It is time again to take a peek at what’s next in the world of Real-Time Communications (RTC). One area we have touched on a few times is the use of WebCodecs with WebTransport as an alternative to WebRTC’s RTCPeerConnection. Let’s call that approach W&W for brevity. WebRTC has powered trillions of sessions as it has matured over a decade. W&W gives brand new tools for building a RTC stack from the ground up, leveraging the latest HTTP/3 technologies. Is W&W better than WebRTC? Where does it make sense? When will it make sense?
To help answer those questions, a number of comprehensive W&W experiments have been popping up recently:
- Bernard Aboba of Microsoft and W3C Co-Chair has a demo here
- Jordi Cenzano Ferret of Meta and Media over QUIC member has a player, server, and demo video
- François Daoust of the W3C which we touched on here in our last post.
To delve deeper into this topic, I interviewed all three individuals last month. The video interview can be seen below. This post is a lightly edited transcript for clarity, supplemented with my own comments for additional context. The text below is intended to complement the video. You can watch, read, or better yet, read along while you watch.
{“editor”, “chad hart“}
Replay
Contents
- Introductions
- What’s wrong with WebRTC that we need something new?
- Review of a potential WebCodecs+WebTransport architecture
- Using Streams
- AV1 SVC experiments
- Jordi’s challenges
- Jordi’s Performance status
- What’s Next
Edited Transcript with Comments
Introductions
I started out with some introductions to the panelists.
Chad: Hello, everyone. Thanks for joining this webrtcHacks interview today. So we’ve been talking about WebCodecs and WebTransport for a couple of years now as the next thing coming to WebRTC to give lower level more controls, allow you to do more things. However, it has been a couple of years, and I’m not aware of anyone that has a production service that’s using these technologies. On the other hand, there are a lot of really interesting demos that we’ll walk through today that show that we’re getting kind of close.
Let me do some introductions –
Bernard Aboba
Chad: I first met Bernard, I think it was back in 2011 at one of the early WebRTC working groups. I think it was hosted over at Acme Packet where I was working. I’ve interviewed Bernard a few times for webrtcHacks.
Bernard is a principal architect at Microsoft and Skype. He is also heavily involved in standards. Bernard has been a long-time co-chair of the W3C WEBRTC Working Group. He’s also a co-chair of the more recently formed IETF WEBTRANS [Working Group] and AVTCORE [Working Groups].
François Daoust
Chad: Francois is another gentleman I met more recently. He is a Web and TV specialist over at W3C. He recently did a couple of excellent posts for webrtcHacks on real-time video processing, WebCodecs, and Streams based on some research he and his colleague, Dominique, have been working on to see how those APIs tie together.
Jordi Cenzano Ferret
Chad: We also have Jordi Cenzana-Ferret from Meta where he is a Video Software Engineer here. He’s been experimenting as part of some of the IETF Media Over QUIC group (MoQ). Actually, a few people suggested that I get him to write a post or do something about this really great ultra-low latency real-time streaming and playback demo he’s put together.
I would like to thank Bernard for inspiring this panel. I reached out to Bernard to see if he’d be interested in doing an update on standards. He suggested pulling together a panel here to talk through some of these recent experiments and to go into this a little more detail. So here we are today.
So, let’s dive into the questions. I’m going try to keep this to about 30 minutes and then we can open it up to audience Q&A. I can easily keep them for three hours, but we’re on somewhat tight timeline, so let’s get going.
What’s wrong with WebRTC that we need something new?
WebRTC has come a long way – both in terms of practical optimizations but also in terms of increasing developer controls. Do we really need a novel approach like W&W?
Chad: I like to start out by asking what’s wrong with WebRTC? Like, why do we need these new approaches in the first place? Why are you putting all this effort into these new techniques and these new approaches? What is it that we can’t do today that you’re trying to accomplish. Who is this for?
I’ll have you start, Bernard.
Bernard: Okay, I guess the first thing to say, Chad, is that a lot of the ideas in this effort started by extending WebRTC. So, for example, Insertable Streams, or what we call Encoded Transform, or Breakout Box, what we call mediacapture-transform, both are streams-based APIs. So that was the first introduction of what WHATWG Streams [API] into WebRTC. And those ideas have been picked up in WebTransport. So, in my view, a lot of it is extending WebRTC, but also adding new capabilities where you can combine WebRTC with other things.
So as an example, I think you’ve done some excellent articles in webrtcHacks about using Insertable Streams, using Breakout Box to do stuff. These are more tools that you have in your toolbox. For example, you can combine WebCodecs with WebRTC, maybe to add support for a new codec.
I’ve seen some interesting experiments, for example now that we have HEVC decode in WebCodecs, maybe combining that with WebRTC. And so I wouldn’t say it’s an either or, but one area I think Jordi will speak to in particular is low latency streaming. Yeah, so that’s an area. There are some things that I would claim that WebRTC is not great at, such as ultra-low latency streaming [features such as caching and DRM] that can be done with [MSE,] WebCodecs and WebTransport, and we’ll certainly get into that.
HEVC is the H.265 video codec, the successor to H.264. Notably it is in competition with the more open AV1 which is also mentioned later.
Bernard: But just to clarify, Chad, one of the reasons WebRTC is not great at [low latency streaming of protected content] – you can use the Data Channel to send CMAF, for example in low-latency streaming. But QUIC is a better transport. And that’s what you get with WebTransport. And also, at least at the moment, data channel doesn’t function in workers. We have a spec for it, but It’s not implemented. You get the full worker [support] in WebTransport.
Common Media Application Format (CMAF) is a newer – published by the Moving Pictures Expert Group (MPEG in 2018) – standardized container format for streaming with HLS and MPEG-DASH. Support for dynamic streaming using CMAF is provided in the Managed Media Source API, recently announced by Apple at WWDC 2023. QUIC is a foundational protocol for HTTP/3 based on UDP for lower latency. This is older, but my favorite QUIC backgrounder is still this one from WebRTC Boston. WebTransport is a client/server web protocol for transmitting data based on HTTP/3 over QUIC.
Today you can get sub-second latency streaming with WebRTC, but other file-based protocols like HLS are usually used if you want to allow the user to pause and rewind and a lower cost per stream (though some may argue that last point). Bernard was pointing out one could send your chunked, possibly DRM-protected, video-files over WebTransport at a lower latency. As Jordi will demonstrate, this approach allows caching and rewind, without much of a tradeoff in latency.
Bernard also mentioned afterward that Apple announced RTCDataChannel in Workers and Managed Media Source at WWDC 2023.
Review of a potential WebCodecs+WebTransport architecture
As mentioned, Jordi put tother a comprehensive “demo” of using WebCodecs with WebTransport for ultra-low latency streaming (300ms in his video, like WebRTC) with the ability to rewind to a specific point (unlike WebRTC).
If you haven’t seen it, you can see the full demo video here:
Chad: Jordi. Maybe this is a good spot for you to give an overview of your recent demo and what you were trying to achieve there. What did you do there that you couldn’t do with technologies like WebRTC alone?
Jordi: I wouldn’t say that the demo is to do something that we couldn’t do before. I think the MOQ will give us that, hopefully. But the demo was just to test those MoQ ideas.
Media over QUIC (MoQ) is an IETF working group that is experimenting and specifying protocols for mapping media onto QUIC
Jordi: This is the demo that I implemented. Again, the only purpose was to learn and to try to demonstrate that those ideas that we were talking in the MOQ workgroup were possible and working. What I implemented is just a JavaScript application that leverages WebCodecs and WebTransport and captures the data from the camera and the microphone and sends it. It compresses video and audio data and sends every video and audio frame in a different QUIC stream. QUIC streams are reliable. So basically, all the data in that frame is guaranteed to arrive to the relay.
Then one of the most interesting features of MOQ is that it’s cacheable – or we plan for it to be cacheable. So basically, what I implemented is leveraging quic-go and the WebTransfer implementation from Adrian Cable on top of [that]. I implemented a cache – a CDN node – that caches all those objects that the encoder sends.
On the other side – again [this is a] JavaScript application leveraging WebCodecs – I implemented a player that just receives that information from the relay. MOQ is push-based from the relay to the player. It receives that information and decodes it and renders it into a canvas and AudioContext.
This is the block diagram of the application.
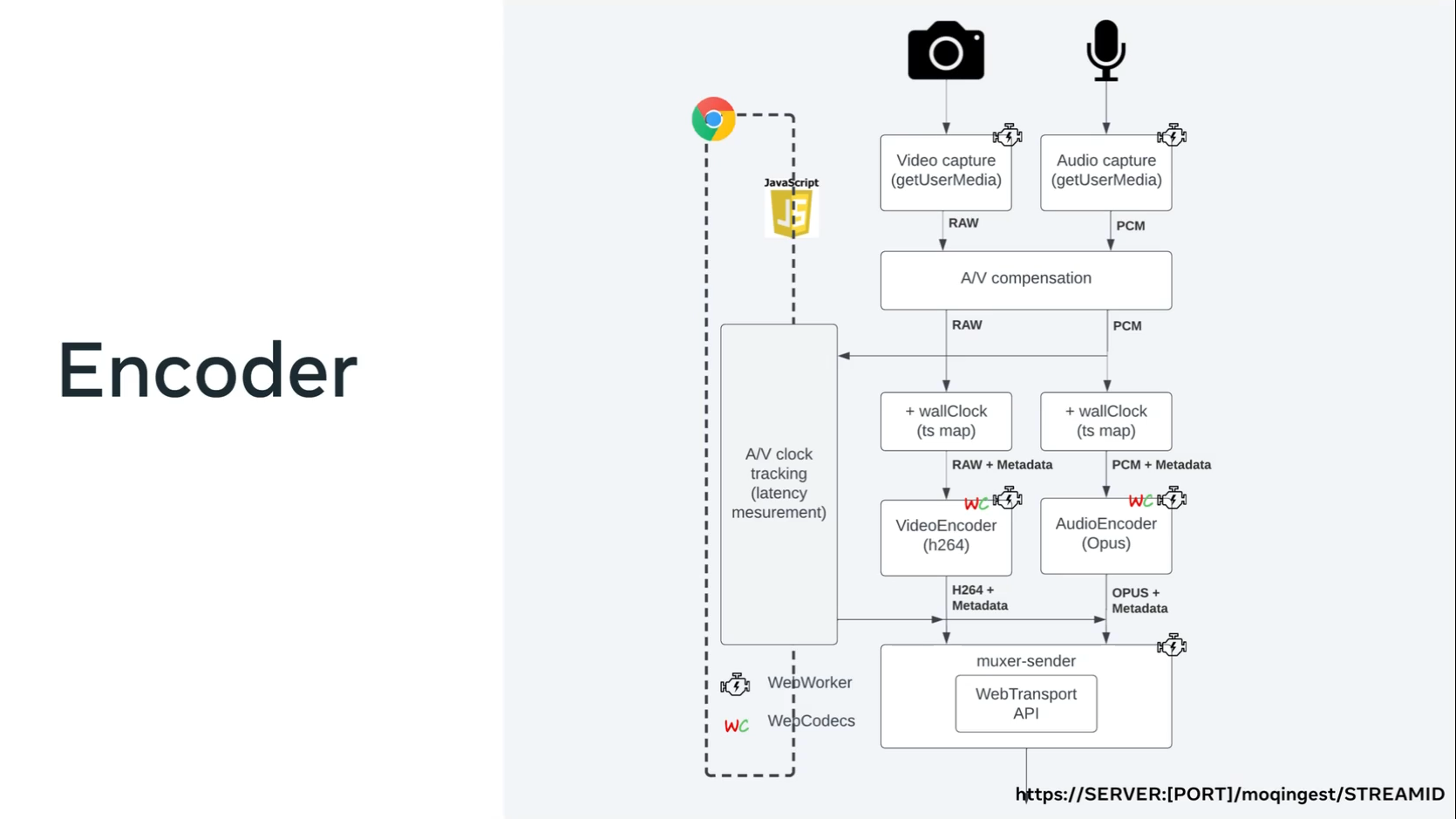
It is not optimized for production at all. I would say it’s quite the opposite – it’s optimized for experimentation. So that’s why I tried to do a very clear separation of concerns that allowed me to move very fast in this testing. For performance, I don’t think this is the architecture that you want.
getUserMedia
Jordi: Starting from the top, so we have
getUserMedia– we capture video and audio- so pixels and PCM samples.
A/V compensation
Jordi: The timestamps of those two pipelines are absolutely different, so we do some adjustment here because we want audio and video to be in sync. So basically, we align them, with a subtraction here.
The wallClock blocks
Jordi: We recommend [you mark] that information with some world clock timing when that sample was captured. That is very handy when you are in the player and you want to do rewinds or highlights of that content.
The Encoder Blocks
Jordi: Then we send it to a WebCodecs. So you can see that this runs into WebWorkers which has an encoders – H.264 for video and Opus for audio. We set keyframe, etc.
Muxer-sender
Jordi: Finally, we created a packager for this demo. The purpose is not to standardize any new packager at all. It was just easier to create my own [simple packager than to import fragmented MP4 or FLV [libraries]. Fragmented MP4 will be probably the one that MoQ will use. Inside the WebWorker it opens a WebTransport session that sends the streams to the relay.
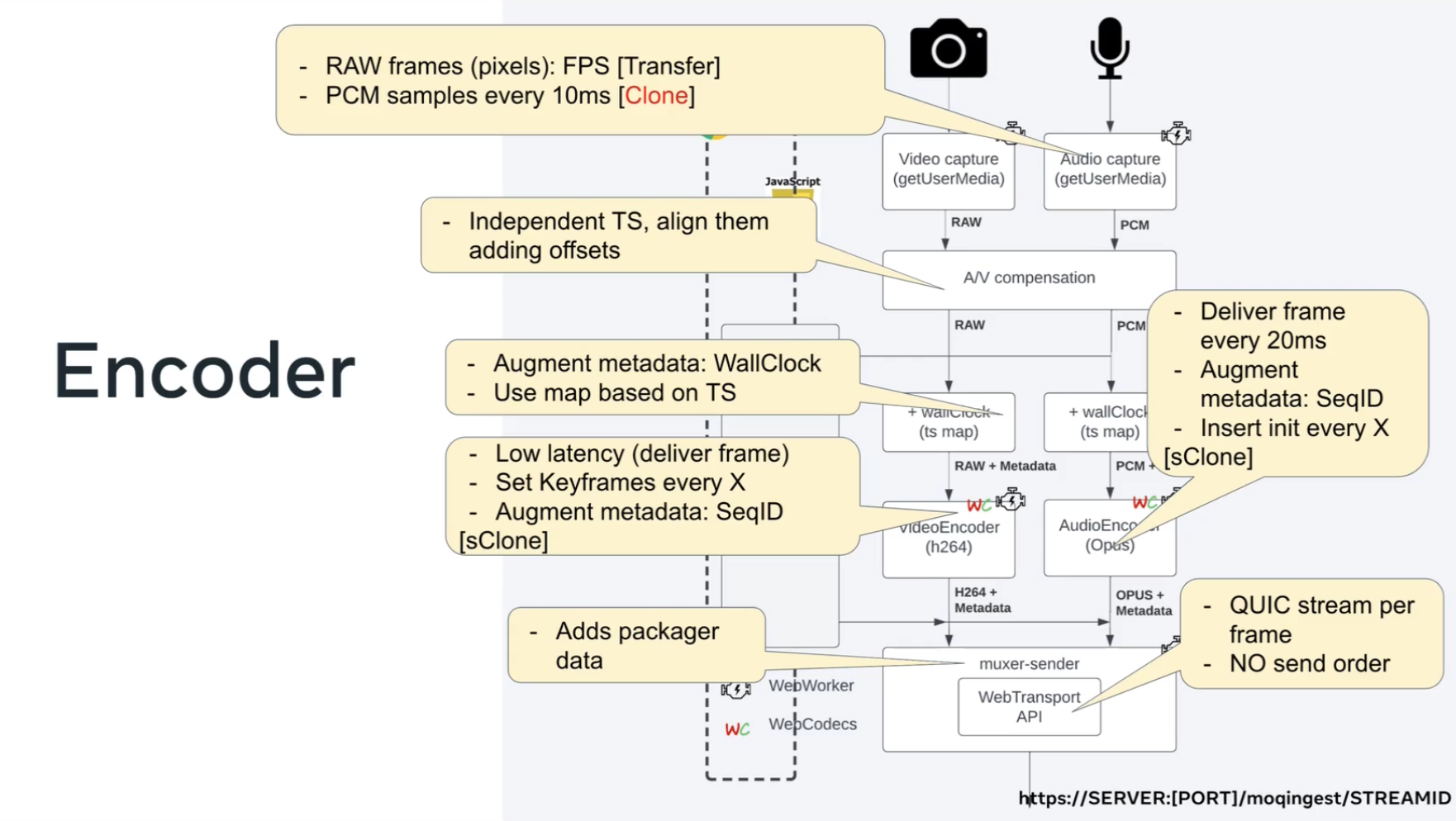
It Important to mention here that send order is not– or at least it was not available yet in the browser when I implemented this demo. This demo is all without send order.
The WebTransport spec has a sendOrder option to receive the datagrams in sequential order.
Relay CDN
Jordi: OK, the relay is quite simple:
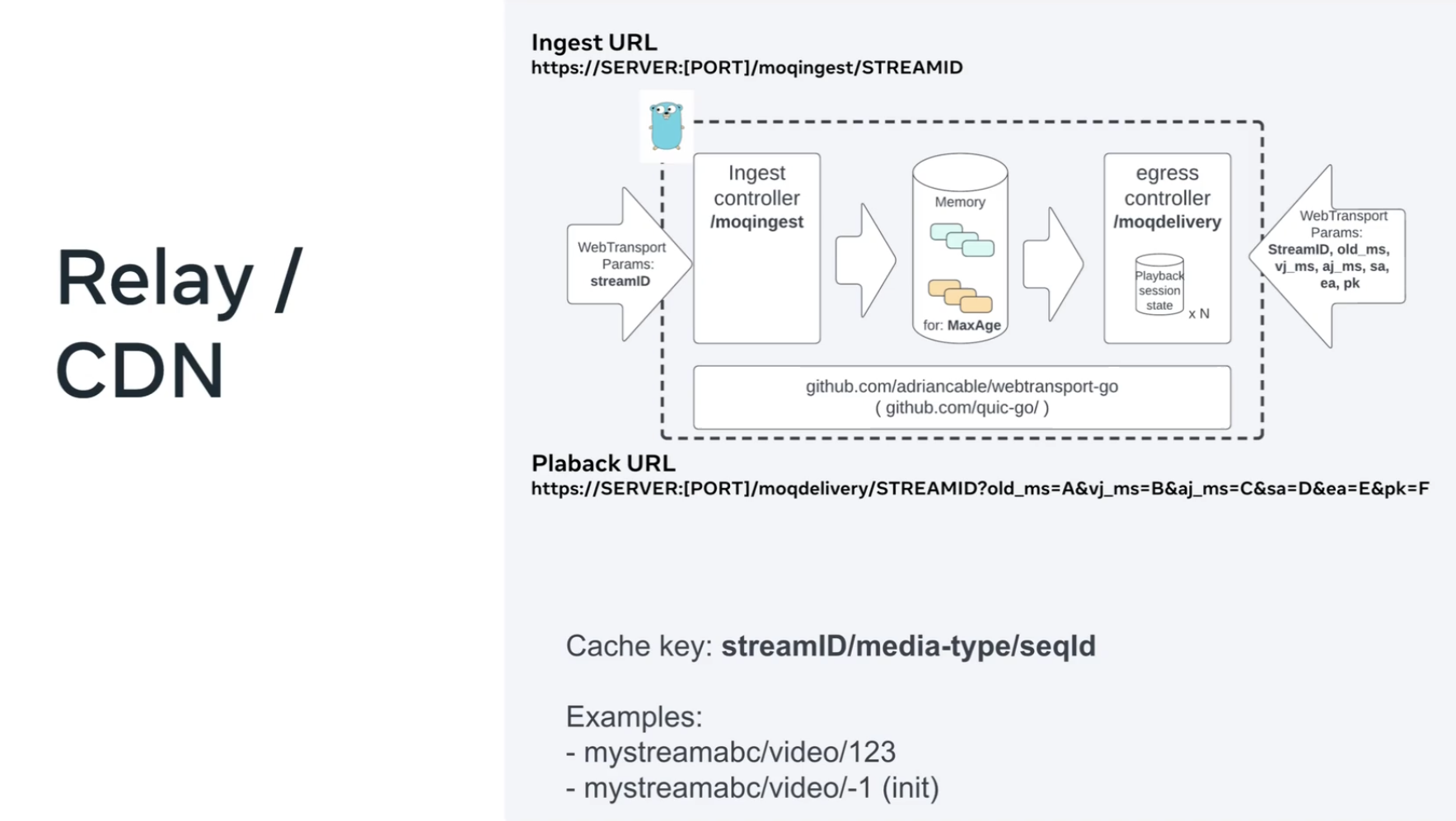
It receives the WebTransport session URL. So that URL includes an that entry point (
moqingest) and a stream identifier (STREAMID). We receive those objects [from WebTransport]. We save those objects in memory for some time to live (TTL) that is indicated by the encoder. This is typical CDN behavior up to this point.
Player URL

Jordi: Then the player can just open a session to this entry point,
moqdeliverywith the same stream identifier –STREAMIDhere. The URL includes some parameters that are used for rewind and also to inform the relay of the jitter buffers to allow the relay to make better decisions.
Cache Key

What is the cache key? So we are talking about CDNs or relays, it’s important to know what is the cache key. The cache key includes the stream ID that we get from the WebTransport session. Then [we add the media-type] — in this case, we only have video and audio, but it could be video one, video two, video three– that comes from the object header. The sequence ID (
seqId) comes from the object header. The sequence ID is basically the number of the objects or the number of the video frames and the number of the audio frames. So that creates a unique identifier per every object, in this case, per every frame. So this implementation is frame per object per frame, but MoQ is flexible enough to, if you want to put a GOP per frame, you can. So basically, it gives you just a description
The Player
Jordi: And finally – this is my last [diagram] – the player.
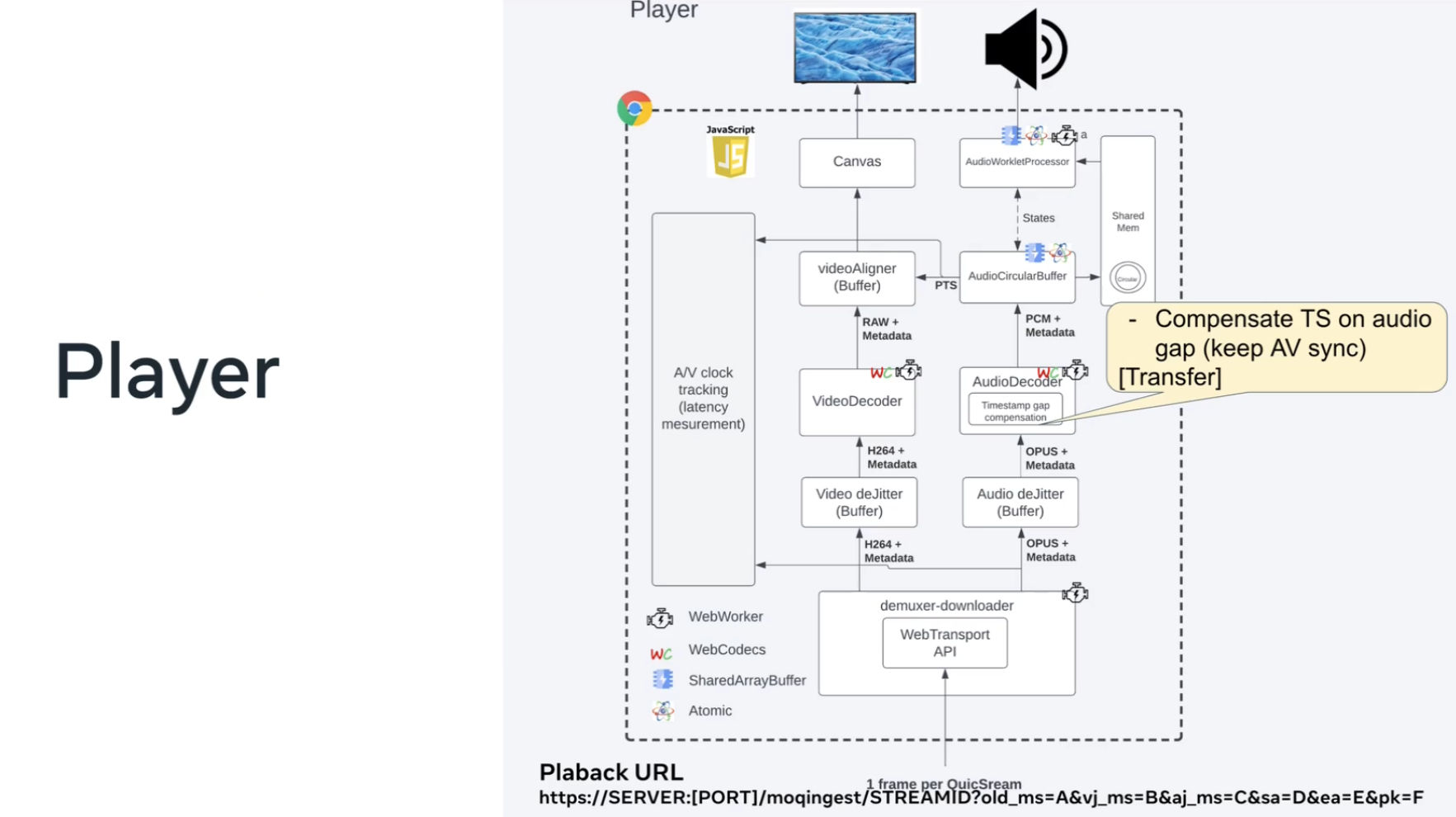
WebTransport block (from the bottom)
Jordi: The player opens a WebTransport session against the CDN or the relay. Again, with the
STREAMIDin the URL that we saw earlier. The player starts receiving audio and video frames. Remember, the relay pushes the data to the player.
Audio and Video Pipelines
Jordi: [The player knows] if it’s video or audio because of the object header. [The player] sends each [frame] to the right pipeline. We have a de-jitter because, remember, that [we send an independent] QUIC stream per frame, so [order of arrival] is NOT guaranteed. It’s reliable, but there is no guarantee that if you push different QUIC streams to the network that the order [you receive them is the order you sent them]. Therefore we need some de-jitter, so to make sure that the decoder sees the frames [in order].
Buffering and alignment
Jordi: This [alignment of audio and video for lip-sync] is a whole subject by itself, {This is] the area I spent the most time with. This could be very much improved. But anyway, here we do some compensation to align the audio and video.
One last point – we send audio to an audio circular buffer. Basically, it’s a shared memory between [an] audio worker like processes and the main thread. [And finally the audioWorkletProcessor consumes the PCM samples from that shared memory.]
Using Streams
Chad: That was a good architectural overview. I think it might be helpful to dig into streams and where that fits with Breakout Box and MediaCaptureTransform.
Francois, you had some materials there. You covered [this topic] quite a bit in the webrtcHacks post. But let me give you a couple minutes. You can walk through those bits. And then we can talk through, how all these things come together and some of the challenges of the combined architecture.
WHATWG Streams and pipelining
The Web parts of WebRTC are mostly defined by the World Wide Web Consortium, or W3C. However, there is another Web standards body, the Web Hypertext Application Technology Working Group (WHATWG) that have specs for things like WebSockets, the Full Screen API, and Streams as we will cover here.
This WHATWG stream visualizer may help give you a quick idea of the API.
François: So [WHATWG] Streams are a generic purpose mechanism to manage streams.
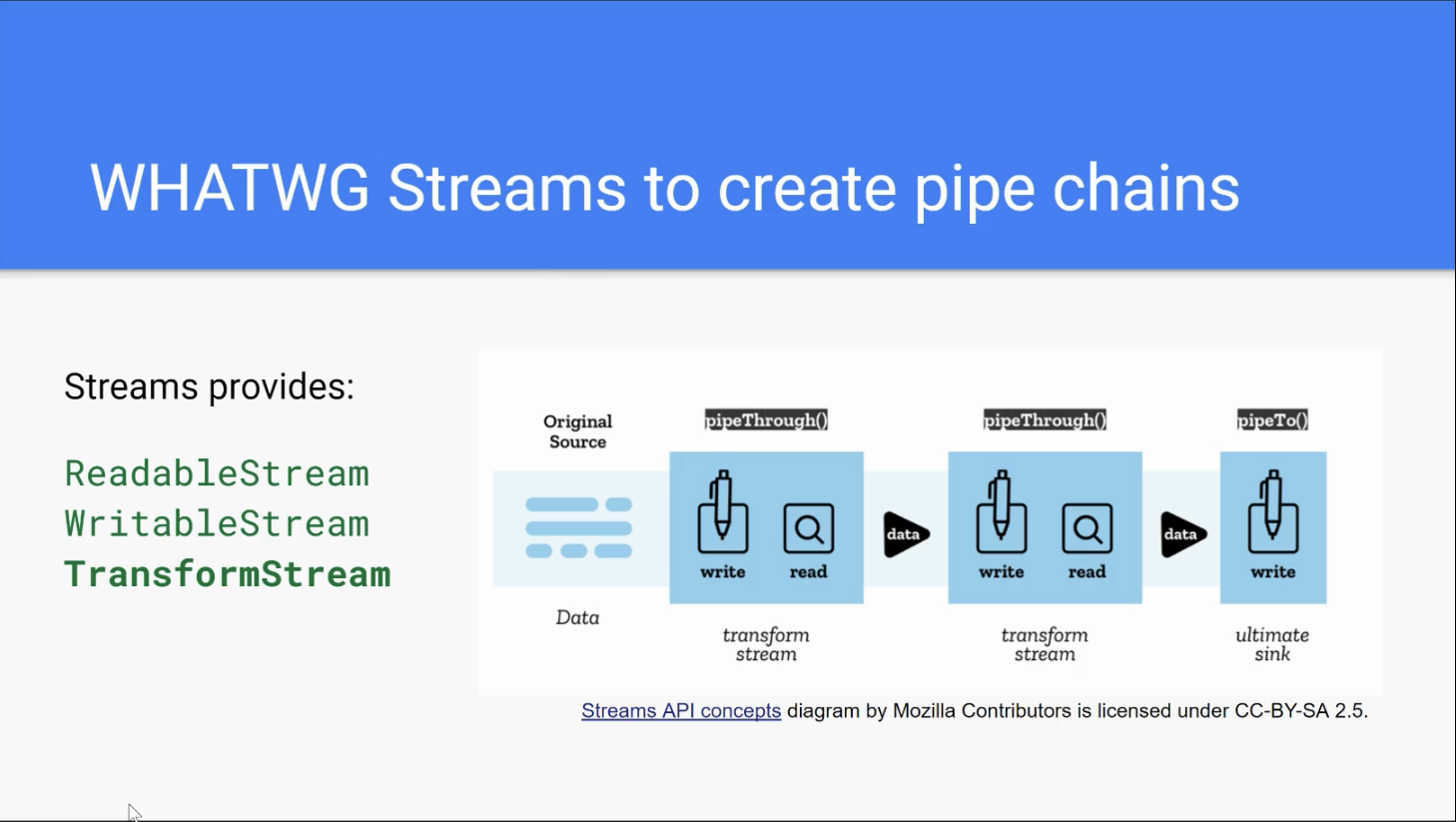
François: The name was rightly chosen. The good things about Streams is they takes care of queuing in the different steps. So you’re going to end up with a pipeline that has different steps. These steps are going to be connected through Streams, typically through Transform Streams. And Streams takes care of the queuing mechanism [between the processing steps]. If your transform takes a bit of time, then the queue is going to be managed by the Streams protocol itself.
Even more importantly than [basic] queuing, it includes a back pressure mechanism. So that means that if you have something that takes a bit longer to process [and it can’t keep up with what you are sending], the streams will send a back pressure signal to the nodes that are upstream and they will stop producing new chunks of data. That makes it a fantastic API – at least on paper – to use when dealing with audio and video, which are a kind of stream [themselves].
So one of the reasons, so my part, I’ve been more looking into actually video processing on the client, because as an answer to your first question, on top of improvement to transport issues, which Jordi and Bernard have been talking about, we’re seeing more and more use cases that have processing needs in real time. So meaning they need to change the contents of the video frame in real time. That means [these web apps] need to have access to the pixels themselves. That’s one of the reasons why we’re looking into extending WebRTC and extending the way that– providing new mechanisms to web applications so that they can manipulate these frames.
Note – like his webrtcHacks posts, François focused on video here. Similar mechanisms – but not the same – apply for audio too. Jordi will touch on that a little later in the interview.
WebCodecs give access to raw media

François: We mentioned WebCodecs already, which exposes the VideoFrame interface in particular. Then you have a connection with WebRTC through the MediaStreamTrack Insertable Media Processing using Streams specification that provides
VideoTrackGeneratorandMediaStreamTrackProcessor. So, in the end, what you end up with is a set of dominoes that you can use and you can assemble any way you wish on the client to manipulate these streams.

You should really see his webrtcHacks post for more on the “dominoes” concept. In brief, each “domino” is a processing block in a pipeline.
François: We’ve already seen examples with Jordi. The diagram follows this as well. So, if you’re taking
getUserMediafrom the camera. What’s important here is essentially the end – what you get out of it.getUserMediagives you aMediaStreamTrack. But you cannot process the video frame directly with aMediaStreamTrack– you need something else [to do that]. You need to turn it into an actual [JavaScript] stream, becausegetUserMediadoesn’t use streams by default. So, you’re going to feed it to aMediaStreamTrackProcessorthat will give you the stream of video frames that you can then process in any way you wish.
WebTransport is setup for streams
François: WebTransport here is interesting, because WebTransport is already based on streams. So, in a way, you get the streams of
VideoFrames for free. If you send video frames over WebTransport, you’ll get them, you’ll receive a stream ofVideoFrames. Of course, you’re not going to sendVideoFrames directly, raw video frames of a WebTransport, you’re going to send encoded video frames over WebTransport for a bandwidth reasons, but that simplifies your pipeline.So, I think that’s a generic introduction on streams and where they fit in this design architecture.
Real time media processing pipeline challenges
I asked François to recap the challenges he uncovered in his browser media processing pipeline experiments.
Chad: Thanks. Since we have you up here, Francois, can you give us some highlights on what the challenges that you discovered? What worked? What didn’t? If you take a couple minutes on that, and I’ll ask Bernard and Jordi after that, too, the same question.
François: Sure. My experiments were really about processing on the client more than transport over the network. I was really trying to assess what can we do with a
VideoFramein real time? Can we actually process them? How is the performance there? What would be typical performance if I process a frame with JavaScript? If I process a frame with WebAssembly? if I process a frame with WebGPU or WebGL, what’s going to happen?
Measuring performance
François: In order to do that, the first thing is that you need to be able to measure performance, and measuring performances, processing steps is doable, but end-to-end, it’s relatively hard, in particular because from a rendering perspective, you cannot follow a
VideoFrameup until it gets rendered on screen.

The workaround I used is that I’m essentially encoding the timestamp of the video frame as an overlay on top of the actual video frame. I’m using a requestVideoFrame callback to get that video frame back. Then to understand when it’s going to be rendered and to extract the encoded timestamp from it so that I can more or less track this. But that’s not absolutely perfect, and with
requestVideoFrameCallbackthere’s no guarantee that you’ll get all the frames. You can miss some of them because it runs on the main thread, and it can miss some of the frames [when it is overloaded].
WebGPU performance measurement is harder
François: Also, it’s not clear to me that I’ve managed to actually measure WebGPU performances correctly. With WebGPU, you throw some job to the GPU, and what you get in the end is a Canvas content, But you don’t really know when the Canvas content is updated. You just know that when you’re going to use it, the browser will synchronize, so it will wait until the job is done. Maybe that browsers actually don’t wait until the job is done there.
Dealing with Workers

François: Another problem I bumped into – actually Jordi mentioned it – is sending video frame to another workers. There’s a bit of a problem when you have a stream of video frame is that across workers, a stream is transferable, and that’s fantastic, but the chunks themselves that are within a stream are not transferred, they are serialized. And the problem with serialization is It doesn’t really duplicate the actual raw pixels, and that’s good. But it requires the sender to call
videoFrame.close()because video frames need to be explicitly closed. They have a lifecycle like this:

And that cannot be done easily because you don’t know when the sending is actually done – when the transfer has taken place – because there’s no way in the Streams API that there’s no place where this gets done. There’s an ongoing proposal to extend streams and allow transfer chunks as well on top of serializing them. I’m glad that this experiment at least prompted some people to progress on that front.
Managing real time processing windows

François: And time flies, and time flies probably on this presentation as well. It’s really hard to keep the processing window that you have and to make sure that everything’s going to work, especially because there are lots of things that happen under the hood.
Managing memory boundaries

François: There’s some measurements there on this slide. Of course, it’s more performant to process a
VideoFramewith WebGPU because it’s highly parallelized by definition. But the problem is that you need to deal with memory copies to do that.VideoFrames are extremely large. These are raw pixels, so they are are extremely large and so memory copies take time. It’s really hard to manage memory copies in practice.
Hardware encoder headaches
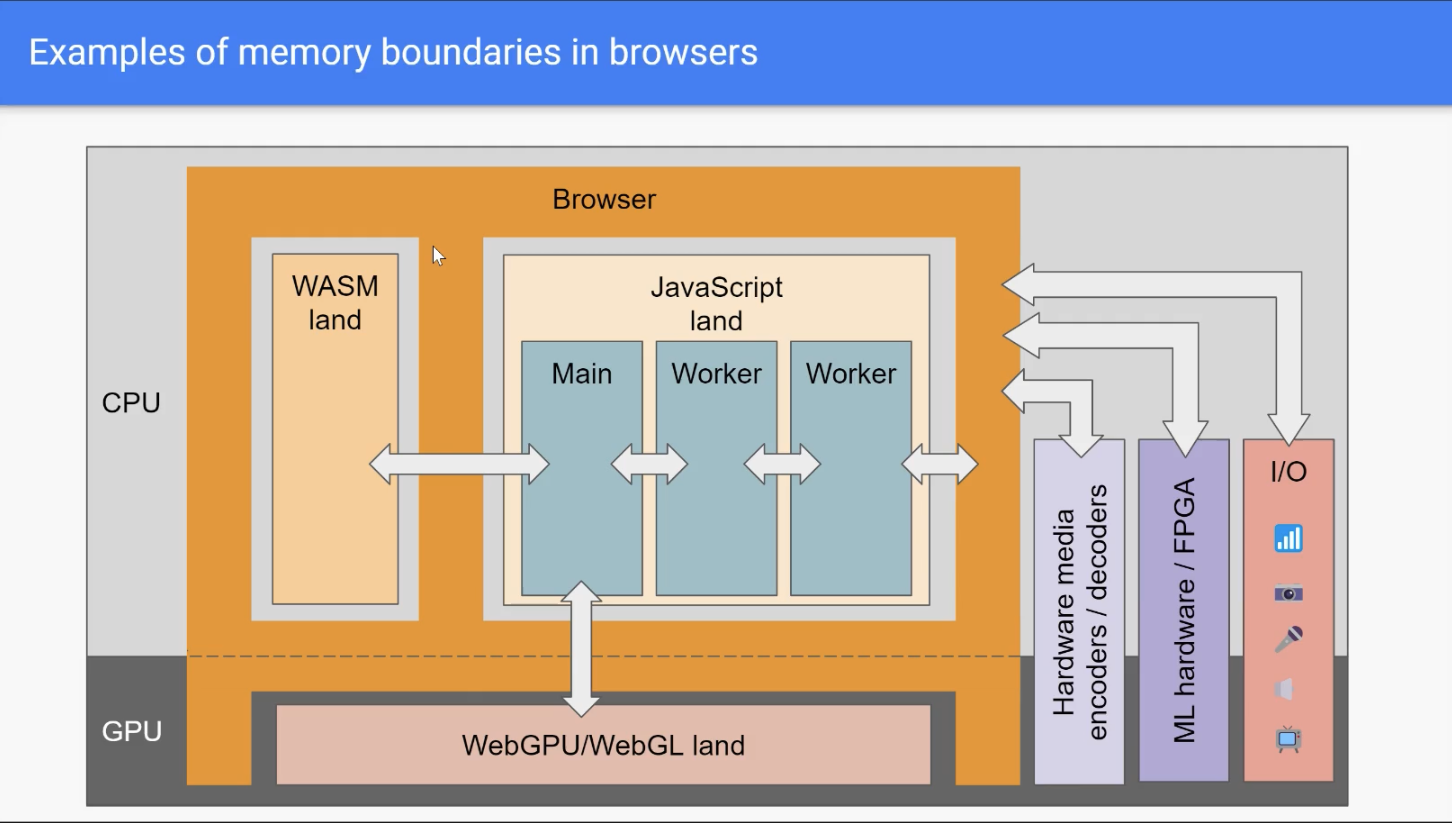
François: It’s [also] not clear whether a browser is going to use a hardware-based encoder or decoder or a software-based decoder, for instance. Even if they use a hardware-based decoder, you don’t really know if it’s GPU-bound in terms of memory or if it’s CPU-bound. Also, memory comes in a variety of forms, and there is some caching involved. Copying a buffer that is hot in cache is extremely fast. Copying a buffer that is not in cache takes much longer. [However] it’s really hard to understand when buffers are going to be copied or not. So here’s an example of the different interfaces that a way to imagine– it’s wrong, I mean, there are many more, but a way to imagine the browser and the memory.
Is it actually faster?

François: An example here of something where you [think the process] is optimized, and in the end, it isn’t really… On the left side [of the image above], I’m just doing some encoding and decoding. The first operation actually copies the video frame to the GPU. And then I’m hoping that actually the encoding step will just use the GPU bound memory and will just be extremely fast.
And on the right side, I’m adding actually an intermediary step, which is the name
backgroundthere, and it actually uses WebAssembly to do a little processing on theVideoFrame. That’s not as fast, but because WebAssembly is a bit slow, that’s normal. But then you realize that the encoding step, which is exactly the same in theory, takes much less when I’m on the right side than on the left side. And that probably means that in this case, the browser decided to use a software-based encoderor at least one that is CPU-bound in terms of memory. And so it makes it really hard to reason about how to optimize things. I think that’s it.
AV1 SVC experiments
Bernard also put together a playground to experiment with WebTransport and WebCodecs. You can see his repo here and experiment with the many configuration knobs with his live demo here.
Chad: That was great! Bernard – I’ll pass it to you to comments about your experiments.
Bernard: So let me clarify, Chad. There are some commercial products using WebCodecs now, but not WebTransport, as far as I’m aware. So in my experiments, I focused on AV1 because I wanted to understand how far along it was. And I can show you an example of the runs that there.
So this is an example with AV1 running at full HD, 30 frames a second. I thought this would be extremely challenging, but it actually did work on both encode and decode. And it pretty much worked on [most] of the hardware I tried – a Mac and a bunch of Windows machines. The big question there was understanding the performance. I was interested in transport, so I used temporal SVC so that not all frames were required to be transmitted.

If you are new here, and unfamiliar with AV1 and SVC, first, congratulations for making this far! We’re exploring the future of RTC, which is not a light topic. AV1 is the newest video codec that is open and royalty free. It the successor to VP9 with most of the big internet companies backing it. AV1 is the next codec to come to WebRTC.
We introduced Scalable Video Coding (SVC) in a past post. It is an efficient mechanism for multiple video qualities – i.e. layers – simultaneously so that a Selective Forwarding Unit (SFU) can manage which layer to send to which viewers. As explained there, there are three kinds of layers – temporal, spatial, and quality. Temporal, like what Bernard used, is often the easiest to manage because you can just ignore a frame if you want a low-layer vs handling multiple frames with different properties for the same timestamp.
Bernard’s demo confirmed he could use AV1 in full-HD with a modest bandwidth of 1.2 Mbps. data matches the <400 ms glass-glass latency
Managing tight timelines
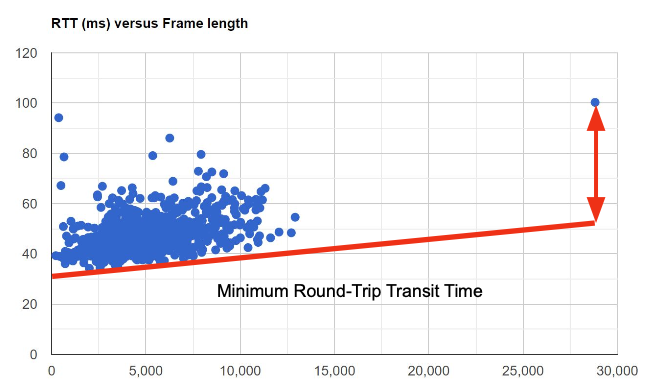
Bernard: Francois mentioned, you have a very, very small time window there where you have to get things through, so you can’t wait too long on transmission. So, I implemented partial reliability on top of the frame per stream – transport and WebTransport. Then I would for the discardable frames – the ones that had the higher temporal layers – would give up if it exceeded that limit.
So, you can see, in general, you had fairly tight frame RTTs, with the exception of the I-frames, which took considerably longer. I discovered the reason for that is that the congestion window in QUIC is too small to send the I-frame in a single round trip. So, it takes multiple round trips. There’s this weird interaction of the congestion window and the I-frame.
requestVideoFrameCallback latency measurements
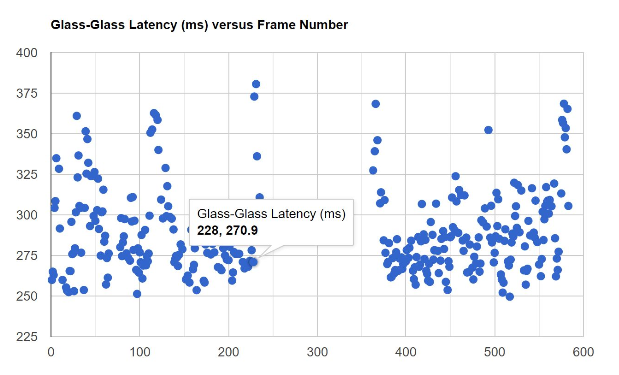
Bernard: The other thing I found is I used RVFC (requestVideoFrameCallback), as Francois mentioned, to try to get the glass-to-glass latency. In an RVFC , I think that’s represented by presentation time minus capture time, using the media time as the unique identifier, as Francois said.
requestVideoFrameCallback is another newer API that fires the callback when a <video> element presents a frame for composition. It’s useful for synchronizing your code with whatever frame is displayed. It is also handy as frame measurement system as Bernard and François did in their experiments.
For the reason François noted, Bernard did not get measurements on every frame, but you can see he was able to get less than 400ms of glass-to-glass latency, similar to what Jordi showed.
Bernard: But you can see there’s some weird things here. First of all, in the [above] diagram, it looks like there’s a fairly regular spike going on. In addition, RVFC isn’t guaranteed to give you every frame. So I didn’t get metadata on every [output] frame. So anyway, there’s something I don’t quite understand [what is] going on here. The frame RTTs don’t show those same spikes, or maybe they do actually, but not quite as bad. So that’s an interesting thing. At least AV1 in software did seem to be usable for both encode and decode, which surprised me. I didn’t expect that to happen. One of the things to follow up is to understand where some of these spikes are occurring in the system and whether there’s queuing going on the WHATWG streams.
Bernard mentioned later there was a significant difference in the round-trip-time (RTT) – the over the wire speed – and the glass-to-glass latency – the speed the actual images are rendered. If the browser could process the incoming stream instantly, then these numbers should be the same. The fact that they weren’t and that they diverge more at higher resolutions is an indicator the browser’s processing is significant here.
Jordi’s challenges
Chad: Jordi, can you talk for a little on your conclusions from your experiments? What were you he happy with? What weren’t you happy with?
Jordi: By the way, Bernard, I wasn’t expecting everything to work in real time either. Congratulations – that is impressive. Also, I really like the Francois’s explanation because I was hitting a lot of the things that he was explaining. I learned a lot from his explanation.
Audio and video synchronization is hard
Jordi: So, to [touch on] what didn’t work and what was challenging when I was implementing the demo. As I said, audio and video synchronization [was hard]. So as Francois mentioned, video timestamps survive the encoding and decoding stages, but not audio timestamps. Then if you want to align video and audio, you will have a hard time, because audio can be dropped. Video too, but since video since has a unique timestamp, that it’s an easy problem [since you know what to retransmit]. Audio, is much more challenging. If it drops something, you need to know exactly how much dropped to compensate for those [lost] timestamps and basically align them. So, this is one of the main challenges that I spend a lot of time. I think I more or less solved it, but with a lot of hacks that I’m not happy with. I would love for the audio timestamps to be the same as video timestamps. So basically, to be persistent across all the flow, and then everything will be much simpler and I could remove half of my code. So that is the main thing.
AudioFrame’s are not transferrable
Jordi: Then a small thing that also complicated my life building that [Proof of Concept] (PoC) – [was that] I realized that AudioFrame is not transferable. Though audio data – that is the coded data – is transferable. It is a big performance hit because there are a lot of [of them]. [Audio data] is not big, but there are a lot of frames. 21 milliseconds [of data] for every frame. So that’s a lot of copies.
Note the W3C spec even calls Audio Frames AudioData vs. VideoFrame for video. This naming was changed because the now AudioData can contain multiple samples which some may not consider to be a “Frame”. (Discussion here.)
Hardware acceleration mysteries
Jordi: What else? Oh yeah [there is another] small thing that definitely took me hours to figure out – that was six months ago probably, so perhaps it’s fixed. When I was trying video decoding with the default [settings] that uses hardware acceleration, nothing was working. [I was getting very weird performance problems – all would be ok and then it suddenly stopped working, or it would start going super slow. I added counters everywhere and all seemed to point to the webcodecs video decoder, so so I finally changed the hardware acceleration settings, to
prefer_softwareand everything was fine since then.] This is probably something related to what Francoise was talking about, doing behind the scenes, doing copies or not doing copies.So those were the challenges.
Jordi’s Performance status
Jordi: I don’t know if I want to show you a couple of numbers of my experiments now.
Chad: Yeah, why don’t we do that.
Jordi: Yeah. Yes, so basically, I did this demo last week. Now I’m in San Francisco. I have a relay server in Oregon. I measure around Round Trip Times – it’s around 36 milliseconds.
Then I did the demo with a live stream from San Francisco going back and forth to Oregon:

And the end-to-end latency, glass-to-glass, was with a very good. No drops, very smooth. It was 140 milliseconds.
[I also implemented an automatic latency measurement in the player based on the clock data inserted at every frame, but I recognize it’s not super accurate. So here I’m showing the latency I measured with a clock in front of the camera]:
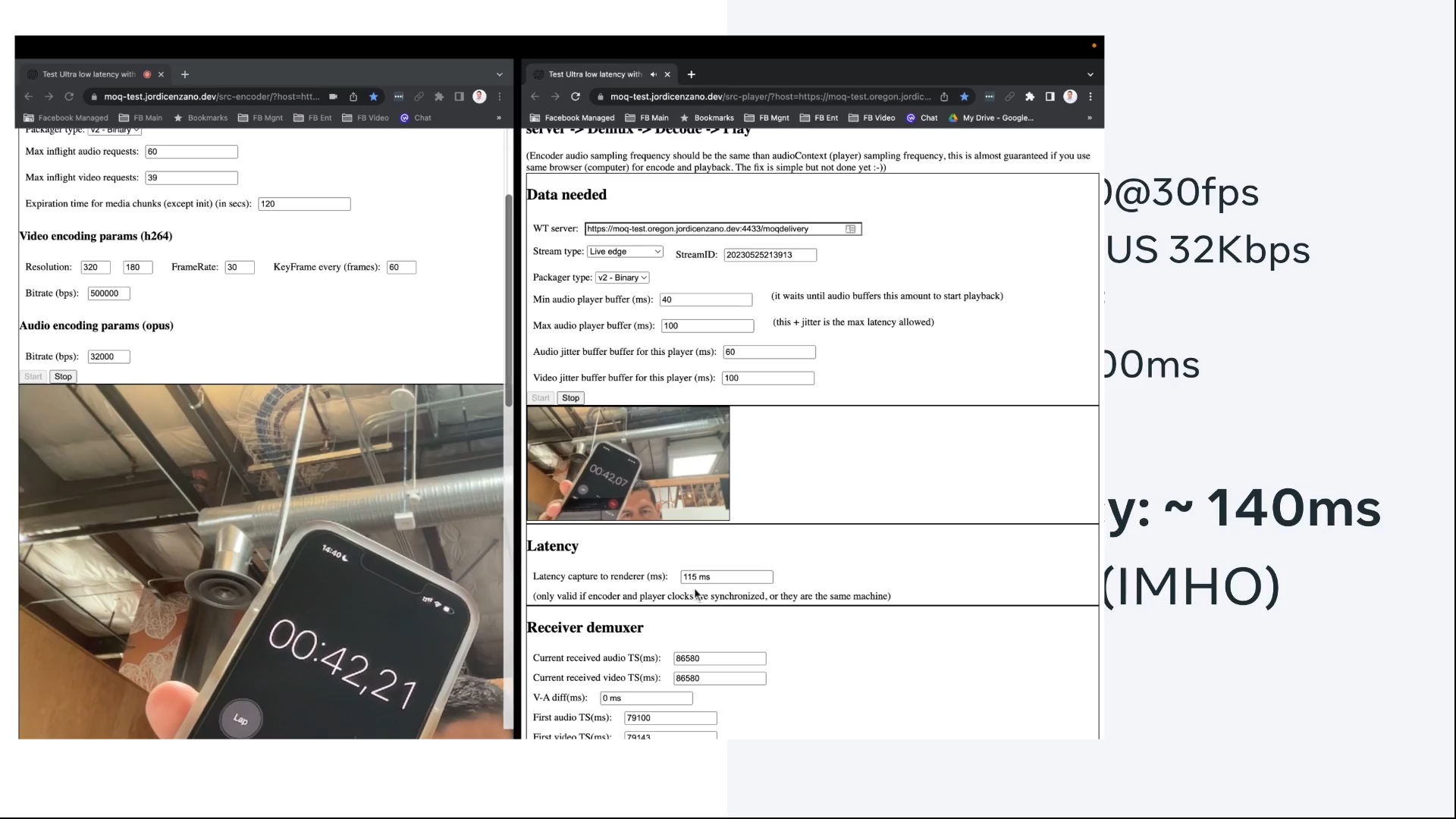
Here it says 115, but the real one, the glass to glass real, you can see it’s 140.
You can subtract the time in the image on the left above from the one on the right to see the difference in latency from the sender to the receiver.
Jordi: This was a very easy one, but then I did this:

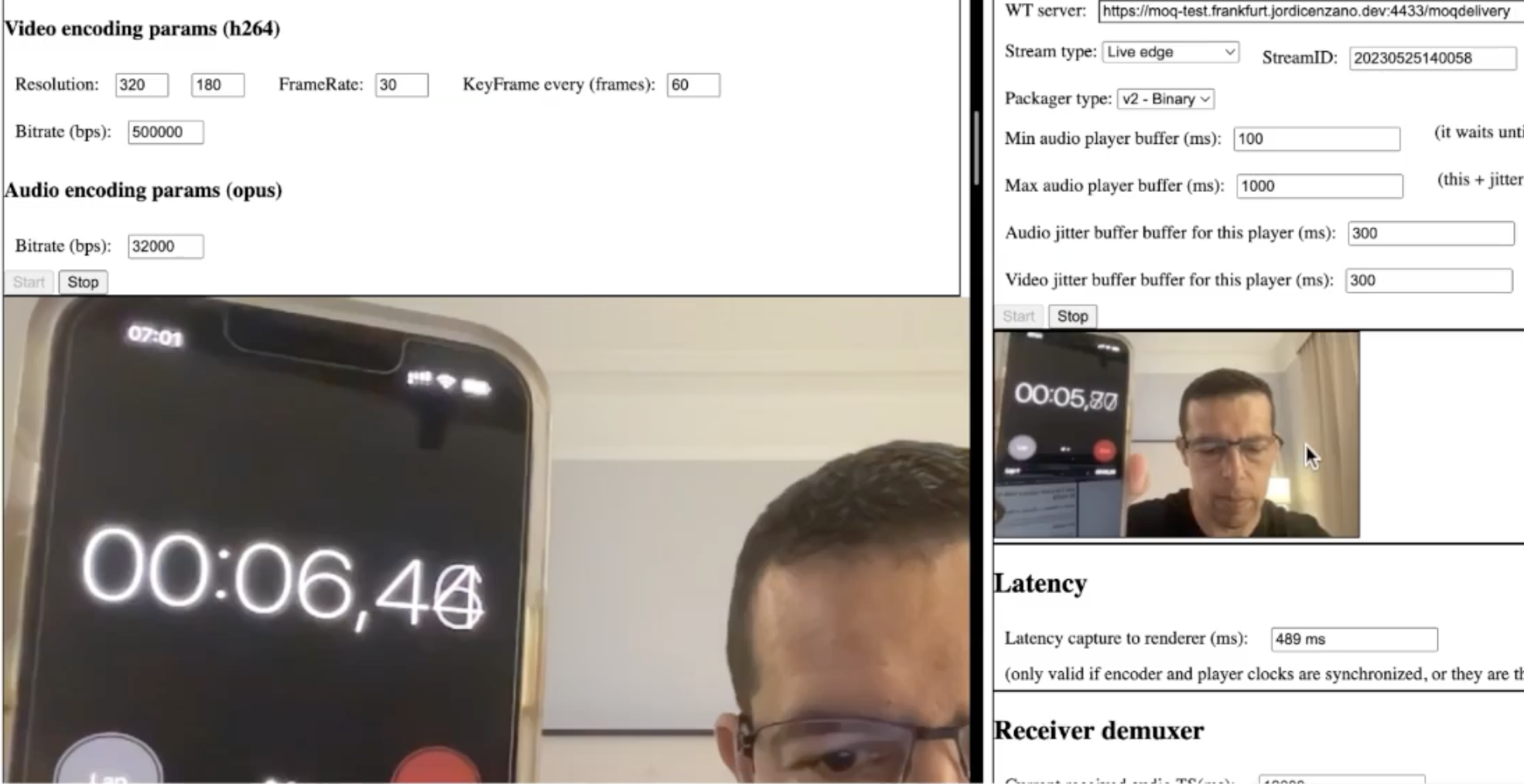
I increased the resolution and the bitrate. Then the latency was a bit higher, 380 [ms].
And another one- I did exactly the same experiment, but now the relay, I put it in Frankfurt in Europe. That’s a round trip time of 167 milliseconds, more or less:
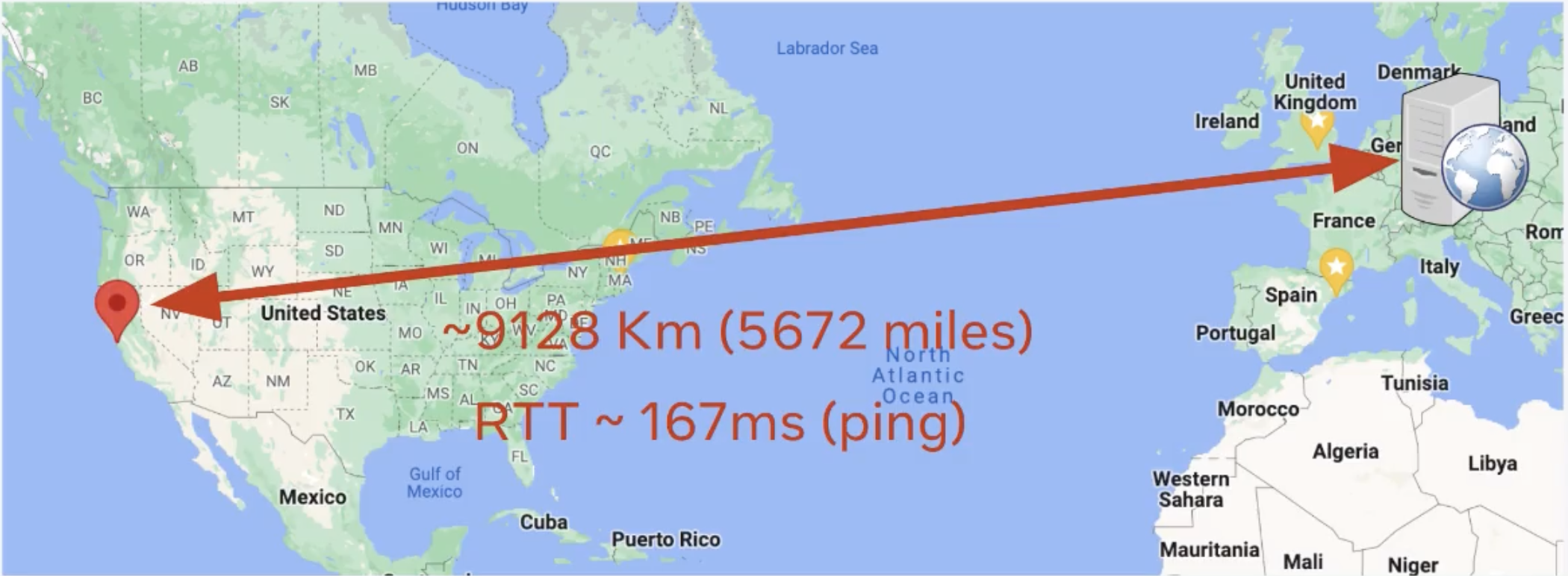
And the latency, as you can imagine, with 500 kilobits per second, increased real glass to glass to almost 700 milliseconds:

And this is important to mention that this is without send order. So we are not prioritizing [which packets should come first] here. I would say [my first example shows ] the lowest bound, and [the San Francisco to Frankfurt example] is the highest bound in this case. From here, we can add mechanisms to improve.
So Jordi ended up with a glass-to-glass latency range of 140ms in a lower-resolution, regional test to 690ms at 500 kbps, US to Europe test. Bernard’s AV1 tests at full HD had glass-to-glass latency of <400ms with AV1 running 1920x1080p consuming around 1.2Mbps. These numbers are in the right ballpark, but it seems there is a ways to go before the W&W approach is ready. Are we going to get there?
Will WebCodecs+WebTransport get good enough for practical use?
Chad: Great, thanks! It seems like we’re close or like getting closer, but there’s still a lot of pretty significant challenges here. Do you all think this [WebTransport + WebCodecs approach] is going to work?
Bernard: It’s a maturity process. I’ve heard a lot from developers, very similar to what Jordi said, particularly [around] the availability of hardware acceleration, losing the hardware acceleration, going to software. etc. It’s early days for WebCodecs. And I think we’re going to mature. We’re going to get more support. For example, for HEVC, we’re still working [support for hardware acceleration and adding] encoding parameters. I’d say we’re probably a year away from being more mature. So, there are that set of things..
And then there are the WHATWG Streams issues.
Chad: Can you add to that, Francois?
François: No, that’s correct. One thing to add, is that some of these steps actually touch on different blocks being developed by different sets of people. One of the difficulties is that everyone wants things to work, but it’s no one’s priority in the sense that it’s not in the specific scope of any specific group. So, you have lots of collaboration and coordination work across groups which takes time, unfortunately.
Bernard: Yeah, I think there are seven different W3C working groups working on the APIs we’ve been talking about today, right? Because it’s WebGPU, WebGL, WebTransport, WebCodecs, WebRTC stuff..
MSE and Insertable Streams / Breakout Box are the other two. François also covered WebNN in his Video Processing on the Web post here.
What’s Next
Chad: To close out, we can talk more about what’s next and how do we get there?
Standards coordination challenges
Bernard: TPAC is coming up in W3C, François, so we should probably talk about how to herd the cats. It’s not easy. A lot of these issues we’re describing are between groups. WebCodecs [and MSE] is owned by the Media Working Group. WebCodecs has shipped in Chrome. [WebCodecs] is being worked on in Safari for video only. So, we’re going see that.
WebTransport is shipping in Chrome and it just recently shipped in Firefox 114.
Then a bunch of the other APIs are mostly in Chrome. BreakoutBox is in Chrome and Insertable Streams are in Chrome. There’s a version of both of those, I think, in Safari. Then there’s the rendering APIs. WebGPU, I would still say, is not mature, but it’s coming along. WHATWG Streams, which is in another standards body entirely, right, which is the WHAT Working Group. So definitely a lot of coordination challenges here.
And of course, WebAssembly is used for a lot of this. But there’s developers, like the folks on this call, and then there’s all the working groups. As Francois said, a lot of cats to be herded.
Chad: Francois, other than yourself, is this someone driving this kind of use case or this application [in the W3C]? It seems like a tough problem without having somebody do that.François: Driving? It’s more people like Bernard who are going to drive discussions in the W3C. My rule is to make sure that make sure that these discussions happen and
Bernard: Yeah. Francois has been very helpful in identifying missing things.
One of the big issues is conversion between all these different APIs and doing it with zero copies. That’s the key. I know you filed a bunch of bugs, Francois. Youenn Fablet of Apple’s been filing lots of bugs on what WHATWG Streams and Media Processing. But anyway, we should have a chat about how to have more highlight on this in TPAC.

What will happen with HDR?
François: Just to add to the mess, one dimension that we didn’t mention is media folks love HDR content as well. Right now the web is not really good at HDR support. So you have another dimension there which is [that] extension to Canvas, [that] extension to WebGPU, [that] extension to ECMAScript, actually
Bernard: I think it’s great to have these experiments. They identify the pieces that are missing, and that’s why they’re so important.
Are there commercials drivers behind this?
Bernard, François, and Jordi were here primarily as representatives of various standards bodies. As my last question, I wanted to circle back and ask Bernard and Jordi if Microsoft and Meta are as excited about W&W as they are.
Chad: This is maybe more a question for Jordi and Bernard – if you put on your vendor hat on. Why are you driving this? Is there [eventually] going to be an application that somebody wants to build?
Bernard: Well, there are the kind of scenarios that Jordi talked about – low latency streaming opens up, but also just in conferencing, you can do all the video processing that Francois has been talking about. You know, machine learning is a huge deal now and getting the performance you need out of [web applications], is not easy. So, you know, people expect noise cancellation, all kinds of video effects – getting all this done within that time window, particularly when you’re moving to these new codecs like AV1 and HEVC, it’s pretty challenging. So there’s definitely motivation.
My personal view is the connection between the developers and the feedback loop isn’t as tight as it should be. I listen to developers all day. I get a lot of complaints, but perhaps not as many as I should get.
Chad: Okay. Well, Jordi, you gave a few complaints today, I guess. Do you have any more for Bernard?
Jordi: I will keep those [I referenced] just for now. More will come for sure. But what I see here is that I will be talking more about the media over QUIC.
So, if [Media over QUIC] is successful, the idea is that it will cover a lot of use cases, starting as Bernard mentioned for video conferencing, live streaming, live streaming to masses, so one to one million, video conferencing one-to-one, and also ingest-side and player-side. I think if it’s successful, and I’m hoping it is successful obviously, it could be a huge simplification of the current streaming in world. Having a single protocol that can cover all use cases, that works on the CDN side, [that] works on the player side.. It’s also [about] developer efficiency. You don’t need to learn WebRTC, RTMP, SRT, and all of those “things”, and then choose the one that fits your use case, and then do N conversions.
I really hope the MoQ is successful. Again, it’s early stages. I think now we have something almost ready for adoption, but it’s not yet there. But definitely, if it’s successful, it could be a huge help for the streaming world.
Bernard: Yeah, I think what we’ll do is we’ll simplify your life with [respect to] protocols, Jordi, and make it more complicated with [respect to] APIs.
[laughing]
Jordi: Okay, yeah, that’s a way to see it. But let’s hope that APIs are better than the protocols.
[laughing]
Many thanks to Bernard, François, and Jordi for sharing their knowledge during the discussion and the even larger amount of time spend preparing! We will continue to follow their various projects to see how the W&W approach matures.
{
“Q&A”:{
“interviewer”: “chad hart“,
“interviewee”: [“Bernard Aboba“, “François Daoust“, “Jordi Cenzano Ferret” ]
}
}




Thanks for the great talk. I am currently working on a machine learning project sending JSON data between two peers using event sourcing. Would love to have a P2P standard handy… WebRTC is good, but has no worker support.