
Pion seemingly came out of nowhere to become one of the biggest and most active WebRTC communities. Pion is a Go-based set of WebRTC projects. Golang is an interesting language, but it is not among the most popular programming languages out there, so what is so special about Pion? Why are there so many developers […]
Search Results for: medooze
WebRTC Today & Tomorrow: Interview with W3C WebRTC Chair Bernard Aboba

Interview with WebRTC standards co-chair and author, Bernard Aboba. We cover the current status of WebRTC and where it is headed including WebRTC-NV, Simulcast, SVC, AV1, WebTransport, WebCodecs, ML and more.
Breaking Point: WebRTC SFU Load Testing (Alex Gouaillard)
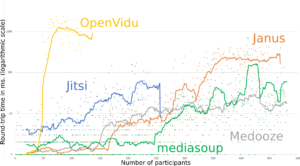
If you plan to have multiple participants in your WebRTC calls then you will probably end up using a Selective Forwarding Unit (SFU). Capacity planning for SFU’s can be difficult – there are estimates to be made for where they should be placed, how much bandwidth they will consume, and what kind of servers you […]
Chrome’s WebRTC VP9 SVC Layer Cake: Sergio Garcia Murillo & Gustavo Garcia

Multi-party calling architectures are a common topic here at webrtcHacks, largely because group calling is widely needed but difficult to implement and understand. Most would agree Scalable Video Coding (SVC) is the most advanced, but the most complex multi-party calling architecture. To help explain how it works we have brought in not one, but two WebRTC video architecture experts. […]