Serverless is a technology that has been around for a while and was popularized by Amazon Web Services’ (AWS) Lambda functions. Serverless does have servers, but as a developer you don’t need to think about that – you just push / paste your code and deploy and the serverless infrastructure takes care of all the other aspects needed to deploy that code. While WebRTC’s peer connections are peer-to-peer, a server is needed to facilitate WebRTC’s offer answer mechanism. Can serverless be used to solve WebRTC’s signaling server problem?
The answer is – yes. Edward Burton, CTO of start-up yown.it, shows all the details how below. yown.it is an ecommerce platform that uses WebRTC to let businesses interact with their customers live over audio and video. Like many sites, they need some kind of server-side infrastructure for handling more than WebRTC signaling. And like many businesses of all sizes, they wanted to leverage modern, cloud-oriented architectures as much as possible.
In this post, Edward shows how they leveraged a serverless architecture to setup their WebRTC signaling. They used AWS’s API Gateway WebSocket API to terminate WebSockets and invoke AWS serverless Lambda functions. While there is no universal or best way to handle signaling for WebRTC, this is a great example of one way to do it.
{“editor”, “chad hart“}

AWS WebSocket API
The AWS WebSocket API is your secret weapon in deploying production ready enterprise calibre WebRTC features. It enables an event driven, serverless infrastructure that makes discovery, negotiation and connections almost flawless and can handle real-time communications infrastructure at scale.
Many of us are used to implementing our own WebSockets using libraries such as Socket.IO or the native browser WebSocket API. Using WebSockets for negotiation is an important part of the puzzle, however the AWS WebSocket API gives us so much more. In their own words:
A client can send messages to a service, and services can independently send messages to clients. This bidirectional behavior enables richer client/service interactions because services can push data to clients without requiring clients to make an explicit request.
The elephant in the corner in most WebRTC documentation is that most examples focus on perfect negotiation between two blank HTML pages. This vanilla peer-to-peer (p2p) architecture is an inspiration behind many WebRTC use-cases, but executing it in a production environment requires more complex infrastructure that is rarely addressed.
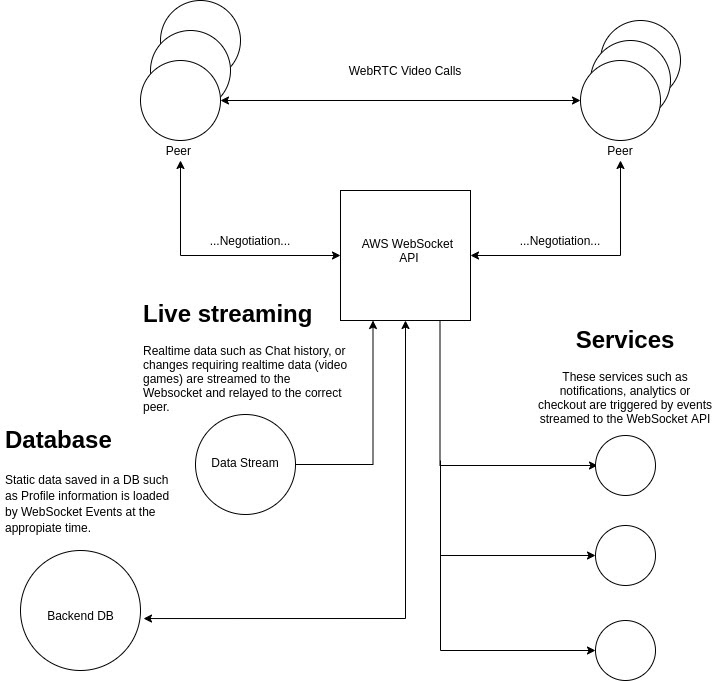
WebRTC in production is more complex than connecting blank HTML pages
In the real world, feature rich applications have a complex flow that will involve synchronizing metadata and accessing services, often in real time. Many promising WebRTC projects fail due to the complexity surrounding integration of WebRTC within a feature-rich production environment.
Let us imagine that we are working on a video-game with overlaid communications, a fairly common usage for both the WebSocket API and WebRTC. We have a requirement for peers to connect with each other with WebRTC streams, but at the same time they must also be subscribed to real-time services and have access to an API. Coordinating state and communication betweens these peers requires far more than a simple “signalling” system.
First of all we need to manage a scalable enterprise level global server infrastructure (with added elastic scaling, routing & load balancers). Then, we need to organize our actual WebSockets into an appropriate structure so we can handle routing and people are connected to the “right” peer, as well as simultaneously subscribing to our backend services. There are technical issues to overcome everywhere.
The overhead of managing these servers in the backend and enabling a stable environment for WebRTC connections is complex and expensive; which is counter-intuitive for a technology such as WebRTC which at its heart is about simple and “perfect” web based media streaming. What we require is a scalable system that can preferably be broken down into a modular architecture. The answer to this particular problem is to use a serverless paradigm.
When we use a serverless infrastructure we can rely on AWS to run our network of highly available and scalable servers on the backend, and we simply hook into this network to execute events. If you are unclear about the benefits and details of serveless we recommend you dive in here: https://aws.amazon.com/serverless/
We champion the use of a serverless, event driven architecture with AWS WebSocket API at its core.
The WebSocket API is one of the clearest use cases of serverless technology I can think of and it all comes down to one little word in their own description. Read it again, more carefully:
A client can send messages to a service.
It is a small distinction, but I bet that when you thought of WebSockets you thought much like you thought of WebRTC itself – a peer to peer mesh infrastructure for sending messages backwards and forwards between two peers.
That is largely accurate, but with AWS WebSocket API, we no longer send messages directly from one peer to another or even from one peer to many, but rather, from one peer to our system. Our serverless backend then takes this message and converts it into an event to be handled. This doesn’t simply “route” it to the end peer, but executes business logic.
This is the essence of achieving WebRTC perfection within a feature rich application, Peer to Peer communication via our system.
So we have a component at the heart of our architecture that can relay real-time data, orchestrate services and access backend APIs, all with a unified event-driven logic that ensures that all peers are accessing the most accurate version of the data at the correct point.
WebRTC discovery
Let’s think about this in terms that we can all understand – Google’s official WebRTC reference app: https://appr.tc/
This is an example WebRTC application of the sort that gets everyone excited.
It is super-lightweight with perfect negotiation and works just by hitting a URL. WebRTC is easy right…
We all started from this assumption, where a simple P2P connection between TWO peers with a simple negotiation triggered on joining can be the foundation of a feature-rich application.
This application only accepts 1 connection, so basically Peer 1 publishes an offer and Peer 2 joins the room (a WebSocket address) and creates an answer.
WebRTC is fundamentally about connecting two peers. But what is rarely talked about are the complexities involved in multiparty negotiation, especially between eager and dormant parties within an application where parties may or may not conditionally join a video call. Why aren’t there more examples of managing multiple negotiations concurrently between a larger number of peers?
The reason for this is simple – managing an event based wrapper around WebRTC discovery and negotiation is hard, complex, and often system specific. This is why we have so enthusiastically embraced the WebSocket API which solves many of these issues.
The above example in appr.tc is limited to two peers. It is stable precisely because it is simple.
Most apps aren’t like appr.tc
But if we think about the information that we would need to make an API that would reliably allow more users to discover, join and leave this connection then we need to have the following:
- How many people are actively looking for connections.
- How many users are allowed to connect.
- Information about “who” these people are, profile metadata
- Some data about previous connections such as chat history
- Some kind of analytics so that system administrators could have insight into their system and monitor performance
Things just got a bit more complex right…
Most WebRTC examples are implemented exclusively on the front-end which means:
- That chat that works so well… disappears when you close the browser
- That profile you created… disappears on page refresh
- That video conversation you had… no-one knows it has ever happened
Generally speaking, managing the synchronization of state between peers is seen as a “non-WebRTC” problem. However, without addressing this issue it is very hard to implement in a production environment.
Initial Connection/Registration Example
This is the message sent through the websocket when you join a room in appr.tc:
|
1 2 3 4 5 |
{ clientid: "00052939" cmd: "register" roomid: "557126025" } |
The important part of this message is the cmd: "register".
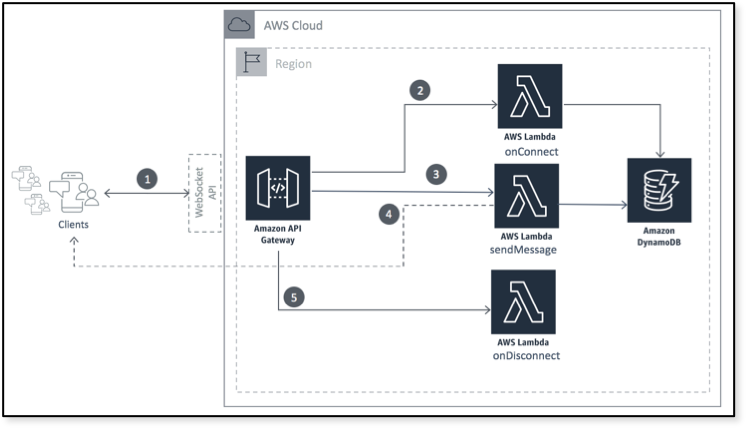
AWS WebSocket API works using the same principals by hooking into these commands and converting them into “events” that can execute business logic. I highly recommend browsing the source code of their example application in this simple-websockets-chat-app example repo.:
What you will notice is that when we join a WebSocket, we trigger a Lambda function (the serverless functions executed in the AWS backend) onConnect.
In our WebSocket architecture, the onConnect event will send a message to other connected peers with a clientId and roomId much like the above example.
This Lambda function also gives us the opportunity to manage application specific logic within the same event.
So, here is what is happening in an example onConnect Lambda from our application:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
const AWS = require("aws-sdk"); const ddb = new AWS.DynamoDB.DocumentClient({ apiVersion: "2012-08-10", region: process.env.AWS_REGION, }); const TableName = process.env.TABLE_NAME; exports.handler = async (event) => { let connectionData; try { const { storeId, conversationId, userId, type, deviceId, connectionType } = event.queryStringParameters; const staleConnectionLookup = { FilterExpression: "deviceId = :deviceId", ExpressionAttributeValues: { ":deviceId": deviceId, }, ProjectionExpression: "connectionId", TableName, }; connectionData = await ddb.scan(staleConnectionLookup).promise(); await Promise.all( connectionData.Items.map((connection) => { const deleteStaleConnections = { TableName, Key: { connectionId: connection.connectionId, storeId: storeId, }, }; return ddb.delete(deleteStaleConnections).promise(); }) ); const putParams = { TableName, Item: { connectionId: event.requestContext.connectionId, storeId, conversationId, userId, type, deviceId, connectionType, createdAt: Date.now(), }, }; try { await ddb.put(putParams).promise(); } catch (e) { console.log(e); } } catch (err) { return { statusCode: 500, body: "Failed to connect: " + JSON.stringify(err), }; } return { statusCode: 200, body: "Connected." }; }; |
Enriching anonymous WebRTC connections
The above code sample works off the same “register” message that all WebSockets will use as part of a WebRTC connection. As well as providing data “User A has joined the WebSocket”, we are enriching this event with data from our systems.
We can associate the user with metadata from their profile saved in our backend (names and a photo perhaps) and we can also hook into events that make it clear whether they are interested in creating new connections, or loading chat history from previous connections.
These little details are extremely important in production systems, and managing them through the real-time data flow of WebRTC without having an event wrapper can get convoluted quickly.
Now that we have a Lambda function executing on our onConnect event, we have our WebSockets fully integrated and we now have a lightweight backend that can tell us “who” is online. And the important thing is that this code is run at the point of joining the WebSocket, so we have the perfect event wrapper to retrieve the data exactly when it is required in it’s latest state.
Being online and willing to negotiate a WebRTC connection are similar but entirely different states. We cannot make the assumption made in most WebRTC demos that all available peers should automatically engage in a video / audio call. (Fun fact: In our early days we handled negotiation like this and it had some very interesting reactions from our product team!)
This is where the distinction between our application state and WebRTC signalling becomes so important. We know that profileX is connected to our system via the WebSocket.
We do not yet know that profileX wants to engage in WebRTC negotiation or join a video call. This WebSocket is a subscription to our services, of which WebRTC is an important but individually handled one.
Initiating a connection
Now we imagine that profileX does want to initiate a video call (probably because they have indicated this by taking an action on our front-end). Luckily every WebSocket connect and disconnect callback has synced with our database via their associated Lambdas. We know the exact state of all users in our system.
At the point of WebRTC initiation all we have to do is a quick HTTP request on the frontend to retrieve a synced version of all discoverable peers. WebSocket API associates Lambdas to WebSocket callbacks. Our data can also be accessed externally by HTTP endpoints to get a list of available peers. An example Lambda from our gateway endpoint looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
const AWS = require("aws-sdk"); const ddb = new AWS.DynamoDB.DocumentClient({ apiVersion: "2012-08-10", region: process.env.AWS_REGION, }); const TableName = process.env.TABLE_NAME; exports.handler = async (event) => { const {conversationId, storeId} = JSON.parse(event.body); try { const params = { FilterExpression: ExpressionAttributeValues: { ":conversationId": conversationId, ":storeId": storeId, }, ProjectionExpression: "connectionId", TableName, }; const connectionData = await ddb.scan(params).promise(); return { statusCode: 200, body: connectionData }; } catch (e) { return { statusCode: 500, body: e.stack }; } } |
On the client side we can now access a list of online peers with a HTTP call from outside of the WebSocket as a perfect discovery system.
The returned connectionIds can then be used to route our WebSocket negotiation messages within the system. So in our frontend application we open a component “Call friends”. This then returns a list of connections currently available within the application. Then we can trigger the negotiation process by sending WebSocket messages only to the peers that we have selected.
This is a great way for managing the view of our system using a wrapper around WebSocket events.
Perfect Negotiation
Our system is now organized so that we are able to find and connect with the appropriate peers, all with enriched data from our backend databases and services. We now need to handle the offer / answer / IceCandidate flow, the art of “Perfect Negotiation”.
Perfect negotiation is the principle of using the same code logic on the front-end to ensure an error-free browser to browser connection experience. This is a tougher task than it initially seems. We have to remember that every device and browser is essentially a unique execution environment, so there are many many idiosyncrasies to overcome.
For more background on perfect Negotiation, webrtcHacks previously gave a brief intro to Perfect Negotiation here and you can see the Mozilla post about this here. This was later incorporated into the official WebRTC spec, which you can see here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
const signaling = new SignalingChannel(); // handles JSON.stringify/parse const constraints = {audio: true, video: true}; const configuration = {iceServers: [{urls: 'stun:stun.example.org'}]}; const pc = new RTCPeerConnection(configuration); // call start() anytime on either end to add camera and microphone to connection async function start() { try { const stream = await navigator.mediaDevices.getUserMedia(constraints); for (const track of stream.getTracks()) { pc.addTrack(track, stream); } selfView.srcObject = stream; } catch (err) { console.error(err); } } pc.ontrack = ({track, streams}) => { // once media for a remote track arrives, show it in the remote video element track.onunmute = () => { // don't set srcObject again if it is already set. if (remoteView.srcObject) return; remoteView.srcObject = streams[0]; }; }; // - The perfect negotiation logic, separated from the rest of the application --- // keep track of some negotiation state to prevent races and errors let makingOffer = false; let ignoreOffer = false; let isSettingRemoteAnswerPending = false; // send any ice candidates to the other peer pc.onicecandidate = ({candidate}) => signaling.send({candidate}); // let the "negotiationneeded" event trigger offer generation pc.onnegotiationneeded = async () => { try { makingOffer = true; await pc.setLocalDescription(); signaling.send({description: pc.localDescription}); } catch (err) { console.error(err); } finally { makingOffer = false; } }; signaling.onmessage = async ({data: {description, candidate}}) => { try { if (description) { // An offer may come in while we are busy processing SRD(answer). // In this case, we will be in "stable" by the time the offer is processed // so it is safe to chain it on our Operations Chain now. const readyForOffer = !makingOffer && (pc.signalingState == "stable" || isSettingRemoteAnswerPending); const offerCollision = description.type == "offer" && !readyForOffer; ignoreOffer = !polite && offerCollision; if (ignoreOffer) { return; } isSettingRemoteAnswerPending = description.type == "answer"; await pc.setRemoteDescription(description); // SRD rolls back as needed isSettingRemoteAnswerPending = false; if (description.type == "offer") { await pc.setLocalDescription(); signaling.send({description: pc.localDescription}); } } else if (candidate) { try { await pc.addIceCandidate(candidate); } catch (err) { if (!ignoreOffer) throw err; // Suppress ignored offer's candidates } } } catch (err) { console.error(err); } } |
We’ve included some quite mature examples of this implemented in React Typescript in this repo.
The negotiation is all handled on the frontend, triggered by a “negotiate” action in the WebSocket. Many of us will be familiar with this process which are essentially the bidirectional peer to peer messages (sent to and from one specific address, not broadcast to groups) which are the foundation of any WebRTC negotiation.
The process is as follows:
- User A connects to the WebsSocket, publishing their unique
conversationIdandconnectionIdto a database (this is published via the$OnConnectaction provided out of the box by AWS WebSocket API). - User B is invited to the frontend with a url containing the
conversationId. The$OnConnectaction now publishes User B’s ConnectionId and also returns a scan of all active users filtered by conversationId from the url parameters. This scan discovers User A’s data enriched with application metadata. - User B is now aware that User A is awaiting connections, so sends an offer (as
MASTER) through the websocket directly to User A’s connectionId. This is now inline with a vanilla flow. - User A receives this offer through the WebSocket.
- Users A & B are now aware of each other’s
connectionIdwhich can be used as the key for aNEGOTIATEaction. - The
NEGOTIATEaction is a P2P message handler between only two peers (no broadcasting), where the offer/answer and ICE candidates are streamed directly through the websockets and handled with code on the frontend (React).
Serverless downsides
It should be clear that we are big fans of the serverless architecture based on the work of AWS with their WebSocket API.
It is worth remembering a few unsaid truths before everyone goes running to rebuild their infrastructure!
“There is no such thing as the ‘cloud’, only someone else’s computer”.
In this case, a very sophisticated system run by a global company. You do however of course sacrifice elements of control for convenience. Sometimes (very rarely) things may go wrong, and you probably will never be able to find out why. For example our commerce Webhooks have a success rate of 99.85%… We think that is pretty good, but looking for that 0.15% can be an unforgiving task…
When a system isn’t used frequently for example, Lambdas can be put into cold storage (to save costs on having them highly available). Cold starts can cause a small lag at any point. This is not ideal for providing a real time experience WebRTC needs.
Costs for us have been great, but as you scale there is obviously a margin built-in. Running on AWS at scale is never a charity – you’ll have to keep a close eye on the type of hardware you are using and applying it to the needs of your system.
Conclusion
On the whole though, WebRTC in a feature rich application presents many problems. We can solve many of these problems by wrapping the negotiation in an architecture that allows one to gracefully join, announce, disconnect and interact with both our peers, and importantly with our services as a whole.
Amazon WebSocket API provides more than a serverless integrated callback for your WebSocket messages, it enables a centralized handling of the state and logic surrounding client features. It presents an excellent architecture for solving issues around discovery, state and negotiation.
So if you want more than 2 peers, within an application with rich discovery, negotiation and other features, we highly recommend you have a look at AWS WebSocket API.
{“author”: ”Edward Burton”}




Good insights man! 😀
We are currently working on a refactor of our signalling flows, but instead of AWS Websocket API and serverless, we are planning to use NATS.io as a WebSocket server, to create a more reliable real-time cluster and also to have easier integrations with our backend micro-services.
And after reading your post, I found this project:
https://pionion.github.io/
They are doing something pretty similar to what I was thinking. So thank you!