mediasoup was one of the second-generation Selective Forwarding Units (SFUs). This second generation emerged to incorporate different approaches or address different use cases a few years after the first generation of SFUs came to market. mediasoup was and is different. It is node.js-based, built as a library to be part of a serve app, and incorporated the Object-oriented approaches used by ORTC – the alternative spec to WebRTC at the time. Today, mediasoup is a popular SFU choice among skilled WebRTC developers. mediasoup’s low-level native means this skill is required.
I interviewed mediasoup’s co-founder, Iñaki Baz Castillo, about how the project got started, what makes it different, their recent Rust support, and how he maintains a developer community there despite the project’s relative unapproachability. Iñaki has long been involved with WebRTCs standardization and frequently has a few webrtcHacks posts that advocated for an object approach. I am happy I was able to pin him down for this interview.
Related sidenote: mediasoup cofounder, José Luis Millán will be joining me along with leads from pion, Jitsi, and Janus to discuss the latest in Open Source WebRTC tomorrow at Kranky Geek. Sign-up here for the livestream details.
- How mediasoup got started
- How is mediasoup different?
- WebRTC Challenges
- Features & Roadmap
- Performance and Scale
- Community and Support
{“editor”, “chad hart“}

How mediasoup got started
I first came across Iñaki when looking at JsSIP, a nifty SIP over WebSockets client library that played well with WebRTC gateways – devices that connect more traditional phone systems to WebRTC in the browser. I actually had never heard the story about how he went from there to building a Selective Forwarding Unit (SFU) system.
Chad: One of the first opensource projects I used of yours was JsSIP under Versatica. Can you tell me a little bit more about Versatica organization and some of your early projects there?
Iñaki: Yeah. Okay. The Versatica organization is just something to keep all the projects. I started with Jose [Millán], which is a friend of mine, also coworker, and the one that I’ve been working with for years in professional companies, but also in this opensource project. So, it’s just an organization. There is nothing else, other than the GitHub organization to hold all the opensource projects, mediasoup, JsSIP, and things like that.
Chad: Can you tell me a little bit about how mediasoup got started?
Iñaki: So, I have to talk about JsSIP first, because everything started with that. We started JsSIP, because we anticipated the way [to make calls] in the future would be with microphone and camera access within web applications.
We both have a very deep knowledge about SIP. We knew WebSockets – we were not experts on this matter at all, but it was easy to get all the knowledge on that. So, we started coding JsSIP, and at the same time we started reading the WebSocket transport for SIP draft in the W3C, which finally ended becoming a real specification. The funny thing here is that we wrote the first version of JsSIP before WebRTC was available in browsers.
In fact, I remember a talk that we gave in Madrid at some conference. We did a demo with JsSIP. At that time we were working in a telco company in Madrid, so we had access to number routines. So, we were able to tell the people in the audience to call a regular phone number [and we would answer in JsSIP]. All the people were like, “Wow, this is amazing.”
[Eventually] WebRTC came in, we just integrated it, so that’s how it started.
Many people from the telco world got into WebRTC via a similar path (I did ☺ ). Going from there to building an SFU-based multi-party calling system is a whole other leap. This was particularly the case base in 2014 when that was a new concept.
Iñaki: After that, this was a personal matter on my side. I felt like, okay, we have created JsSIP, but this is too constrained to telco work. This is just for telephony at the end. You could build applications on top of it, but this is overkill for many things. For some reason I was interested in multi-conference applications. I lacked a server. [The conferencing use case] is not just about signaling, but also about media transmission. So, I started taking a look at existing solutions like Jitsi, or Janus, but I didn’t like any of them for my purpose. In the case of Jitsi, obviously it’s not something that you can use to [develop] your application since it is an application itself.
Janus is much more flexible but I didn’t like the idea of having an standalone media server application to be managed via API.
Note these products have evolved quite a bit over the years with more API interfaces for developers. For those looking for nostalgia, check out this WebRTC Gateway post from Lorenzo Miniero of Meetecho / Janus or my interview with Emil Ivov about Jitsi for a snapshot of the state-of-the-art at the time.
At the time, these were very much Linux applications you installed. As Iñaki will explain, mediasoup took a different approach.
Iñaki: In the case of Janus, it was of course much better, but still I felt like, “I have to run a Janus server somewhere, and then my application has to communicate with Janus by means of different protocol, like WebSocket, or HTTP, or some others that are provided.” But it was like, “Why do I need all this overkill just to write an application that can handle media for many participants? Do I really need to run a separate standalone server or control the media place as if it was a completely separate application?”
So, this motivated me to start thinking about something different, and this is how mediasoup came into my mind. I was learning node.js in those years. And of course, node.js was like, “Okay. This is going to be huge for years. So, this looks like a good way to go.” Before that, I was used to the Ruby language, but that ecosystem for building server-side applications was too constrained to web servers. node.js was clear to be the future for these kinds of things.
I said, “Okay. What if I create something that behaves like a library?” For instance, imagine that you want to create a chat application that can connect many people in a room, but just for testing, for string messaging, you create another application. You install some third-party libraries, like maybe WebSocket servers for having real time videos and external communication.
You write your logic within node.js and that’s everything you need. That’s possible. So, I want something similar for also having audio and video. Why not? Why do I need to run a separate, standalone server and make my application communicate with it? Or why should I use a media server forces its own single protocol?
I already have a single protocol for my users. They already can send and receive messages in real time. Why do I need to have a separate channel with a different maybe authentication just for the media part of the application I want to build? So, I said, “Okay. No signaling, I am just going to focus on the media transmission.” Signaling can be done by anyone. The same way they are creating a chat application, they can use such a channel to transmit other kinds of messages.
So, that’s how it was designed at the beginning. In the beginning, I didn’t know C++, so I started by learning C++. I started creating the RTP packetizer and RTP parser. Okay, it worked. I chose libuv, which is the library used in node that we were super comfortable working with. Super reliable, super simple, super reliable thing, and very clear API. Not super easy but clear.
How is mediasoup different?
So mediasoup started out designed to be a node.js library without call signaling, much like how WebRTC started out as a JavaScript library without signaling. This approach – and the use of node- has some interesting implications, like the fact it only uses a single thread.
Multi-process model
Iñaki: You know that mediasoup is not multi-threaded, it’s multi-process. You can launch different workers, but each worker just use a single thread in the system. Of course, this is good for some things and it’s not that good for others, but in the end it is super comfortable to work this way. You know that nothing is going to happen in the order that you don’t expect. Everything happens sequentially. And you know exactly, this is going to happen after this block. So, you never get into any race conditions, you don’t need to block any thread or things like that. I started learning both and eventually, I talked to Jose, I am doing this, and he said, “Oh, this is good.”
Chad: Can you talk a little bit more about the advantages and disadvantages of multi-process model?
Iñaki: For me, it’s all about benefits. I mean I think the API that we expose is simple, but of course it needs some knowledge, but we write documentation for that. The problem is that there are people that don’t read documentation; they want to rely on just examples. I don’t really see any drawback with the design. I have never seen it honestly.

The single-thread approach has many other implications for scaling. We will dig into this in more detail later, but first, we will cover some of mediasoup’s other differentiators.
Runs as a library
Chad: What else makes mediasoup different from other SFU projects?
Iñaki: the ability to run it as a library. I think this is the main difference. I mean in mediasoup you create your node.js or Rust application, you install many other libraries and you start mediasoup as if it was yet another library.
mediasoup was the first WebRTC server project I recall that actually felt like it was made for node.js and not something retrofitted with a node.js API.
Iñaki: Also the fact that we just tried to cover a very narrow scope. Nothing that can be done in [just] node is exposed in mediasoup. So, it’s up to the developer to create everything else. We want to be very low level.
Chad: Low level – like you don’t assume a lot of things about what the application would want to do, or how they’d want to do it?
Iñaki: Yeah. Exactly. For instance, in mediasoup there are no “peers” or “users”. That [construct] doesn’t exist. There are transports that are created on a router and there are producers and consumers that are created on top of transports, and that’s all. What those transports and producers and consumers mean inside your application is up to you. You can group them and say, “Okay, this is a user. This is an attendee, a participant.” Whatever. But we don’t expose the construct of users. And this is very good.
For instance, [in a recent implementation] we had an attendee model, but then we started designing the recording and someone said, “Okay. We need some kind of ghost attendee to record.”
[With mediasoup] we don’t need that. We don’t need to create any ghost attendee. It just creates transports and consumes the audio and video from all the participants.
Chad: So in that case, you just basically have a server-side app that goes and connects to those transports and basically writes the RTP to disk for recording?
Iñaki: Yeah. That’s how they’d write it.
There are 2 main ways to do server-side recording in multi-party calling scenarios:
- Have a view-only client join the call and have it record everything that is rendered to a virtual display or
- Send the stream to some device that dumps the packets to disk before they are converted to a standard format.
I have seen the first approach more often. Iñaki was talking about how mediasoup allows you to do either.
Dependency inclusion
Iñaki: In mediasoup we include all the C and C++ dependencies within the project itself. So, when you install mediasoup you know that you are going to run the specific versions of OpenSSL and libwebrtc. We know that we are going to run that version period. We don’t rely on any system level installed library. Some people say, “Okay, this is good. But it takes a bit more to install, because it has to compile everything.” Okay, it’s just a few minutes and we expose an options for you to keep your own binary in case just the node.js later changes. For me that’s enough, and the benefit is much higher than the drawback of having to wait a few minutes until everything is compiled.
I can talk about what others say that is a disadvantage. They say, “Okay, but I don’t want to create my application on node.” Or, “I don’t want to create my application on Rust. I just want to have mediasoup working as a standalone server, as if it was Janus,” for instance.
You can do that, but we are not going to do that. You can, if you want to run mediasoup in a standalone server – you can run it in node, or run it in Rust. Within the application that runs mediasoup, create an API server, or run also a WebSocket server. You could create of course all the methods and responses to communicate with mediasoup, and do whatever you want. But we are not going to do that.
This is something that I am not going to do, because it’s like, “Okay. If I do that, I am deciding how the communication between servers should be,” and I don’t want to do that. This is something that you can do, period. I just want to focus on the media transmission and the C++ thing, that is something that you shouldn’t have to deal with. Other than that, our node.js and Rust APIs are minimal, just to complete this task. Absolutely nothing else.
Peer Connection model
WebRTC provides a lot of flexibility. RTCPeerConnections can be unidirectional or bidirectional. There are also many options on how to handle streams from multiple users. We will talk later about the “Plan Wars” later, but I wanted to start with why they choose one-way peer connections vs. bidirectional ones.
Chad: Another question based on your model that you currently use two peer connections instead of one. Is there reason for that? What are the benefits and disadvantages?
Iñaki: Yeah. The reason is that it’s easier to… I said before that one of the more difficult challenges in mediasoup is especially in mediasoup client, when we have to deal with SDP, and it’s already complex to deal with one direction streams within a peer connection if we have to deal with bidirectional streams within the same peer connections, things are going to be terrible.
For example, imagine that we use a single peer connection for sending and receiving. Okay, maybe I want to send Opus code with some parameters. That’s okay. I do that and maybe later I want to consume an Opus stream that you are sending but with different parameters. If I try to consume that stream in the same PeerConnection, the PeerConnection itself is going to try to reduce the same SDP media section that I was using for sending, because there is the option to also receive on that media section, you know what I mean?
Media sessions are bidirectional by nature. But if that happens, the parameters must be the same or must be negotiated. I don’t want that. I want to send Opus with some parameters and at the same time be able to receive your Opus stream with a completely different set of parameters. I don’t want to negotiate the minimum that’s common to both or things like that. By using two peer connections, you avoid all these kind of problems. I have this peer connection for receiving – it’s a stream that I am going to receive. It’s going into a different media section [in the SDP]. So, I don’t have to deal with bidirectional communication or negotiation, things like that.
I don’t see any drawback using this [approach]. There are problems with bandwidth estimation, or anything like that, because you are receiving everything for one peer connection, but at the same time you can create as many RTP transports as you wish. We don’t constrain mediasoup to just one audio and one video transport.
Iñaki: I’m aware of other solutions that assume one audio stream and one video stream per “participant”. Later those solutions run into problems when it comes to enable webcam and screen sharing at the same time. You don’t have this problem in mediasoup.
We designed mediasoup without any of these constraints. In mediasoup – and we’re doing in Around – you can send three audios at the same time and three videos if you wish. So, we don’t assume anything related to, “Okay this is a user.” You can send whatever. We don’t have any kind of limit of limitation regarding that.
Iñaki is referring to how Jitsi Meet originally would only allow the user to send their video or the screen share. After that, they made a mechanism local canvas to composite the sender’s video on top of the screen share so you could see both the speaker and their screen share at the same time. Today Jitsi Meet sends separate streams but the mediasoup model allowed this to begin with.
And here is some proof that Iñaki is friends with Saúl of Jitsi:
Catching up IRL with the one and only @ibc_again 🍷 ❤️ pic.twitter.com/IVkUvJitdg
— Saúl Ibarra Corretgé (@saghul) December 23, 2021
Object RTC (ORTC) influence
We have covered the Session Description Protocol (SDP) that handles the media parameter negotiation in WebRTC quite a bit here at webrtcHacks. Most of these are complaints about how awful it is (including this one from Iñaki), but we also have a full SDP guide because it is unavoidable as you dig into getting more control over WebRTC. In the earlier days of WebRTC, when the standard was still in flux, Iñaki was a vocal advocate for a more JavaScript-oriented vs. the peculiar formatting of SDP. These anti-SDP efforts coalesced around an alternative spec called ORTC. That effort ultimately died, but it did end up influencing the WebRTC API – we’ll touch on that.
Chad: You started from more of a telco background with SIP, SDP is pretty big there. I know you ended up working with the ORTC – Object RTC. Those are kind of the anti-SDP people. How did you end up there and how did you work there influence the project?
Iñaki: I think it’s a good chance to talk about this ORTC influence in mediasoup. We know that ORTC has died, it’s no longer implemented in Microsoft Edge, because it adopted Chromium. But anyway, conceptually it’s still good. I think that the WebRTC spec is going to be moving in that direction, no matter if they’re still using SDP at the end.
There are efforts for being able just set some parameters via API to for sending a stream or receiving a stream. At the end they are going to end with SDP, but at least the API starting phase [SDP] is not exposed. [mediasoup] is more oriented to specific objects like the ORTC spec we designed. So, with mediasoup we did this from the very beginning. On the server side, everything is about ORTC spec. It’s very similar. When you want to send, for instance, some audio track in mediasoup you create a producer. And you pass the RTP parameters of the client – this is the codec, the payload, the payload types, the supported RTCP feedbacks, the supported RTCP header extensions and things like that. And before creating the producer, which is associated with a media stream, or media track, depending on which area we are talking about, we create the transport.
First, you need a transport and then you create the producer on that transport. You don’t create everything together by sending an SDP blob. The transport in the case of WebRTC is just about, “Okay. This is my ICE settings. I need your ICE candidates, your ICE username, fragment or password, whatever, blah blah.” And that’s all.
And we create that in a separate API just to establish the ICE connection with DTLS and all those things. That’s how we inherit the contents of ORTC. I am very proud of that. In fact, we also did that in the mediasoup client. If you happen to have taken a look at the mediasoup client, it’s the same syntax, or the same design. You don’t care about SDP, you create a producer by calling a method that is produced on a transport. You pass the specific parameters that you want and of course the track that you want to transmit. You don’t care about how that is translated into SDP stuff internally. We do that for you.
As we will cover later, mediasoup is not set up for easy-to-copy code snippets, but they do have a comprehensive demo here.
WebRTC Challenges
Chad: What are some of the bigger technical challenges that you overcame in putting this together?
Iñaki: On the technical plane – all the translations between SDP, different browser implementations, and different browser versions. For instance, React Native, they added support for Unified Plan, I think just last week. So, in this case in mediasoup-client we have logic for different browsers. We cover Chrome’s old version that uses Plan B, the new Chrome versions that use Unified Plan, and some Safari versions that do the same thing. We have handlers to deal with different implementations that support transceivers. So, we have to deal with all these difference between browsers, different devices and also versions of those devices or browser processes.
For background, Plan B and Unified plan are different formats for handling multiple tracks in SDP. We called them “The Plan Wars” since there were alternative proposed approaches. “Unified Plan” won, but it took Chrome a while to switch. See here for a post that covers that.
Iñaki: And that’s the most challenging effort because you have to test them. Okay, this version doesn’t support transceivers, but it fails when you try to get the MID number, or a stream because it’s not yet saved. This is an issue. I reported tons of issues in Safari when they released WebRTC with transceivers. It was completely a pain. All the translations between SDP and the ORTC API that we want to expose when we have to internally convert one to the other, that’s the most challenging part.
Chad: Would you say that’s gotten better? Have some of those cross-browser issues gotten easier, or better I guess as they’ve matured?
Iñaki: They have fixed most of them. For instance, all the issues that I reported in Safari as far as I remember, were fixed. Chrome’s Unified Plan implementation has evolved a lot in the last months, or years. It’s much better now without all those issues that it had in the past compared to Plan B.
So yes, I think that things are more stable now and it’s easier to extend the mediasoup client with new features. But we have not changed it for a long time. Maybe we should take a look – like Firefox has evolved, we don’t need to do this hack. We can use transceivers in a different way. Things like that. But we’ll iterate it when we get some time. So yes, things are much better.

Features & Roadmap
The mediasoup repo readme lists the following features as part of their v3:
|
1 2 3 4 5 6 7 8 9 |
* ECMAScript 6/Idiomatic Rust low level API. * Multi-stream: multiple audio/video streams over a single ICE + DTLS transport. * IPv6 ready. * ICE / DTLS / RTP / RTCP over UDP and TCP. * Simulcast and SVC support. * Congestion control. * Sender and receiver bandwidth estimation with spatial/temporal layers distribution algorithm. * Data message exchange (via WebRTC DataChannels, SCTP over plain UDP, and direct termination in Node.js/Rust). * Extremely powerful (media worker thread/subprocess coded in C++ on top of libuv). |
That’s a good start, but I wanted to understand what else the mediasoup team has been working on.
Google Meet-style Consumer Reuse
This first one is a significant one.
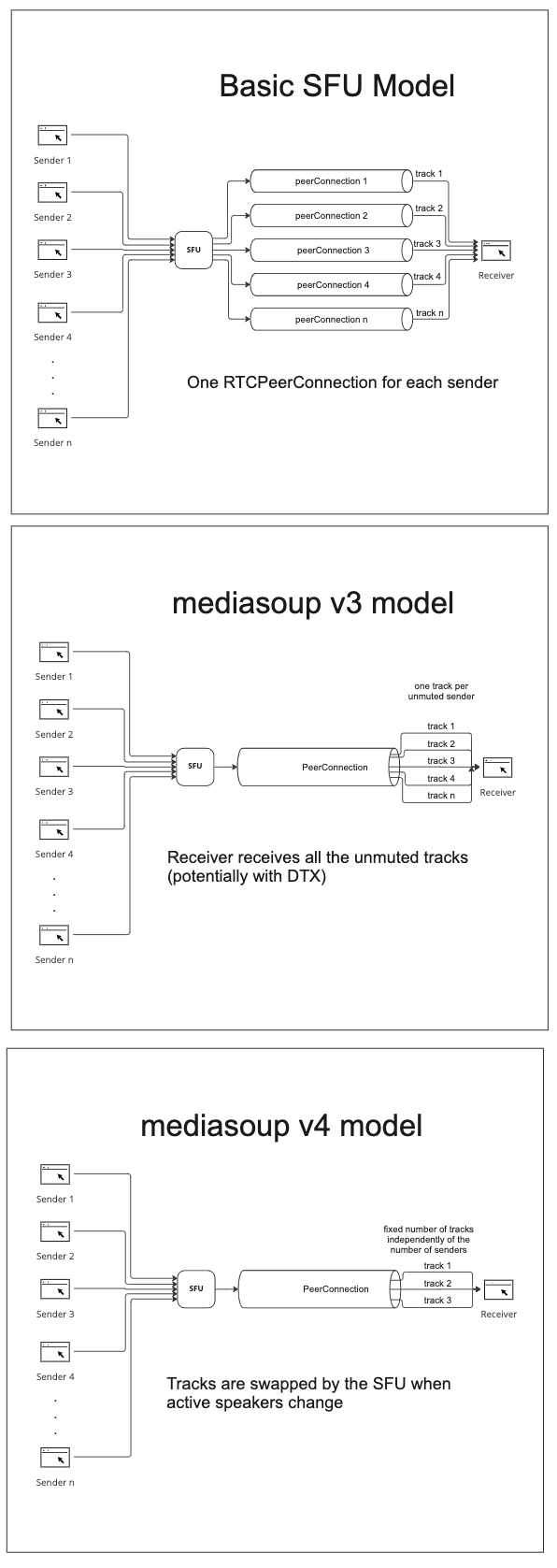
Iñaki: Yeah, there is one feature that is going to happen in version four, that is a super-breaking thing. Right now when you produce stream audio or video, especially if this is video, it can be a single stream, it can be Simulcast, it can be SVC. Then we create consumers associated with that producer. The consumer is what is going to send my video to you. You create a consumer to consume from my producer, but your consumer from the beginning is going to be okay, this is a simulcast consumer, so there is no chance for me to later switch what I am sending.
It’s like, okay, I started this way and I can’t change this. I can of course dynamically disable some streams that I am sending, or I can limit the max bandwidth dynamically from client’s side and increase it later. This is going to work. But one of the requests that we are having, especially from Gustavo by the way, is the ability to reuse a consumer for switching across different producers. This is something that Google Meet is doing. In Google Meet as far as I know, but I didn’t check in depth. It doesn’t matter that there are 100 attendees in a meeting. You just have five video or audio sections in the SDP, and instead of it switching which audio streams, it sends to you on those media sections, or streams.
If you are receiving the same SRTP stream with the same SSRC all the time, but it corresponds dynamically to different sources and on the server side you can switch that. The benefit of this is you just have five audio sections in the SDP instead of having 100, and you save bandwidth because the server decides which audio it’s going to send to you at any given time.
The problem is that this is like hard coding your application. For this to work, you need to have full control over the clients and say, “Okay. The client is just going to send this and all the clients are going to send the same kind of parameters in Opus, or whatever.” And this is not always true, especially if you are using different browsers. We are going to do that in a flexible way. So, I think that’s going to be huge. It’s going to enable scalability in a much easier way.
This is a complex topic, but I will attempt some brief background. When you have many participants in the same call, having your SFU send everyone’s streams to all participants doesn’t work. Depending on our UI, you may only be able to see so many people at once, so sending a stream that no one is going to see is just a waste of bandwidth. Even more important, humans can’t really understand when a bunch of people are talking at once and we prefer to only have one – or maybe a few – speakers at a time. The larger the call the more likely it is most of the participants will be silent at any one span of time. To improve comprehension but still allow rapid interactivity, advanced SFU-based services generally only send a limited set of audio tracks at a time for the active speakers.
There are a few approaches to doing this. Google Meet sets up a single peer connection with a static set of audio tracks and the server swaps out who sends those tracks transparently to the receiver. The clients don’t need to do anything other than have some extra signaling to indicate who is speaking on which track. The alternative is to do a bunch of renegotiations every time you change a stream or setup a bunch of different peer connections and mute them as needed. The clients need to do a lot more in these cases. It’s a trade-off between how much your server does and how much the client does. Soon mediasoup will let you choose between all the options.
Active speakers are usually determined by some sort of audio-level detection.
Iñaki: It’s not going to be perfect. It means that the server has to decide which audio streams to send you. How is the server is going to decide? There needs to be some audio level detector.
For instance, in my company, in Around, we do a very serious thing at audio level.
We know that that’s not a very good idea.If the server decides which audio to send you, it may happen that the first sound when you started speaking is going to be lost. We tried that solution and it’s like this is making the experience worse. But anyway, we should do that maybe for video it’s easier because in video it doesn’t matter if you lose some initial frames. So, probably that’s the best or the huge future that we are going to include. And there are also others that I don’t remember right now.Chad: It’s coming in version four.
Iñaki: Yes.
DataChannel updates
Chad: Do you have any other things on your roadmap for version four or beyond?
Iñaki: Yes, but they are not huge features. They are internal improvements related to data channels and things like that. In fact, we are going to remove something that we are doing at that data channel level. We cannot do magic. Imagine that I am sending over a reliable data channel, some super huge file to the server and you want to receive it.
Okay, yes, we establish that our data channel is reliable for sending and for you for receiving. But imagine that you don’t have enough downlink bandwidth to receive the file that I am sending at the speed that I am sending. It doesn’t matter that your data channel is reliable, the server is going to lose packets because otherwise, the server has to buffer all the packets that cannot send to you at the decided speed.
This is not something that a library can do because it means that the library could buffer tons of megabits, and that’s not the responsibility of the library. So we are going to do that in a different way and things like that.
The good thing about mediasoup, in my opinion, is that we don’t need to have many new features. It’s super low level, and as far as we allow people to transmit audio and video of course with simulcast, SVC, and all these kinds of things, that’s what this is about. There are no fancy features that can be implemented or exposed in my opinion.
RUST project
Rust is a rapidly growing language. It still accounts for a small percentage of WebRTC projects – <5% in August according to my latest Open Source WebRTC projects on GitHub Analysis (new post with more on programming languages coming soon). I noticed a RUST folder in the mediasoup repo and was curious if mediasoup was making a similar switch.
Chad: I see that you added Rust as a library. Can you tell me a little bit more about that, why you did that?
Iñaki: Yeah, I mean we didn’t. This was Nazar. Nazar is a new contributor, but he’s a core contributor. In fact, he has worked on mediasoup as much as Jose and me within the last two years. He was a Rust guy. He said, “Okay, I think I can create a Rust layer, the same way that mediasoup exposed our node library. The same for Rust language.” I don’t know Rust, I have no idea about Rust. The API is the same as we expose in node layer
Then there are some other differences like Rust is supposed to be multi-thread by design. So, he integrated our mediasoup worker, which is written in C++ in a different way. Instead of launching a separate process, it launches the worker within a Rust thread. But I cannot talk much more about that because it’s not my area of expertise. But other than this, Nazar is not just doing this. He has done, I mean huge things in mediasoup. He refactored the build system and now we use Meson. In the past we used GYP, which wasn’t updated for years, and we were running into many problems.
He has made a lot of optimizations in memory management, especially in the buffers that we use for retransmitting packets, and this has been huge. Before he did this, imagine that I send a video stream and his video stream is being consumed by 10 attendees. For every attendee, or for every sent transport in mediasoup we were having a buffer in which we keep all those packets in case any of the receivers request our transmission.
This means that the more attendees are receiving, the larger the total buffers are going to be. This was consuming a lot of memory. So, he came with a solution – we just keep a single packet in memory and still we are able to retransmit it to any attendee that wants to have it retransmitted. So, this is saving a huge amount of memory. The number is amazing. It’s completely amazing.
Daily covered why they chose Rust for their WebRTC implementation a bit at Kranky Geek last year – see that video for more on that:
Clients – web, native, and mobile
These days, WebRTC projects are expected to be supported everything – web and native on iOS and Android at a minimum. SDKs are expected to be available for all major languages. The mediasoup repo doesn’t mention much about native mobile or multi-language support. I asked Iñaki about this…
Chad: Jumping back to the clients, you have a JavaScript client that we talked about, you have a C++ one, and there’s aiortc – a Python-based client. Are there other ones?
Iñaki: We have mediasoup client – the TypeScript/JavaScript library – which can be used in process of course and people also use in React Native for building mobile applications. It can also be used within a node application. Not for sending out the audio and video unless you do something to be able to [handle media].
Then we also have libmediasoup, which is a C++ library that exposes a similar API, but internally it uses libWebRTC. This can be used for many things. I don’t know how people are using it, but there are lot of things that this can use. For instance, imagine that you run a libmediasoup client-based application on the server-side and I am transmitting a screen share using VP8. On the server-side you could run a libmediasoup client-based application that connects to the same router, consumes my screen sharing stream, and transcodes it to another codec. This is something that you can do using a peer connection. You can get a stream, a track, you get the track and you send it over your peer connection and you can set different encoding options. So, this means that I transmit my screen sharing using a specific codec, and on the server-side you can transcode it. For example, this could be helpful if you have some other client that just supports H.264. So it’s not just a library for creating client-side applications – it can also be used as a backend application.
Chad: Do you rely on the community for things like native mobile support? Do you know how some of your users typically handle native mobile clients?
Iñaki: So, that’s a very good question. Let’s talk about mobile. Right now the only official library that we support for mobile is mediasoup client in itself. But this of course just works in React Native, and maybe other frameworks that also run JavaScript code. There are also people using the libmediasoup client and creating Objective C, or Swift or whatever language that is used in iOS and Android, and also Java libraries. They are creating higher-level wrappers that expose an API in the native languages of the mobile devices.
We don’t want to do that basically because we are not good at that. I have almost no experience with mobile native development. Not just because it’s too much work, but also because it’s too applications specific. When you just use libWebRTC in mobile there are many assumptions that the library itself takes, such as the [media] input and output to use.
There is not much flexibility from what I have been told and from what I’ve seen in the past. I don’t want to expose a library that makes that many assumptions that cannot be changed unless you go to the internals and change things. With the mediasoup client, if you have enough skills, build your own library for building your Android or iOS application.
Performance and Scale
The late Dr. Alex Goualliard of Cosmo Software put together a benchmarking system and shared results comparing several open source SFU’s back in 2018 – Breaking Point: WebRTC SFU Load Testing. mediasoup was in this test group. At the time, mediasoup performed well. That was a few years ago. How has mediasoup improved? How does one scale it up to support more users?
How does mediasoup performance compare?
Chad: On the topic of performance, how does mediasoup perform? I know Cosmo Software a few years ago did some benchmarking. Have there been improvements since then? How do you think about core performance?
Iñaki: So, the only comparison that I have is that one that was done years ago. We have improved a lot recently related to the limitations that were exposed in that document, especially the memory usage, which is related to the buffers that they said before. We have also improved many other things related to JSON parsing that we were using internally to communicate between the node / Rust layer and the C++ worker, which were consuming a lot of CPU.
Jose is working on this monitoring. He’s checking where all the CPU, the parts of the code in the C++ worker that are consuming more CPU cycles, and we are doing a lot of improvements in that area. It’s becoming much more efficient than before. I think the only one that can compete with mediasoup in terms of performance is Janus. This was true in that comparison years ago.
Here is the mediasoup provided server-CPU vs. users chart from their repo.

Let’s get into how mediasoup supports large volumes.
Scaling mechanisms
Chad: You have a pipe-to-router feature. Is that for basically doing mediasoup to server-to-server type communications for that type of architecture?
Iñaki: Yeah. This is not just for server-to-server but also within the same physical server. In mediasoup we launch workers. Each worker is a separate C++ process that runs in a single CPU core. There is a limit. For very large meetings with tons of streams – inbound and outbound streams – [the number of streams per core] may be a limitation.
So, in this case, you need more workers. The way to do that is by interconnecting different workers that you are running in the same physical machine by means of this pipe to router feature, which means that you have a router running in a worker, which is running in a CPU [core], and you have another router running in another worker, which is running in another CPU, and you interconnect them and you say, “Okay, I want to transmit things from this router to this other router.”

PipeToTransport to cascade a single stream to viewers across multiple mediasoup routers. Source: https://github.com/versatica/mediasoupYou specify which producers you want to transmit. By doing this, you can have clients connecting to different routers and receiving the same producer that maybe is being injected in another router. You can extend this behavior also in different servers.
If you have a machine with eight cores and you can just book most of the resources for a super large meeting, or you may want to involve different machines. It is up to the application how they decide to scale.
We are doing this in Around right now – this is part of my work right now. [The ideal way to scale] depends on the nature of the application. [In one case, ]you may have regular meeting in which everybody is sending audio and video. That’s very different to other application like broadcasting, which there are just a few publishers and many thousands of watchers that are just receiving media. So, the topology is very different and there is not a single magic solution that covers both. So, depending on your application, the way you scale may be different.
I have to agree with Iñaki that there isn’t a universal right way to scale. The ideal parameters to optimize depend on the use case and use cases vary. Since it is low level, mediasoup does not prevent you from adjusting those parameters, but you need to have a good understanding to make those adjustments.
Community and Support
Unlike some open source WebRTC orgs, Iñaki and Jose do not invest a lot of effort into ease of development or even promoting mediasoup. Despite this, they have managed to build a solid following. GitHub lists 922 public dependents, 934 forks, and 4.8K stars for versatica/mediasoup.
We talked about some of mediasoup’s users outside of his employer, Around. Iñaki was not able to disclose the more interesting ones, but one included a major gaming company. You can get an idea of some of these companies by looking at their opencollective contributor list – that site is kind of like a Patreon for open-source development.
I asked him about his approach to community management and his target audience.
Iñaki: The thing is that since it’s very low level, the community that you get around mediasoup does not ask very high level questions. So, you get good developers that don’t need to ask easy questions in the forum. Maybe they contribute in a better way by reporting real issues and by creating real improvements via the PRs. And we have got tons of incredible PRs, and I am happy with this because our community is more about professional people that is not going to ask.”
Chad: I see that mediasoup developers know what they’re doing. Essentially, if you’re serious about the application and you want to go deep… Well, you have to go deep with mediasoup. So, you definitely get a more experienced developer community.
Iñaki: Yeah, exactly.
Chad: It doesn’t seem like you give a whole lot of emphasis to the community. Other groups have conferences, or they have dedicated people to go and do community management. You’ve managed to pull together a community, and you have a discourse for them and a lot of developers. What do you do though, I guess, to maintain the mediasoup community?
Iñaki: Before the pandemic, I used to go to conferences just to give some speeches. Now, this has stopped, of course, but I hope it will come back eventually. Regarding the community in that forum, I am really proud of how it’s going. At the beginning I participated a lot, but then it’s like there are users in that forum that contribute a lot.
In those kinds of forums, people typically ask questions, but they never reply to others. They never answer questions from others. In our case, we have maybe four, five, or six users that are super active, and they participate in the forum by answering questions for another. So, I have moved a bit away from the forum. I read the questions, but I let others participate.
Chad: That’s great.
Iñaki is referring to the Discourse forum they setup at https://mediasoup.discourse.group/
Iñaki: I don’t want to [answer basic questions], and I don’t have time, honestly, especially nowadays. So for very easy questions, I prefer others to respond to these. If there is something interesting that may trigger a nice discussion, or even a future request or some report or whatever, then I get involved. So, I am happy. There are people with good knowledge about mediasoup in the forum. There are of course people from time to time asking, “I need an example code to build a super huge application,” whatever. I just ignore it, and that’s all. It’s a small community. I think that there is more people behind than those that write unanswered questions. But I think that every one that is using mediasoup is in that forum.
Commercial Support
Some of the major open-source WebRTC projects are run by development teams you can hire for support, implementation, or custom feature development. Versatica is not one of those.
Chad: You don’t do consulting, you don’t do custom development, but do you take on sponsors at all?
Iñaki: We have. What I mean, in the past we’re thinking about having a company, like Janus for instance, not creating custom development, but consultancy services or whatever. But in the end we ended working in a company and we are fine. So, that’s [commercial services] probably not going to happen for now.
Chad: Well, I see you have an open collective thing.
Iñaki: Yeah. A few months ago there was a contributor that I have no idea who it is or name of the company. He contribute with 5,000 euros or dollars. I don’t know why. I don’t even know who it was. But it’s like, thank you. We also receive some private donations. Not much, but we do. This motivates us. This is good. It’s not that we need the money, but of course we celebrate this.
Chad: Yeah. It’s good to have some recognition.
Iñaki: Eventually we may use this money for attending some events. It’s not something that we need, but we are super happy to have this contribution. It means a lot for us and motivates us to keeping working.
Chad: Oh, that’s great.
Iñaki: We don’t do it as a response to like, “Okay, I will fix this issue if you pay me.” That has never happened.
Chad: I see on your discourse forum, you have a paid support area where users can ask for third party consultants for help.
Iñaki: Yes, yes. There is no lot of traffic there, but there is traffic. There are people who always answer and probably, they will have later private conversations. It’s okay. I know that there are companies that give consultancy support on mediasoup.
There is one on the forum, I don’t remember the name, but there is one at least doing that. I am perfectly fine [with that], since it’s not my business. It’s super nice to see that there are professional people working on that – doing that part that is missing because we don’t have a company around mediasoup that provides outsourced contributions.
Reference Materials
Do you fit the profile of a mediasoup developer? If so, I asked Iñaki about where you should get started.
Chad: So, you have your website, you get some documentation, obviously the repo, when you have the Discourse forum. Do you have one spot where you recommend somebody who may be interested in mediasoup starting a new project where they should get started?
Iñaki: Yeah, that’s a good question. I probably don’t have the best answer for that. I would recommend people read the website – everything that is written. It’s very good. We have some guidelines on the website such as how to communicate client to server, and the steps that you must do that should help the user understanding the API that they must use in client and server side. There are some examples.
There is the mediasoup demo, which is, it works but is not application-level code, but it works. The kind of user that I expect is people that can read those guidelines, get a general overview of what can be done with this, and then immediately they go to the API section, and they start reading the API, and they know what they have to build and they know what to look for. That’s the user that I would like to have as mediasoup users. Not those that don’t care about the API, just run the mediasoup demo, and now make it work for 400 users.”
Chad: That’s not your target user, the developer.
Iñaki: We don’t make it easy on purpose. I don’t like to say this, but the entry point is not easy on purpose. I’m sorry. I cannot help people looking for a very easy entry point where you take some code and just change something [small] depending on your setup and you are done. I cannot do that.
Their website is mediasoup.org and the repo is github.com/versatica/mediasoup.
As mentioned throughout the interview, mediasoup is not for the casual WebRTC developer. If you are new to WebRTC, mediasoup is not the SFU for you. However, its feature set and clean implementation made it a good fit for more experienced developers.
{
“Q&A”:{
“interviewer”:“chad hart“,
“interviewee”:“Iñaki Baz Castillo“
}
}





Does using multiple PeerConnections to the same client mean there’s greater risk that the audio and video will be out-of-sync due to arriving at different ports and possibly taking different Internet pathways?