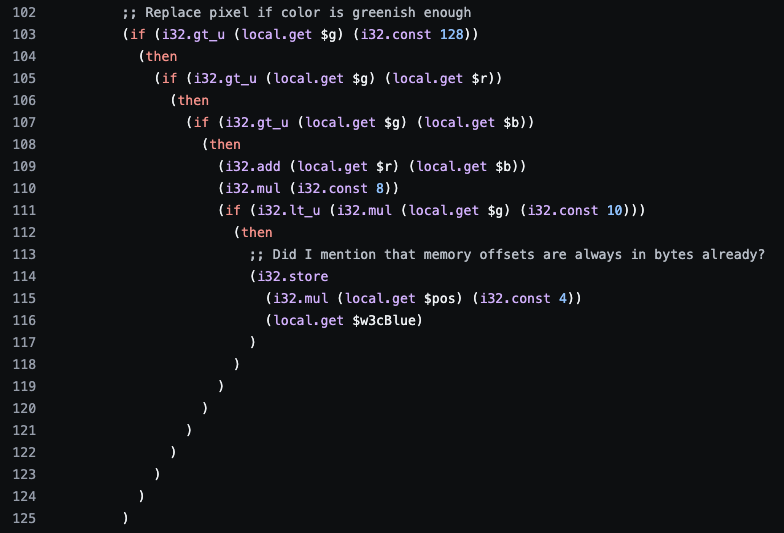
速度
WebAssembly 更快吗?内存复制与纯 JavaScript 处理的成本相同。在 WebAssembly 中循环遍历全高清帧的像素在桌面浏览器上只需要几毫秒,比纯 JavaScript 代码略短。总的来说,在我们的台式电脑上,每帧的平均处理时间为25ms,在智能手机上为50ms。
代码可以进一步优化:
- 可以使用 WebAssembly 线程 (就像 JavaScript worker)并行处理像素。 WebAssembly 线程仍处于提案阶段,还不是 WebAssembly 核心标准的一部分,但它们已经得到不同浏览器的支持。
- 单指令多数据 (SIMD) 指令可用于一次处理最多四个像素,详情参见 WebAssembly 规范中的 Vector 指令。
其他考虑
利用 WebAssembly 的专业视频编辑应用程序倾向于在 WebAssembly 中完成一切 — 添加/删除、编码/解码以及处理以节省时间。这有助于这些应用程序经常共享相同的 C/C++ 代码。除了性能之外,这种方法还提供了更大的灵活性,以支持浏览器本身可能不支持的编解码器。早先发布的关于 Zoom 的 web 端如何避免使用 WebRTC 的文章就是一个例子。
备注:
- WebAssembly 使用 little-endian 字节顺序读取/写入数字。演示中的 WebAssembly 代码一次读取四色组件,有效地反转了结果数字中的字节顺序(RGBA 变为 ABGR)。
- 与 JavaScript 一样,WebAssembly 代码也需要处理所有不同的像素格式。我们的代码只处理类似 RGBA 的格式,因为我们使用 WebGPU 在传入帧到达 WebAssembly 转换之前将其转换为 RGBA(见下文)。
使用 WebGPU
使用 JavaScript 和 WebAssembly 处理帧的主要缺点是从 GPU 内存到 CPU 内存的读回副本的成本,以及 worker 和 CPU 线程可以实现的并行度有限。这些限制在 GPU 世界中不存在,这使得 WebGPU 非常适合处理视频帧。
演示代码
WebGPU 公开了一个 importExternalTexture 方法来直接从<video>元素导入视频帧作为纹理。虽然这还不是规范的一部分(参阅在扩展提案中定义 WebCodecs 交互),但同样的方法也可能用于导入 VideoFrame。这就是我们需要的钩子(hook),如果不熟悉 GPU 概念(主要是样板代码),则其余代码会很晦涩。
演示中的 WebGPU 转换在 VideoFrameTimestampDecorator.js 中。它使用帧右下角的颜色代码覆盖帧的时间戳。
我们的想法是创建一个渲染管线,将 VideoFrame 作为纹理导入并逐个处理像素。渲染管线大致由顶点着色器阶段组成,该阶段产生剪辑空间坐标,并被解释为三角形。然后片段着色器阶段获取这些三角形并计算三角形中每个像素的颜色。着色器是用 WebGPU 着色语言 (WGSL) 编写的。
除非转换打算改变视频帧的形状和尺寸,否则最简单的方法是调用顶点着色器六次来生成两个覆盖整个帧的三角形。坐标也产生在所谓的 uv 坐标中,它与常规的帧坐标相匹配。在 WGSL 中,顶点着色器的核心是:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@vertex fn vert_main(@builtin(vertex_index) VertexIndex: u32) -> VertexOutput { var pos = array<vec2<f32>, 6>( vec2<f32>(1.0, 1.0), vec2<f32>(1.0, -1.0), vec2<f32>(-1.0, -1.0), vec2<f32>(1.0, 1.0), vec2<f32>(-1.0, -1.0), vec2<f32>(-1.0, 1.0)); var uv = array<vec2<f32>, 6>( vec2<f32>(1.0, 0.0), vec2<f32>(1.0, 1.0), vec2<f32>(0.0, 1.0), vec2<f32>(1.0, 0.0), vec2<f32>(0.0, 1.0), vec2<f32>(0.0, 0.0)); var output : VertexOutput; output.Position = vec4<f32>(pos[VertexIndex], 0.0, 1.0); output.uv = uv[VertexIndex]; return output; } |
片段着色器然后查看它需要着色的像素的坐标。如果它位于右下角,则着色器会计算叠加颜色。否则,着色器使用 WebGPU 提供的纹理采样器和 textureSampleBaseClampToEdge 函数输出原始视频帧中存在的像素。在 WGSL 中,片段着色器的核心是:
|
1 2 3 4 5 6 7 8 9 10 11 |
@fragment fn frag_main(@location(0) uv : vec2<f32>) -> @location(0) vec4<f32> { if (uv.x > 0.75 && uv.y > 0.75) { let xcomp: f32 = (1 + sign(uv.x - 0.875)) / 2; let ycomp: f32 = (1 + sign(uv.y - 0.875)) / 2; let idx: u32 = u32(sign(xcomp) + 2 * sign(ycomp)); return timestampToColor(params.timestamp, idx); } else { return textureSampleBaseClampToEdge(myTexture, mySampler, uv); } } |
从 JavaScript 的角度来看,GPU 设备被初始化以将结果写入画布,然后可用于创建最终的 VideoFrame。准备好参数和 GPU 命令后的转换逻辑如下所示:
|
1 2 3 |
gpuDevice.queue.submit([commandEncoder.finish()]); const processedFrame = new VideoFrame(canvas, …); controller.enqueue(processedFrame); |
一些关于演示代码的额外说明:
-
- 对
submit的调用在 GPU 上运行命令,这显然是一个异步过程。不过无需等待,浏览器将自动等待连接到画布的 GPU 命令完成,然后再尝试读取(在这里调用 VideoFrame 构造函数)。 - 从 WebGPU 的角度来看,画布并不是严格要求的,因为目标不是在屏幕上显示结果,而是生成一个新的
VideoFrame对象。相反,我们可以渲染成由gpuDevice.createTexture制作的普通纹理。问题是没有直接的方法从GPUBuffer创建VideoFrame,因此从 WebCodecs 的角度来看需要画布以避免将结果复制到 CPU 内存。
- 对
GPU 编程很不一样
除非你已经熟悉 GPU 编程,否则学习曲线会有难度。一些例子包括:
- WebGPU 着色语言 (WGSL) 中的内存布局在对齐和大小方面对值施加了限制。当你想将参数与纹理一起传递给 GPU 时,很容易迷失方向。
- 内存位置被划分为地址空间。uniform 和 storage 之间的区别我不清楚。什么时候应该使用?什么是合理的内存量?
- 有很多方法可以达到同样的结果。有正确的方法吗?例如,正如目前所写的那样,片段着色器效率很低,因为它会检查它接收到的每个像素的像素坐标。扩展顶点着色器将整个帧划分为一组三角形,并为每个坐标返回一个额外的参数,以阐明该点是从原始帧中获取还是它是一个颜色编码的点,这样会更有效。这样做值得吗?
WebGPU 很快!
虽然学习过程并不容易,但结果是值得的!首先,WebGPU 提供的采样器内部很神奇:无论帧的原始像素格式如何,采样器都会返回 RGBA 格式的颜色。这意味着应用程序不必担心转换,它们将始终处理 RGBA 颜色。它还可以轻松地将任何传入帧转换为 RGBA,将片段着色器简化为对采样器的简单调用,如 ToRGBXVideoFrameConverter.js:
|
1 2 3 4 |
@fragment fn frag_main(@location(0) uv : vec2<f32>) -> @location(0) vec4<f32> { return textureSampleBaseClampToEdge(myTexture, mySampler, uv); } |
注意:严格来讲,虽然着色器将看到 RGBA 颜色,但输出格式是由画布格式决定的,也可以是 BGRA,但这是在应用程序的控制之下。
更重要的是,由于不需要复制来导入纹理,不需要复制结果帧,同时并行处理单个像素,使用 WebGPU 的处理速度很快,在我们的简单场景中,在台式机上平均约为1ms(变化很小),在智能手机上约为3ms。也就是说,我们并不完全清楚我们测量的时间是否真的是使用 WebGPU 时的正确时间:Chrome 很可能只在绝对需要时阻止 JavaScript 等待 GPU 工作完成,而不是在创建 VideoFrame 时。 尽管如此,使用 WebGPU 的处理可以在不同设备上流畅运行。
WebGPU 样本可能损坏
WebGPU API 和 WGSL 语言在不断发展。例如,layout 参数现在需要传递给 createComputePipeline,参见 https://github.com/gpuweb/gpuweb/issues/2636。
这一变化和其他变化可能会影响在 Web 上找到的 WebGPU 示例,包括官方 WebRTC 示例仓库 中的 WebGPU 示例。我已经在 https://github.com/webrtc/samples/issues/1602 中报告了这个问题。
使用 WebGL
我们在演示中使用了 WebGPU,因为我们想更加熟悉这个 API。 WebGL 也可以类似地用于处理帧。更重要的是,在 WebGPU 可用之前,WebGL 将是跨浏览器实现的更明智的选择!(参阅 第一部分中的链接有助于跟踪 WebGPU 可用性)。
虽然 WebGL 与 WebGPU 不同,但总体方法是相同的。媒体标准工作组维护着 WebCodecs 示例,其中包含一个 VideoFrame 对象的 WebGL 渲染器。你将认识到此代码中的顶点和片段着色器对 VideoFrame 像素进行相同的采样。这次它们通过以下方式作为 2D 纹理导入:
|
1 2 3 4 5 |
gl.texImage2D( gl.TEXTURE_2D, 0, gl.RGBA, gl.RGBA, gl.UNSIGNED_BYTE, frame); |
我们的演示没有与 Streams 集成,但我们为 WebGPU 遵循的方法同样有效。
除非你想使用仅由 WebGPU 提供的高级 GPU 特性,否则最终的 WebGL VideoFrame 处理性能应该与 WebGPU 类似。
使用 WebCodecs
WebCodecs 当然可以通过 VideoEncoder 和 VideoDecoder 接口对视频帧进行编码和解码。虽然 WebCodecs 不允许修改单个像素或自行检查图像,但它确实包含许多可调整的编码/解码参数,可以调整流。参阅规范 获取关于选项的详细信息。
可以在 worker-transform.js 文件中找到以 H.264 编码视频流和解码 H.264 视频流的示例逻辑。
TransformStream
VideoEncoder 和 VideoDecoder 都使用内部队列,但很容易将其连接到 TransformStream 并传播背压信号:只需将 transform 函数返回的承诺的分辨率与 encode 或 decode 函数的输出绑定:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
const EncodeVideoStream = new TransformStream({ start(controller) { // Skipped: a few per-frame parameters this.encodedCallback = null; this.encoder = encoder = new VideoEncoder({ output: (chunk, cfg) => { if (cfg.decoderConfig) { // Serialize decoder config as chunk const decoderConfig = JSON.stringify(cfg.decoderConfig); const configChunk = { … }; controller.enqueue(configChunk); } // Skipped: increment per-frame parameters if (this.encodedCallback) { this.encodedCallback(); this.encodedCallback = null; } controller.enqueue(chunk); }, error: e => { console.error(e); } }); VideoEncoder.isConfigSupported(encodeConfig) .then(encoderSupport => { // Skipped: check that config is really supported this.encoder.configure(encoderSupport.config); }) }, transform(frame, controller) { // Skip: check encoder state // encode() runs async, resolve transform() promise once done return new Promise(resolve => { this.encodedCallback = resolve; // Skipped: check need to encode frame as key frame this.encoder.encode(frame, { … }); frame.close(); }); } }); |
请注意,编码配置适用于后续的编码帧。你需要将编码配置发送给之后要解码流的逻辑。我发现最简单的方法是将该配置作为流中的特定组块发送,就像在代码中所做的那样。这样做的好处是允许在过程中更改配置。
WebCodecs 性能
编码性能高度依赖于编解码器、分辨率和底层设备。在典型桌面设备上使用 H.264 编码的全高清视频帧可能需要8-20毫秒。解码通常要快得多,平均为1毫秒。在智能手机上,同一帧的编码可能需要70毫秒,而解码通常需要16毫秒。在所有情况下,前几帧通常需要更长的时间来编码和解码,最多需要几百毫秒。这可能取决于初始化编码器/解码器所需的时间。
CPU 与 GPU
对于编码,我们的时间度量是不同的,这取决于帧是在 GPU 内存还是 CPU 内存中。当帧第一次进入 WebAssembly(将其移动到 CPU 内存)时,编码需要约8毫秒;当帧停留在 GPU 上时,编码需要约20毫秒。这可能意味着这种编码是在我们机器的 CPU 内存中完成的,需要从 GPU 内存回读到 CPU 内存。
备注:将 GPU 内存和 CPU 内存视为独立的是很有用的。GPU 内存和 CPU 内存在某些架构中可能是相同的,例如在智能手机上,但它们在桌面架构中通常是脱节的。无论如何,浏览器可能出于安全原因将它们隔离在不同的进程中。
使用 WebTransport
我们已经提到 WebTransport 作为一种向云发送和从云接收编码帧的机制。我们没有时间在这里对此展开深入研究。不过,WebCodecs 和 WebTransport 规范的联合编辑 Bernard Aboba 写了一个 WebCodecs/WebTransport 示例融合了 WebCodecs 和 WebTransport。
示例代码没有将 VideoEncoder 和 VideoDecoder 队列链接到 WHATWG Streams。相反,它监控 VideoEncoder 的队列,丢弃无法及时编码的传入帧。根据应用程序的需要,背压信号可以传播到编码器或信号源。
应用程序可能只希望在绝对需要的情况下,在存在背压的情况下才丢弃传入帧。他们可能想要更改编码设置,例如,降低编码视频的质量并减少带宽。
管理背压的难点恰恰是核心 WebRTC API 中编码和发送步骤纠缠的原因(参见 第 1 部分)。 编码需要实时响应网络的波动。
此外,正如在 Real-Time Video Processing with WebCodecs and Streams: Processing Pipelines (Part 1)中指出的,现实中的应用程序将更加复杂,以避免队头阻塞问题,且并行使用多个传输流,每帧最多一个。 在接收端,需要对在各个流上接收到的帧进行重新排序和合并,以重新创建一个独特的编码帧流。
注意:使用 RTCDataChannel 发送和接收编码帧的工作方式类似。背压信号也需要由应用程序处理。
使用 Web 神经网络 (WebNN)
实时处理视频帧的一个关键用例是模糊或移除用户的背景。如今,这通常是通过机器学习模型来完成的。WebGPU 公开了 GPU 计算能力,可用于运行机器学习算法。也就是说,设备现在通常嵌入专用的神经网络推理硬件和 WebGPU 无法定位的特殊指令。最新的 Web Neural Network API 提供了一个与硬件无关的抽象层来运行机器学习模型。
WebNN API 的编辑者胡宁馨开发的代码示例突出了如何使用 WebNN 来模糊背景。进一步参见 GitHub issue 中的描述和讨论。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
SOURCE: https://www.w3.org/TR/webnn/#example-99852ef0 const context = await navigator.ml.createContext({powerPreference: 'low-power'}); /* The following code builds a graph as: constant1 ---+ +--- Add ---> intermediateOutput1 ---+ input1 ---+ | +--- Mul---> output constant2 ---+ | +--- Add ---> intermediateOutput2 ---+ input2 ---+ */ // Use tensors in 4 dimensions. const TENSOR_DIMS = [1, 2, 2, 2]; const TENSOR_SIZE = 8; const builder = new MLGraphBuilder(context); // Create MLOperandDescriptor object. const desc = {type: 'float32', dimensions: TENSOR_DIMS}; // constant1 is a constant MLOperand with the value 0.5. const constantBuffer1 = new Float32Array(TENSOR_SIZE).fill(0.5); const constant1 = builder.constant(desc, constantBuffer1); // input1 is one of the input MLOperands. Its value will be set before execution. const input1 = builder.input('input1', desc); // constant2 is another constant MLOperand with the value 0.5. const constantBuffer2 = new Float32Array(TENSOR_SIZE).fill(0.5); const constant2 = builder.constant(desc, constantBuffer2); // input2 is another input MLOperand. Its value will be set before execution. const input2 = builder.input('input2', desc); // intermediateOutput1 is the output of the first Add operation. const intermediateOutput1 = builder.add(constant1, input1); // intermediateOutput2 is the output of the second Add operation. const intermediateOutput2 = builder.add(constant2, input2); // output is the output MLOperand of the Mul operation. const output = builder.mul(intermediateOutput1, intermediateOutput2); |
来源:https://www.w3.org/TR/webnn/#example-99852ef0
请注意,在撰写本文期间上面的示例时有损坏 🙁 如 WebGPU 示例可能已损坏部分中所述,这些 API 正在开发中。 WebNN 未在任何地方实现,因此 WebNN 示例代码目前构建在 WebGPU 之上。
一些思考
Stream 还是不 Stream
WHATWG Streams 中的背压机制需要一些时间来适应,但一段时间后就会显得简单而强大。这两篇文章中描述的视频处理管道中的背压仍然很难解释,因为 WHATWG Streams 并没有在整个管链中使用。例如,在 WebRTC 中使用 MediaStreamTrack 将管链划分为具有不同背压机制的不同部分。从开发人员的角度来看,这使得混合技术更加困难。它还创建了不止一种方法来构建处理管道,没有明显正确的方法来排队和反压。
当我们编写代码时,我们发现 WHATWG Streams 的使用很自然,但演示仍然是最基本的。当需要处理大量的极端情况时,使用 WHATWG Streams 可能效果不太好。制定 WebCodecs 标准的媒体工作组决定不将 WebCodecs 与 Streams 耦合。他们在 Decoupling WebCodecs from Streams 记录了其基本原理。原因包括需要沿着链条发送控制信号。例如,我们看到需要将解码配置分块发送。例如 flush 和 reset 等其他信号不容易映射到数据块。我们采用的方法适用于现实生活场景吗?探索更现实的视频会议环境将是一件有趣的事情。
像素格式和色彩空间
WebCodecs 公开内存中存在的原始视频帧。这就要求应用程序处理不同的视频像素格式并正确地解释颜色。像素格式之间的转换不难也不简单,但很繁琐且容易出错。我们发现 WebGPU 提供的将所有内容转换为 RGBA 的功能非常有用。可能很值得探索关于公开转换 API 的问题,例如如何处理不同的像素格式以及用于像素格式之间转换的 API 中提到的。
技术和复杂性
这项探索为我们提供了一个很好的机会,让我们更加熟悉 WebGPU, WebAssembly, Streams 和 WebCodecs。每个都有自己的概念和机制。导航 API、编写代码以及了解在哪里进行调试需要付出很大的努力。例如 WebGPU 和 WGSL 中的管道布局、内存对齐概念、着色器阶段和参数都需要认真思考——除非你已经习惯 GPU 编程。WebAssembly 内存布局和指令、视频编解码参数、流和背压信号等也是如此。
换句话说,组合技术会产生认知负荷甚至更多,因为这些技术存在于在它们自己的生态系统中,有着脱节的概念和社区。除了文档记录之外,几乎没有什么可以做的。标准规范的解释往往有些枯燥,鉴于这些技术还很新,所以目前还很少有文章讨论使用 WebGPU、WebTransport 和 WebCodecs 进行媒体处理,这也就不足为奇了。随着时间的推移,这无疑会得到改善。
复制与隐藏复制
该演示中的数据为每种技术提供了一些视频帧处理性能数字。主要结论是,将原始帧从 GPU 内存复制到 CPU 内存是成本最高的操作。因此,应用程序将希望确保它们的处理管道最多只需要一个 GPU 到 CPU 的拷贝。
说起来容易做起来难。从纯粹的帧转换角度来看,留在 GPU 上可以控制性能,而且事实证明 WebGPU 非常强大。不幸的是,至少目前需要两个副本才能使用 JavaScript 或 WebAssembly 处理框架。
也就是说,与直觉相反,当初始帧在 GPU 内存中时,即使使用硬件加速(硬件加速可能受 CPU 限制,具体取决于用户的设备),帧编码也可能会产生副本。使用 WebGPU 处理帧所获得的性能提升可能会在后续编码阶段被抵消。相反,如果 WebAssembly 处理之后是编码阶段,那么与 WebAssembly 相关的复制成本可能不是问题。
当你将 WebAssembly 中转换操作之后的编码时间与仅应用编码/解码转换时的编码时间进行比较时,演示中对此进行了说明:
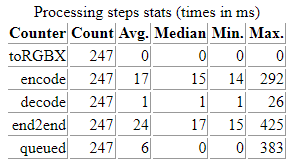 |
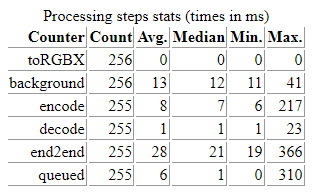 |
| 在 GPU 支持的帧上编码大约需要 17 毫秒 | 在 CPU 支持的帧上编码仅需约 8 毫秒 |
我们可能没有测量我们自己认为的……有些复制可能是在幕后制作的,并没有准确记录时间,特别是当使用 WebGPU 时。
无论如何,仍然很难推断出何时制作复制,以及哪些设置可能会缩短处理时间。当调用 copyTo 方法时,复制是显式的,但浏览器也可能在其他时间进行内部复制。这些副本可能会在每帧时间预算较小的直播场景中引入明显的延迟。关于内存复制的联合讨论在 WICG/reducing-memory-copies 存储库中已经开始了一段时间,负责有关技术的工作组正在进行讨论。无论解决方案在该领域是否实现,我们注意到,虽然很重要,但我们测量的延迟并不妨碍跨设备实时处理合理的视频帧(例如 HD at 25fps)。
{“author”: “François Daoust“}





Leave a Reply