Deploying media servers for WebRTC has two major challenges, scaling beyond a single server as well as optimizing the media latency for all users in the conference. While simple sharding approaches like “send all users in conference X to server Y” are easy to scale horizontally, they are far from optimal in terms of the media latency which is a key factor in the user experience. Distributing a conference to a network of servers located close to the users and interconnected with each other on a reliable backbone promises a solution to both problems at the same time. Boris Grozev from the Jitsi team describes the cascading SFU problem in-depth and shows their approach as well as some of the challenges they ran into.
{“editor”: “Philipp Hancke“}
Real-time communication applications are very sensitive to network conditions such as throughput, delay, and loss. Lower bitrates lead to lower video quality and longer network latency leads to a longer end-to-end delay in audio and video. Packet loss can lead to “choppy” audio and video freezes due to video frame skipping.
Because of this it is important to select an optimal path between the endpoints in a conference. When there are only two participants this is relatively straightforward – the ICE protocol is used by WebRTC to establish a connection between the two endpoints to exchange multimedia. The two endpoints connect directly if possible, and otherwise use a TURN relay server in less typical situations. WebRTC supports resolving a domain name to get the TURN server address, which makes it easy to select a local TURN server based on DNS, for example by using AWS Route53’s routing options.
However, when a conference has more participants routed through a centralized media server the situation is much more complex. Many WebRTC services like Hangouts, appear.in, Slack, and our own meet.jit.si, use a Selective Forwarding Units (SFU) to more efficiently relay audio and video among 3 or more participants.
The Star Problem
In this case all endpoints connect to a central server (in a star topology) with which they exchange multimedia. It should be obvious that selecting the location of the server has a huge impact on user experience — if all participants in the conference are located in the US, using a server in Sydney is not a good idea.
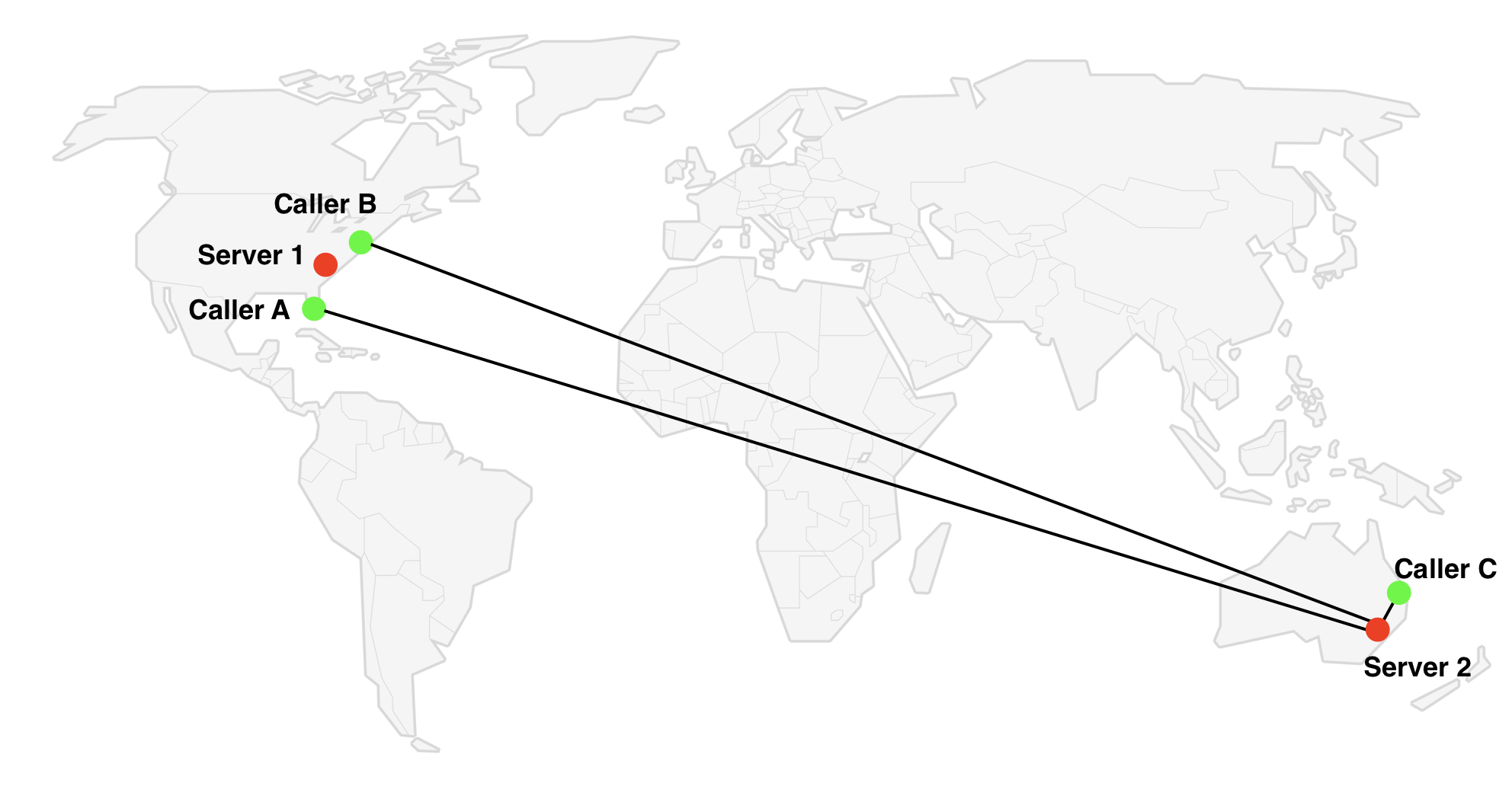
Most services use a simple approach which works well a lot of the time — they select a server close to the first participant in the conference. However, there are some cases where this isn’t optimal. For example, suppose we have the three participants as shown in the diagram above – two are based on the East Coast of the US and the third is in Australia. If the Australian participant (Caller C) joins the conference first, this algorithm selects the server in Australia (Server 2), but Server 1 in the US is a better choice since it is closer to the majority of participants.
Scenarios such as these are not common, but they do happen. Assuming the order in which participants join is random, this happens in ⅓ of conferences with 3 participants where one is in a remote location.
Another scenario which happens more often is illustrated in the diagram below: we have two groups of participants in two locations. In this case the order of joining doesn’t matter, we will always have some pairs of users that are close to each other, but their media has to go through a server in a remote location. For example, in the image below there are 2 Australian callers (C&D) and 2 US callers (A&B) .
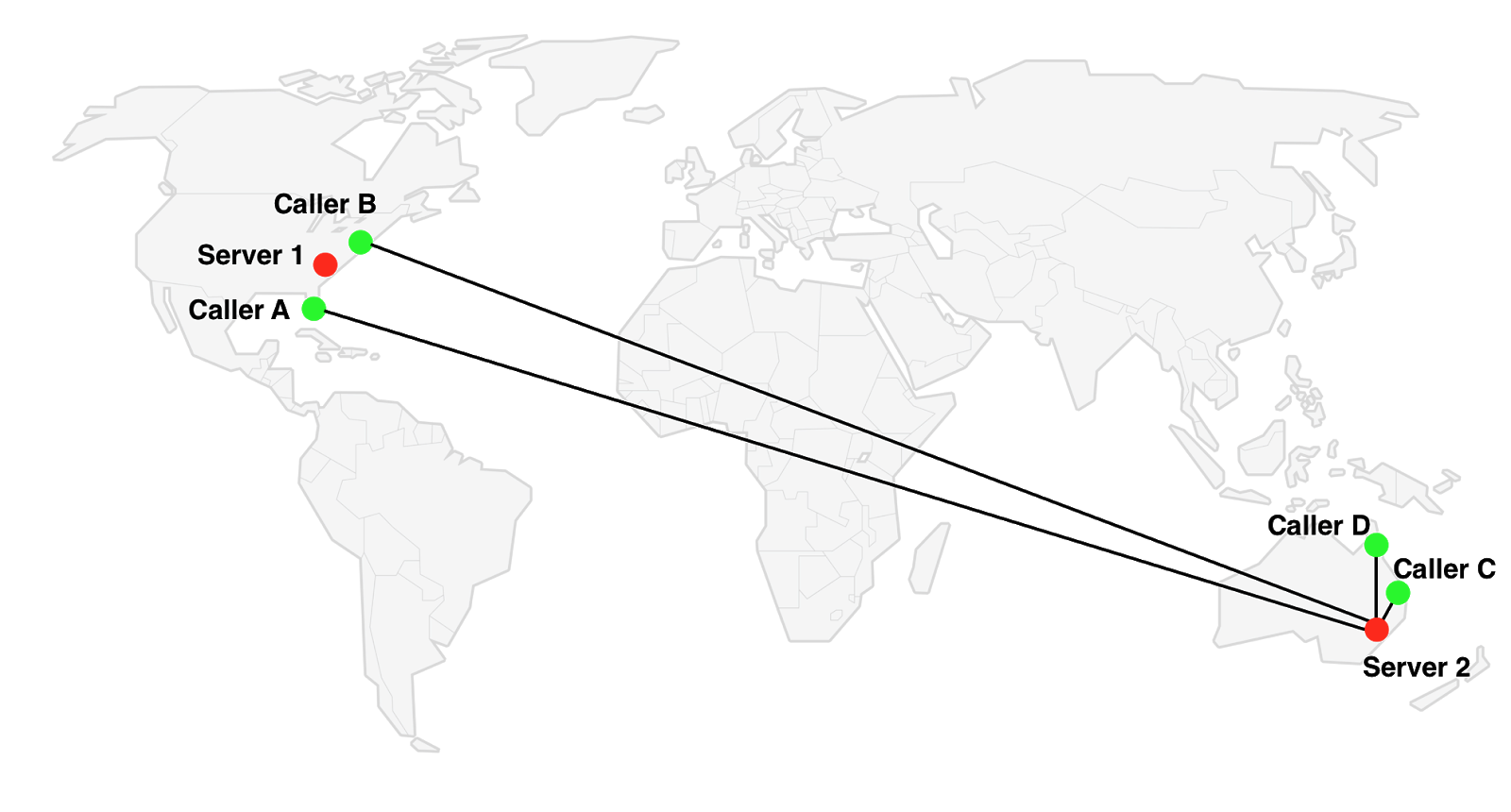
Switching to Server 1 is non-optimal for Callers C&D. Server 2 is non-optimal for callers A&B. Whether we use Server 1 or Server 2 there will be some participants connected through a non-optimal remote server.
What if we weren’t limited to using one server? We could have every participant connected to a local server, we just have to interconnect the servers.
Solution: Cascading
Postponing the question of how do we actually interconnect the servers, let’s first look at what effect this has on the conference.
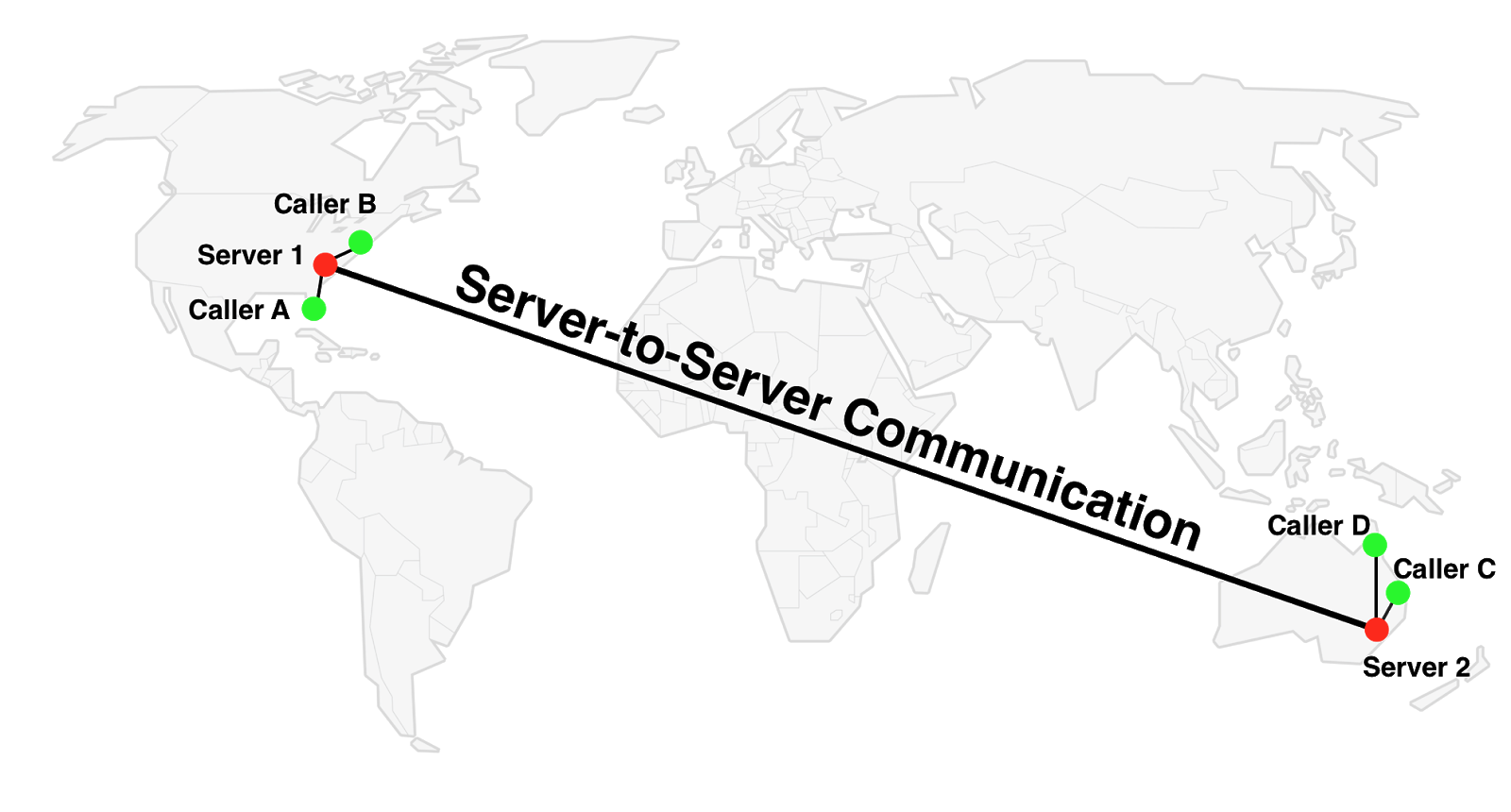
The SFU connection from C to D hasn’t changed – that still goes through Server 2. For the connection between A and B we use Server 1 instead of Server 2 as in the previous diagram which is obviously better. The interesting part is actually the connection from A to C (or any of the others, for which the effects are analogous). Instead of using A<=>Server 2<=>C we use A<=>Server 1<=>Server 2<=>C.
Non-intuitive trip time impacts
Connecting SFU bridges like this has advantages and disadvantages. On the one hand, our results show that in such situations the end-to-end round-trip-time is higher when we add additional hops. On the other hand, reducing the round trip time from the client to the first server that it is connected to has an advantage on its own, because we can perform stream repair with lower latency on a hop-by-hop basis.
How does that work? WebRTC uses RTP, usually over UDP, to transfer media. This means that the transport is not reliable. When a UDP packet is lost in the network, it is up to the application to either ignore/conceal the loss, or request a retransmission using an RTCP NACK packet. For example the application might chose to ignore lost audio packets, and request retransmission for some but not all video packets (depending on whether they are required for decoding of subsequent frames or not).
With cascaded bridges, these retransmissions can be limited to a local server. For example, in the A-S1-S2-C path, if a packet is lost between A and S1, S1 will notice and request retransmission. If a packet is lost between S2 and C, C will request retransmission and S2 will respond from its cache. And if a packet is lost between two servers, the receiving server can request a retransmission.
Clients use a jitter buffer to delay the playback of video, in order to allow for delayed or retransmitted packets to arrive. The size of this buffer changes dynamically based in part on the round-trip time. When retransmissions are performed hop-by-hop, the latency is lower, and therefore the jitter buffer can be shorter, leading to lower overall delay.
In short, even though the end-to-end round-trip-time is higher with an extra server, this could lead to lower end-to-end media delay (but we have yet to explore this effect in practice).
Implementing a Cascading SFU
So how do we implement this in Jitsi Meet, and how do we deploy it on meet.jit.si?
Signaling vs. Media
Let us look at signaling first. Since its inception, Jitsi Meet has separated the concept of a signaling server (which is now Jicofo) and a media server/SFU (jitsi-videobridge). This separation allowed us to implement support for cascaded bridges relatively easily. For one thing, we could just keep all the signaling logic in a central place — Jicofo. Second, we already had the protocol for signaling between Jicofo and Jitsi Videobridge (COLIBRI). We only had to add a small extension to it. We already had support for multiple SFUs connected to one signaling server (for load balancing). Now we had to add the option for one SFU to connect to multiple signaling servers.
We ended up with two independent pools of servers — one pool of jicofo instances and one pool of jitsi-videobridge instances. The diagram below illustrates part of this.
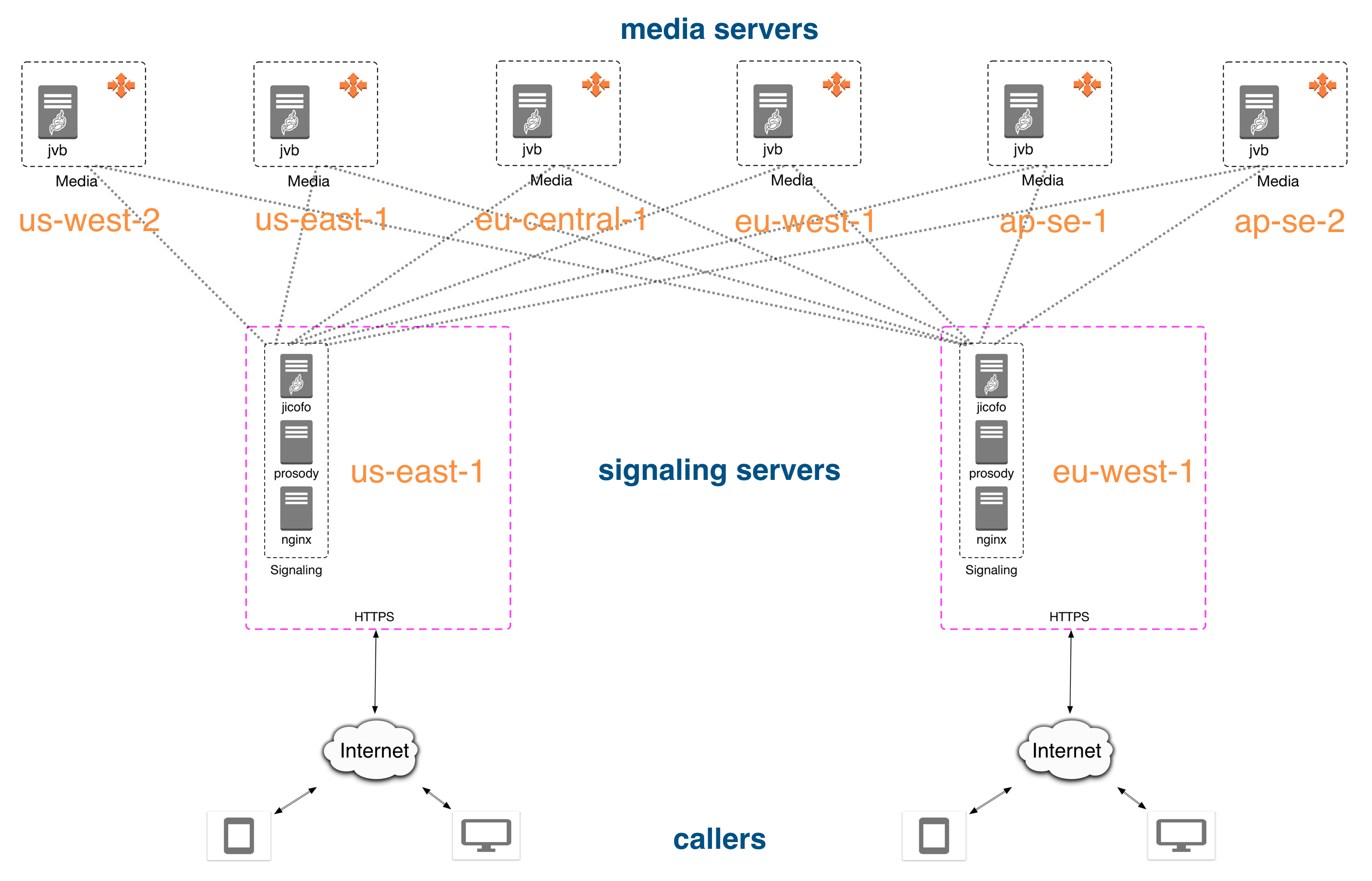
The second part of our system is the bridge-to-bridge communication. We wanted to keep this part as simple as possible, and therefore we decided to not do any explicit signaling between the bridges. All signaling happens between jicofo and jitsi-videobridge, and the connection between two bridges is only used for audio/video and data channel messages coming from clients.
The Octo protocol
To coordinate this communication we came up with the Octo protocol, which wraps RTP packets in a simple fixed-length header, and allows to transport string messages. In the current implementation, the bridges are connected to each other in a full mesh, but the design allows for other topologies as well. For example, using a central relay server (a star of bridges), or a tree structure for each bridge.
Footnote: Note that instead of prepending the Octo header it could be added as an RTP header extension, making the streams between bridges pure (S)RTP. Future versions of Octo might use this approach
Second footnote: Octo doesn’t really stand for anything. We were initially planning to use a central relay, and for some reason it reminded us of an octopus, so we kept that name for the project.
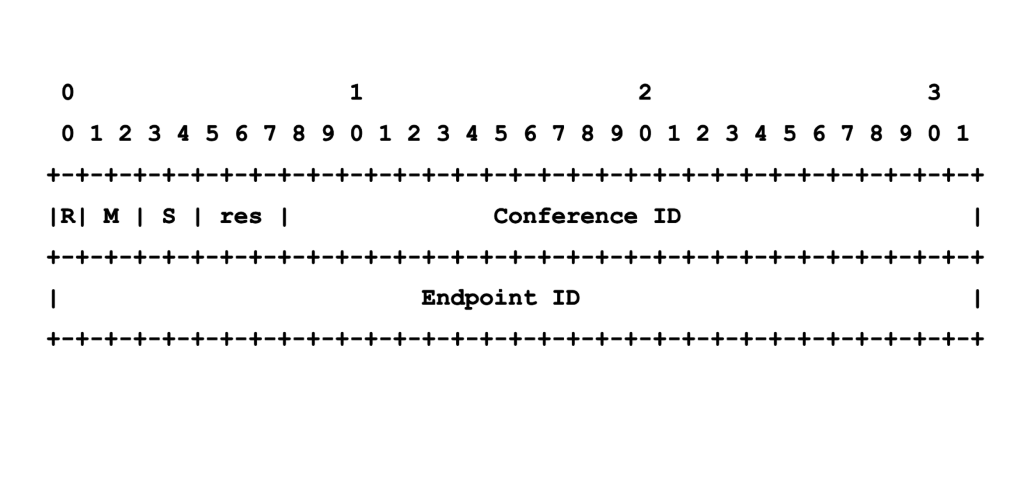
In the Jitsi Videobridge terminology, when a bridge is part of a multi-bridge conference, it has a an additional Octo channel (actually one channel for audio and one for video). This channel is responsible for forwarding the media to all other bridges, as well as receiving media from all other bridges. Each bridge binds to a single port for Octo (4096 by default), which is why we need the conference ID field to be able to handle multiple conferences at once.
Currently the protocol does not have its own security mechanism and we delegate that responsibility to lower layers. This is something that we want to work on next, but for the time being the bridges need to be in a secure network (we use a separate AWS VPC).
Use with Simulcast
One of the distinguishing features of Jitsi Meet is simulcast where each participant sends multiple streams of different bitrates and the bridge helps select the ones that are needed. We wanted to make sure that this continues to work robustly, so we forward all of the simulcast streams between the bridges. This allows for quicker switching between streams (because the local bridge doesn’t have to request a new stream). However, it is not optimal in terms of bridge-to-bridge traffic, because some of the streams are often not used and just consume exra bandwidth for no benefit.
Active Speaker Selection
We also wanted to continue to support following the active speaker in a conference (giving them the most real estate). This turned out to be easy — we just have each bridge do the dominant speaker identification independently, and notify its local clients (this is also the approach others have used). This means that the calculation is done multiple times, but it is not expensive, and allows us to simplify things (e.g. we don’t have to decide which bridge does DSI, and worry about routing the messages).
Bridge Selection
With the current implementation, the bridge selection algorithm is simple. When a new participant joins, Jicofo needs to decide which bridge to allocate to it. It does so based on the region of the client and the regions and load of the bridges available to it. If there is an available bridge in the same region as the client, it’s used. Otherwise, one of the existing conference bridges is used.
For documentation about setting up Octo, see here.
Deploying Cascading SFU’s
We have now enabled geographical bridge cascading, as described above, on meet.jit.si.
For this deployment we run all machines in Amazon AWS. We have servers (both signaling and media) in six regions:
- us-east-1 (N. Virginia),
- us-west-2 (Oregon),
- eu-west-1 (Ireland),
- eu-central-1 (Frankfurt),
- ap-se-1 (Singapore) and
- ap-se-2 (Sydney).
We use a layer of geolocated HAProxy instances which help to determine which region a client is coming from. The meet.jit.si domain is managed by Route53 and resolves to an HAProxy instance, which adds its own region to the HTTP headers of the request it forwards. This header is then used to set the value of the config.deploymentInfo.userRegion variable made available to the client via the /config.js file.
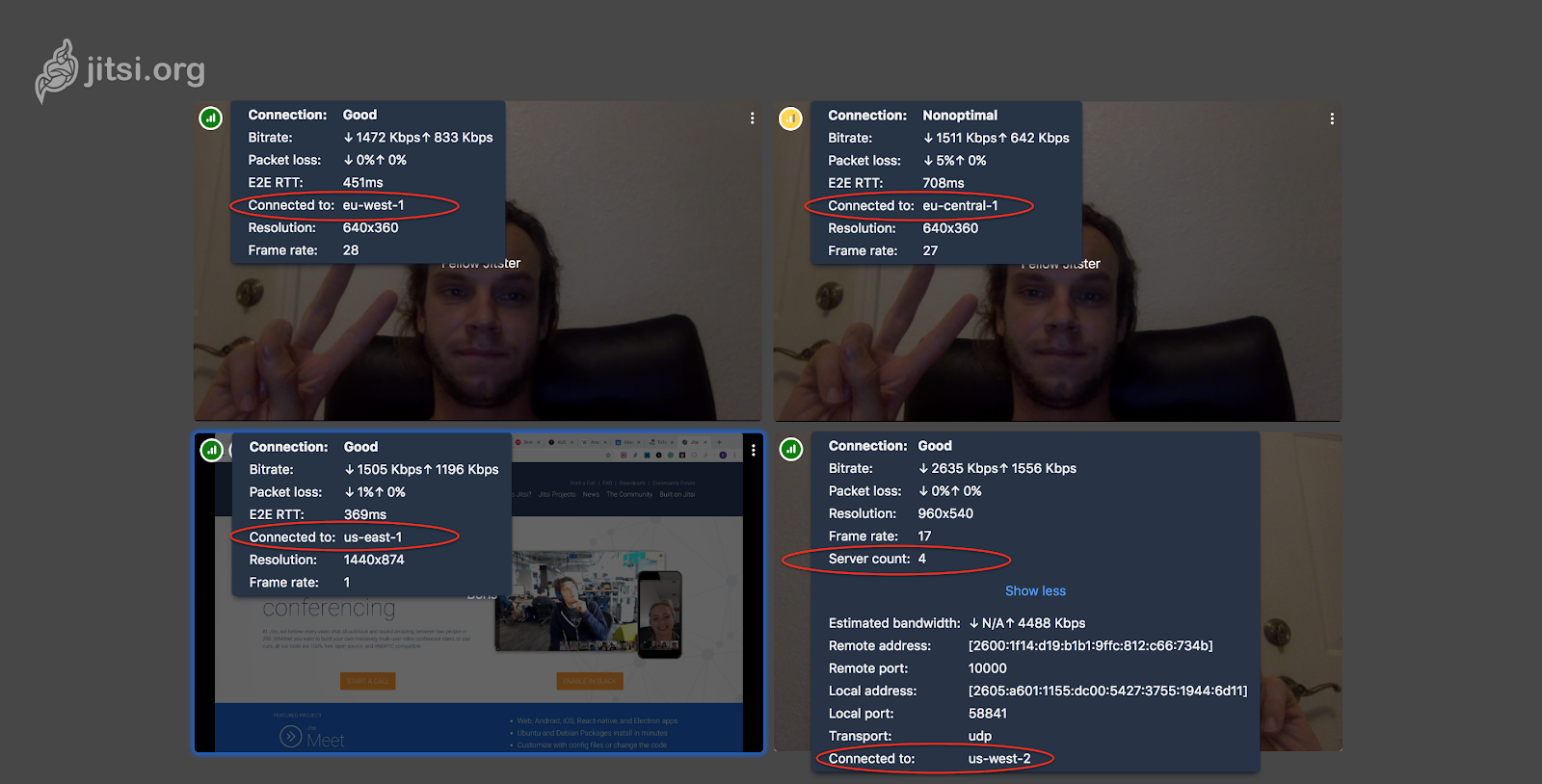
For diagnostics and to demonstrate this feature, the user interface on meet.jit.si shows how many bridges are in use, and where each participant is connected to. Scrolling over the top left part of your local thumbnail shows you the number of servers and the region of the server you are connected to. Scrolling over a remote thumbnail shows you the region of the server the remote participant is connected to, and the end-to-end round trip time between your browser and theirs (as E2E RTT).
Conclusion
We initially launched Octo as an A/B test on meet.jit.si in August. The initial results looked good and it is now enabled for everyone. We have a lot of data to go through and we are planning to look at how well Octo performs in detail and write more about it. We are also planning to use this work as the first stepping stone towards supporting larger conferences (for which a single SFU is not sufficient). So stay tuned for more about this in the coming months.
If you have any questions or comments, you can drop us a message on our community forums, or join our bi-weekly community conference call.
{“author”, “Boris Grozev”}





Hi, very interesting! Do you have plans to make jicofo (signaling) failover?