There is a cool new feature everyone has been trying to implement – background transparency. Virtual backgrounds have been around for a while. Rather than inserting a new background behind user(s), transparency removes the background altogether, allowing the app to place users over a screen share or together in a shared environment. There doesn’t seem to be a universal name for this feature. Zoom calls it Immersive View. Microsoft calls it Together Mode. RingCentral calls them overlays. Virtual green screens or newscaster mode are other names.
I decided to figure out how to do this in the browser. I wanted to not only show the user’s self-view as transparent but also have the user’s background removed for anyone they send their image to over a WebRTC peer connection. WebRTC does make this as easy as it could be, but fortunately new APIs like WebRTC Insertable Streams / Breakout box help to make this a lot more performant. I walk through methods and findings below or jump here to see the demos.
Proof of Concept
I started out with some proof of concept code and ended up expanding that into a more comprehensive playground as I experimented with different things. You can see that repo at https://github.com/webrtcHacks/transparent-virtual-background
Play with the playground yourself at playground.html (note there is a streamlined example covered further down too).
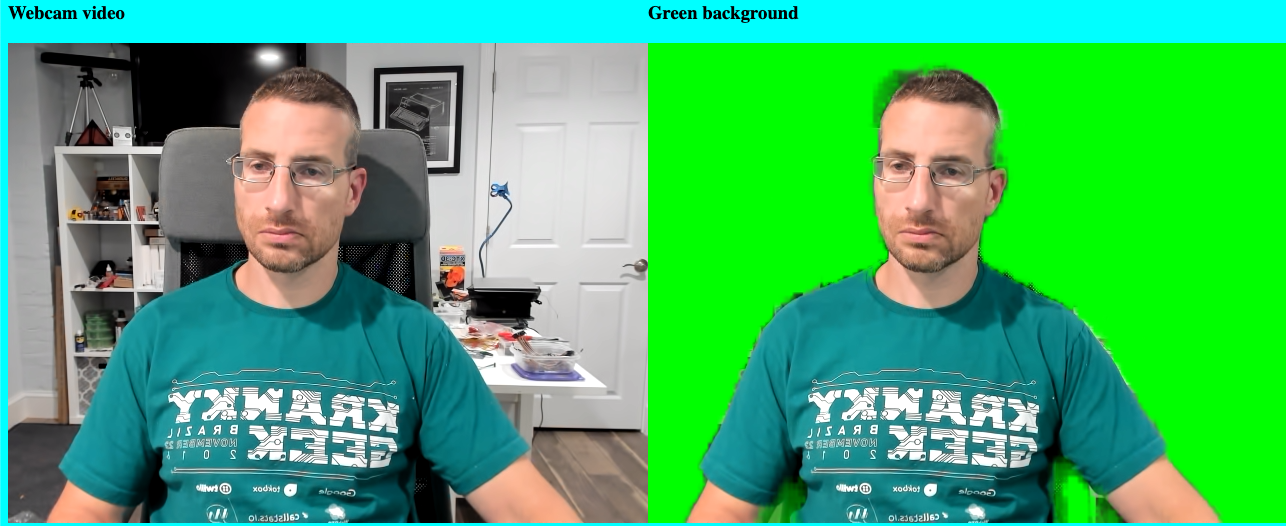
In my examples below I intentionally made my environment a bit difficult – I turned off my forward-facing lighting, used my usual high-back chair, and wore my green Kranky Geek t-shirt to confuse any poorly tuned green screen effects. (Speaking of Kranky Geek, make sure you sign up for our next live stream broadcast on November 18 here).
Segmenting the Background
One of the first things you need to do is segment the user from the background. To do this, you can either ask your users to set up a physical green screen or use a Machine Learning library to do this. Fortunately, the ML mechanisms are relatively easy. I showed how to use the tensorflow.js BodyPix library at the beginning of the pandemic in Stop touching your face using a browser and TensorFlow.js. That example uses individual body segmentation but you can also use it to segment the user from the background and it even has a built-in Bokeh effect option (i.e. blurred background). MediaPipe builds on TensorFlow and is faster. Fippo showed MediaPipe’s use in Making Zoom’s Smart Gallery on the Web with MediaPipe and BreakoutBox.
MediaPipe includes a Selfie Segmentation library, so I used that. There isn’t much to it:
|
1 2 3 4 5 6 7 8 9 |
const selfieSegmentation = new SelfieSegmentation({locateFile: (file) => { return `https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/${file}`; }}); selfieSegmentation.setOptions({ modelSelection: 1, }); selfieSegmentation.onResults(greenScreen); // handle the results selfieSegmentation.send({image: videoElement}); |
Now we just need to take the results and remove the background.
Transparent Backgrounds
The selfieSegmentation model returns a mask of just the user with the other pixels transparent (I made my page background cyan to make this more obvious):

We can use some HTML canvas tricks to add a green background here. There are a bunch of powerful canvas image compositing operations that make this simple (read the MDN article about them here). source-in draws new pixels anywhere there isn’t already a pixel. Let’s do that to just show the user in the foreground:
|
1 2 3 4 5 6 7 8 9 |
const ctx = someCanvasElement.getContext(‘2d’) // setup a canvas context ctx.clearRect(0, 0, width, height); // clear the image first // Draw the mask ctx.drawImage(results.segmentationMask, 0, 0, width, height); // Add the original video back in (in image) , but only overwrite overlapping pixels. ctx.globalCompositeOperation = 'source-in'; // composition magic ctx.drawImage(results.image, 0, 0, width, height); |
That should give you an image that looks like this:

The segmentation could use some improvement in that particular frame, but that wasn’t too much work. Now let’s send that over an RTCPeerConnection
Sending transparency over a WebRTC Peer Connection (kind of works?)
See my code for the mechanics of how I set up and send this over a peer connection. I just take the incoming stream and add it to an <video> element. You’ll see it looks like this:

Notice it isn’t transparent? What happened? Well, the WebRTC encoder doesn’t process the alpha channel. Wherever it sees the RGBA: (0,0,0,255) it converts it to RGBA(0,154,0, 254). A, standing for alpha where 0 is fully transparent and 255 is fully opaque.
I tried this the next day and found the green background was a different color – RGBA(74,255,20, 254):

I am not sure why the values are different after or if shading the background green was by design (note: this looks a bit like issue 762443). In any case, it’s green – now we just need to make it transparent.
Adding transparency
WebRTC won’t send transparency (confirmation and thread on discuss-webrtc), but we add that back in. The simplest way I found to do that is just to draw the image to a canvas and run through it pixel-by-pixel and add the transparency anywhere there is green.
Draw to a canvas:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
const outputCtx = outputCanvas.getContext('2d'); const getImageData = () => { outputCtx.drawImage(source, 0, 0, width, height); const imageData = outputCtx.getImageData(0, 0, width, height); const transparentImageData = addAlpha(imageData); // add transparency outputCtx.putImageData(transparentImageData, 0, 0); // draw it requestAnimationFrame(getImageData); // do it again }; getImageData(); |
And my addAlpha function:
|
1 2 3 4 5 6 7 8 9 |
function addAlpha(imageData, gFloor=105, rbCeiling=80) { const {data} = imageData; for (let r = 0, g = 1, b = 2, a = 3; a < data.length; r += 4, g += 4, b += 4, a += 4) { if (data[r] <= rbCeiling && data[b] <= rbCeiling && data[g] >= gFloor) data[a] = 0; } return imageData } |
If you are used to dealing with multi-dimensional image arrays, the canvas getImageData is weird in that it is just a long string of raw bits without any object structure. It follows the pattern:
| R0 | B0 | G0 | A0 | R1 | B1 | G1 | A1 | R2 | B2 | G2 | A2 | … | Rn | Gn | Bn | An |
|---|
This function just moves through the data looking for where there is no red or blue and where green is larger than some floor value gFloor. Since sometimes the red r and blue b values are populated, we also need to set a ceiling value for these. Anywhere the conditions are true it simply sets the alpha to 0. While most pixels are RGB(0,154,0, 254), with some experimentation, I found setting gFloor to somewhere around 105 and rbCeiling to 80 gave the best general results to remove any artifacts from the segmentation and WebRTC encode/decode processes.

Enhancements
Adding a Virtual Green Screen to the Sender
I ran a quick test on my wife’s Macbook and got the following:

Green around the silhouette where there is some partial transparency and pure black everywhere else. WTF is happening in the encoder!?!
The peer connection encoder changing the stream alpha pixels to seemingly different values had me worried. (ToDo: check the WebRTC encoder code to see how this works). In general, the alpha channel images sent over the peer connected ended up with some green halo artifacts around the segmentation. In one of my initial prototypes, I added a green background to the source image and sent this over the peer connection. It seems like this method is more reliable.
That process is pretty easy using what we have covered so far:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function greenScreen(results, ctx) { ctx.clearRect(0, 0, width, height); // Draw the mask ctx.drawImage(results.segmentationMask, 0, 0, width, height); // Fill green on everything but the mask ctx.globalCompositeOperation = 'source-out'; ctx.fillStyle = '#00FF00'; ctx.fillRect(0, 0, width, height); // Add the original video back in (in image) , but only overwrite missing pixels. ctx.globalCompositeOperation = 'destination-atop'; ctx.drawImage(results.image, 0, 0, width, height); } |
Getting more sophisticated with WebGL
In researching how to do this, I came across a set of posts by James Fisher demoing how he ported the Open Broadcast Studio (OBS) green screen implementation (the physical variety) using WebGL – https://jameshfisher.com/2020/08/11/production-ready-green-screen-in-the-browser/. (He has an even cooler demo Step-away background removal that removes your background by comparing your webcam image with you in it against one where you “step away”).
WebGL is supposed to be fast. However, WebGL is not at all like working with the HTML canvas and looks like a beast to learn. Fortunately, James agreed to let me include his code in my sample! It was easy to copy/paste his functions without understanding how they work.
Unlike my crude green and red/blue thresholds, his WebGL implementation includes options for adjusting Similarity, Smoothness, and Spill. It’s subtle, but these gave a better segmentation from the green screen around the edges.

Tying it all together with Insertable Streams (aka Breakout Box)
My playground example is helpful for quickly comparing methods. A real application would need to be much more streamlined. WebRTC apps usually show some kind of self-view and would need to add transparency to any incoming streams shown. In addition, most WebRTC apps are designed around <video> elements, not canvases. Therefore, I wanted to use MediaStream inputs and outputs and not rely on visible canvas writes.
I also wanted to play with WebRTC Insertable Streams, as described here. WebRTC Insertable Streams let you transform and create MediaStreams using the W3C Streams API, or some of it at least. Fippo used this technique in his Making Zoom’s Smart Gallery on the Web with MediaPipe and BreakoutBox post too.
All-in-one example
So, I made a second, consolidated sample here: transparency.html. This one is fully contained in a single file. It only shows a single transparent <video> element for the sender and one for the receiver. Segmentation and transparency are converted to MediaStreams using Insertable Streams.
Making the sender pipeline
What I wanted to do on the sender side is something like this where I could tee the segmented stream into 2 streams for further processes:

Unfortunately, it doesn’t seem tee() works on MediaStreams yet. There is mention of this here and some good discussion on tee in this WebRTC Working Group doc – it seems tee may be coming but I couldn’t find an example that worked.
Even if tee worked, the way this is implemented isn’t really what I wanted either. Each stream you want to output needs a controller provided from a Generator:
|
1 2 3 4 5 6 7 8 9 10 |
let [track] = stream.getVideoTracks(); const segmentGenerator = new MediaStreamTrackGenerator({kind: 'video'}); const processor = new MediaStreamTrackProcessor({track}); const segmentStream = new MediaStream([segmentGenerator]); processor.readable.pipeThrough(new TransformStream({ transform: (frame, controller) => segment(frame, controller) })) .pipeTo(segmentGenerator.writable) .catch(err=>console.error("green screen generator error", err)); |
The runs the Frame through the segmentation. I take that image and write it to an OffscreenCanvas. Then I use the passed controller to enqueue the processed frame from that canvas where it is added to the segmentStream from the generator.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
async function segment(frame, controller) { // see the source for the full function code await selfieSegmentation.onResults(async results => { segmentCtx.clearRect(0, 0, width, height); segmentCtx.drawImage(results.segmentationMask, 0, 0, width, height); // Grab the transparent image // segmentCtx.save(); // Add the original video back in only overwriting the masked pixels segmentCtx.globalCompositeOperation = 'source-in'; segmentCtx.drawImage(results.image, 0, 0, width, height); const selfieFrame = new VideoFrame(segmentCanvas); controller.enqueue(selfieFrame); frame.close(); }); await selfieSegmentation.send({image: segmentCanvas}); } |
What I really wanted in my segment function is 2 controllers so I could perform my transparency and greenscreen operations in one go and enqueue both frames at the same time. I didn’t see an efficient way to do a transform stream that encodes 2 different streams (again see that WG Meeting). I could have made two separate pipelines – one for the self-view and one for the sender, but that would have duplicated the intensive segmentation process.
Receiver pipeline
I ended up with this process:

I had to add an addGreenScreen function with 40 lines of code including its ownMediaStreamTrackProcessor, TransformStream, and TransformStream. After the segmentation process, the stream encoding that takes place in the generator should be the next most expensive operation.
The receiver side is a very straightforward process with a single processor→transform→generator:

Performance
How well does it perform? There are 2 main performance dimensions I cared about:
- Visual segmentation – how well does it separate the user from the background? Are there many artifacts where the background shows through or where the segmentation cuts out part of the user?
- Processor usage – will usage of transparency suck up all the user’s processing power so they can’t do anything else?
To help with these tests I added the option to run the segmentation at different resolutions. Higher resolutions provide a lot more bits to process, so they are one way to see how efficient the pipeline is running.
I recorded my results in this sheet for reference. The results shared below are just for the WebRTC Insertable Streams methodology, but that link includes playground measurements too.
Visual performance
I didn’t do any exhaustive tests here (yet). That would require a large group of volunteers. Ultimately there isn’t much that can be improved other than tweaking the green screen parameters and doing some more advanced filtering and light wrapping techniques, like what is described here. Beyond that, one would need to build and train an improved segmentation model from scratch. Beating the free one you get with MediaPipe would take a better dataset and some deep ML expertise.
FPS & Processor usage
This one is easier to measure. I added an frames per second (FPS) meter using stats.js from mrdoob and checked the CPU usage in the browser task manager. The results below are just for my MacBook Pro 2018, 2.9 GHz 6-Core Intel Core i9 running Google Canary (currently 97.0.4687.0) using a Logitech Brio 4K Webcam. These numbers jump around a bit, even running the same parameters from test-to-test, so treat them as just one directional indicator. They were generally in the same ballpark from test to test.
FPS
I set my source video to 30 FPS. Could the sender pipeline keep up? How about the receiver side while the sender is active?
Here were my results:
| Test | Resolution | Sender FPS | Receiver FPS |
| Selfview | QVGA | 30 | N/A |
| Selfview | VGA | 30 | N/A |
| Selfview | HD | 30 | N/A |
| Selfview | UHD | 30 | N/A |
| Send and recv | QVGA | 30 | 30 |
| Send and recv | VGA | 30 | 30 |
| Send and recv | HD | 27 | 17 |
| Send and recv | UHD | 7 | 21 |
I had no problem keeping up with the framerate with just the self-view all the way up to 1920×1080 UHD. The receiver side started to struggle at HD (while also showing the self-view in HD). UHD was totally unusable. I checked webrtc-internals and it showed the received framerate was similar to the displayed sender framerate – it seems that the background removal pipeline on the receiver end couldn’t keep up.
CPU Utilization
I added an option to the breakout box example that runs without any segmentation or transparency as a comparison benchmark. Running with just a single tab, I then used the Chrome task manager to record that tab’s CPU, the GPU process, and the video capture process.
CPU usage for just the self-view wasn’t so bad. The additional encoding and decoding processing when using a peer connection increases CPU by quite a bit without any transparency.
| Tab + GPU + Vid Capture | ||||
|---|---|---|---|---|
| View | Resolution | Normal WebRTC | Transparency | Delta |
| Self | QVGA | 15% | 47% | 32% |
| Self | VGA | 13% | 52% | 39% |
| Self | HD | 16% | 63% | 47% |
| Self | UHD | 15% | 89% | 75% |
| Self + Peer | QVGA | 43% | 83% | 40% |
| Self + Peer | VGA | 60% | 123% | 63% |
| Self + Peer | HD | 132% | 176% | 44% |
| Self + Peer | UHD | 231% | 222% | -8% |
VGA seemed to be the practical limit for me. After that it seemed CPU throttling stared to kick in, reducing the framerate to an unacceptable level.
Challenges & To Do
This was just a proof of concept. There are a few things I would like to try and some that would be needed for a production app.
Workers
One big advantage of insertable streams is you can do processing in a worker thread, offloading your main thread. This should speed things up.
WebGL with Insertable Streams
I didn’t get a chance to rewrite the webGL code to work with insertable streams, so that isn’t present in the all-in-one example.
Browser Support: Chromium-only; Firefox possible
Unfortunately, my samples only work in Chromium-based browsers right now. The MediaPipe Selfie Segmentation has some issues with Safari. Both my examples use an OffscreenCanvas and this isn’t supported in Firefox or Safari. I started to try to switch this to an onscreen, hidden canvas for Firefox but that would take some more work. Neither Firefox nor Safari support the MediaStreamTrack API for Insertable Streams of Media, so the transparency.html example won’t work either.
Lastly, MediaPipe Selfie segmentation doesn’t work with Safari, so that would need to be addressed in addition to fixing the problems above for broader browser support.
Segmentation rate
The segmentation in my examples run at 30 frames per second to match the video frame rate. Unless there is a lot of rapid motion, the segmentation mask shouldn’t change every 33 ms (1 frame/30 fps = 33 ms). Unless the user is moving a lot, we could save some processing time by reducing this. However, if you set this too low then the segmentation mask will lag and motion the user makes.
Testing on other machines
I am curious how well this works across different devices, including mobile web. I tried it quickly and it worked, but the frame rates were well below my MacBook. If you try it, please let me know how it works in the comments.
Conclusions
Several companies offer transparent background options, so this is definitely possible. Using segmentation libraries like MediaPipe and canvas manipulations, it actually isn’t too hard. Some further tweaking could definitely improve performance, though the source MediaPipe Selfie model’s segmentation ability will always be hard to improve without significant effort.
Give it a try and let me know how it works for you in the comments below or at the Kranky Geek WebRTC event on November 18th!
{“author”: “chad hart“}




It’s disabled by default [1], but it would be cool to try the ‘multiplex’ codec [2] working to avoid the transform on the receive side. Though I haven’t checked if that will actually pass to webrtc as a I420A or I420.
[1] https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/common/features.cc;l=300-301;drc=cafa646efbb6f668d3ba20ff482c1f729159ae97
[2] https://source.chromium.org/chromium/chromium/src/+/main:third_party/webrtc/media/engine/multiplex_codec_factory.h;l=25-42
Great article, with regards to performance, would, using webassembly help on some of the intensive parts of your code. I have only just started to look into wa, so could not offer a possible opinion here, but many who have, claimed that they are seeing anything from 3 to 9 times faster executions.
The MediaPipe part that does the segmentation tends to be the most processing intensive. MediaPipe already has a WASM back-end option, so I don’t think there is much room for improvement there. The “add green-screen” step could be added to MediaPipe pipeline to remove the 2nd process/generator.
Using WebCodecs to hack in an alpha channel is another idea I would like to try (which would need WASM for performance).
Can you tell me how you send the removed background version through webrtc? I would appreciate if you show me how you addTracks