Thanks to work initiated by Google Project Zero, fuzzing has become a popular topic within WebRTC since late last year. It was clear WebRTC was lacking in this area. However, the community has shown its strength by giving this topic an immense amount of focus and resolving many issues. In a previous post, we showed how to break the Janus Server RTCP parser. The Meetecho team behind Janus did not take that lightly. They got to the bottom of what turned out to be quite a big project. In this post Alessandro Toppi of Meetecho will walk us through how they fixed this problem and built an automated process to help make sure it doesn’t happen again.
If you are just getting started with fuzzing you will find this guide invaluable. Even if fuzzing is something you already do, we suspect you will gain insights by referencing the methodology here.
If you are not familiar, Janus is an open-source, modular, multi-function WebRTC server that can do things such as act as a generic signaling sever, WebRTC Gateway, and/or multi-party video SFU.
{“editors”: [“chad hart“,“Philipp Hancke“]}

I felt scared and fascinated at the same time after reading the terrific blogpost by Natalie Silvanovich of Google Project Zero covering her fuzzing analysis of various real time communications services. Many people out there probably already do some fuzz testing and already have some tools to test their software. I was not one of them. However, I’m feeling lucky for having read Natalie’s post about fuzzing and Philipp’s (Fippo) work about Janus testing on this blog. Guided by the spirit of discovery and the need to secure our WebRTC server, I started my journey in the fuzz testing by approaching it through libFuzzer and applying it to Janus’ RTCP parsers.
My journey is divided into 4 parts:
- A story of Clang – the effort of migrating from gcc to clang: how the toolchain has been adapted and the study of (unexpected) clang compiler outputs
- Building the fuzzing targets up – how to create and build a meaningful and effective RTCP fuzzing target: analyzing the protocol stack, correctly managing the memory, using Macros to exclude some paths from fuzzing, creating a building script
- Running the fuzzer and debugging – how we run our fuzzing targets, investigate the crashes, evaluate code coverage
- Fuzzing as a Service with Google OSS-Fuzz – to make the fuzzing process an automated and continuous task; here I introduce OSS-Fuzz and how it works and how we integrated with it
TL;DR version
I first had the challenges of dealing with a new toolchain (clang) with new warning messages and new options to configure. Clang documentation was really helpful to understand how to manage some flags. This process events led me to the X86_64 ABI – that was just a sort of a chimera for me before this work on the fuzzing.
Then my efforts have been concentrated on making an effective fuzzing target in terms of code coverage, bugs discovery, and performance. This also included preparing a corpus dataset to feed into my fuzzer. In this phase I had to:
- re-discover the data flow of the RTCP packets before arriving to the parsers,
- handle the correct flags to operate with clang instrumentation,
- be very careful with memory management, and finally
- prepare a helper script for building the fuzzers and the standalone fuzzing engine for regression testing.
Once my fuzzer started running, I had to debug and analyze the crashes. The traditional C debugger ended up being the best fit for the task. But also I needed to evaluate the code coverage in order to estimate my fuzzer effectiveness. Some LLVM tools came in help and I discovered how to obtain a visual report of the coverage.
Finally I have understood the meaning of continuous and automated fuzzing and the benefits of applying it in a cloud platform like Google’s OSS-Fuzz. Targeting OSS-Fuzz integration since the beginning, I had to adapt my building script to both local and remote environments and then prepared the files needed to propose a Pull Request on Google’s repository.
The full details follow below.
1 – A story of Clang
LibFuzzer is an open source implementation of a coverage-guided fuzzing engine. This means that the pattern mutations are directly influenced by the source paths explored during the fuzzer execution. LibFuzzer is part of the LLVM project and relies on some LLVM tools to accomplish its task (one example is the code coverage information). LLVM is a collection of tools aimed at compilation and software analysis and optimization.
The main modules are:
- LLVM Core: acts as backend, providing a source and target independent optimizer and code-generator. It uses a LLVM intermediate representation (IR) language.
- Clang: the main compiler for LLVM, designed to deliver fast compilations for C/C++/Objective-C and to output useful error and warning messages.
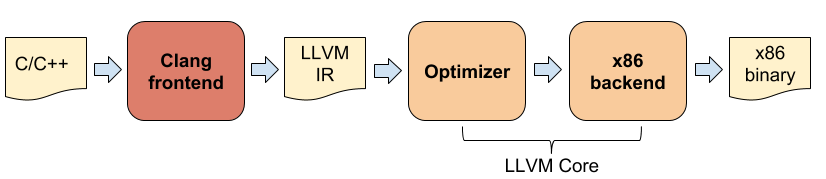
Unfortunately you cannot use gcc compiler on top of a LLVM backend like it was in the early days of LLVM (dragonegg and LLVM-GCC), so the very first step to try libFuzzer in your project is to install the clang compiler. Clang is the native front-end for LLVM and has been implemented to act as a drop-in replacement for gcc, at least for C, C++ and Objective-C. It tries to follow gcc command line argument syntax and semantics as much as possible, which means that in most cases you can switch from gcc to clang by just changing the name of the compiler you’re using.
Compiling Janus with Clang
Now that’s the theory. In practice we tried to compile Janus with clang 6 and the compilation was successful (yay!) but the output was really overwhelmed with warning logs.
The first ones we could spot were:
|
1 2 3 4 |
unknown warning option '-Wunsafe-loop-optimizations'; did you mean '-Wunavailable-declarations'? [-Wunknown-warning-option] unknown warning option '-Wunused-but-set-variable'; did you mean '-Wunused-const-variable'? [-Wunknown-warning-option] unknown warning option '-Wno-override-init'; did you mean '-Wno-override-module'? [-Wunknown-warning-option] clang: warning: argument unused during compilation: '-rdynamic' [-Wunused-command-line-argument] |
It looks like clang tried its best to replace gcc, still it does not handle some options.
After a quick reading of the documentation, we could not find any replacement for -Wunsafe-loop-optimizations and -Wunused-but-set-variable flags, so we simply dropped them from the CFLAGS , while we replaced the option -Wno-override-init with its clang equivalent -Wno-initializer-overrides .
As to -rdynamic warning, clang informed us that the option was not going to be used while compiling. Indeed it is a linker specific flag, so we moved -rdynamic from CFLAGS to LDFLAGS and tried the compilation again:
Clang cares about memory alignment
We were quite surprised to see such a huge number of warnings about memory alignment because nothing like this ever showed in our previous gcc compilations. Nonetheless we were motivated to understand the reason behind this messages.
We noticed that some of those warnings involved standard socket programming (casting from socket struct to others) or common macros (like containerof -like macros), so we decided to ignore this part of the messages because we were not doing anything fancy with those functions, just following common practices.
Still, many warnings remained, coming from castings from byte arrays to Janus structs, like RTP and RTCP headers. Those byte arrays are from the ICE level (libnice) and land in Janus callbacks in form of pointers to char. Janus treats them as raw data, casting to specific structs when needed. We then inspected the stack all the way down, till the buffers of libnice, where we discovered that the data emitted to the receiving callbacks is a plain old automatically allocated 64k bytes array.
What is the actual alignment of this structure? The answer lies in the kernel ABI. By quoting System V x86_64 ABI:
“An array uses the same alignment as its elements, except that a local or global array variable of length at least 16 bytes […] always has alignment of at least 16 bytes”
Therefore that buffer has a 16-bytes alignment, but the compiler does not know this, hence the warning. But we were wondering why gcc does not whine as clang does? Well the answer is that x86 generally permits unaligned memory access (with a possible performance drop to estimate [Fundamental Types] ), so gcc will not annoy the user in this case. This is true at least on x86_64 , whereas talking of ARM… well that’s another story for another time.
We finally understood that those warnings were practically harmless in our environment, but didn’t find any way to suppress them locally without touching the code too much, so we decided to totally suppress the alignment warnings with -Wno-cast-align in CFLAGS . This is not the best move and I would not recommend doing this (think about other architectures where alignment matters), but the warning messages were just too noisy and there was the risk to miss something relevant in the logs. Anyway we promised ourselves to come back to the matter even if we do not plan to replace gcc with clang in the short term.
Discovering the bugs through warning messages
Another ride on the compiler and we got this:
Almost there! Clang was notifying us that some printf format specifiers were not right and the function abs is being misused. Good catch clang, those are definitely bugs!
After having fixed them, the output got clean.
Migrating from GCC to Clang
As a conclusion we found out that switching from gcc to clang may not be a straightforward task. We needed to update our GNU Autotools files to detect the different compilers and fix the flags as needed. Nonetheless clang made us fix some bugs and led us to investigate about the importance of memory aligned pointers. A special mention goes to the outstandingly informative logs emitted by clang, one of the reason this compiler is getting more and more attention today.
2 – Building the fuzzing target up
With our new shiny clang toolchain up and running, we concentrated on the fun part: writing fuzzing targets! Taking inspiration from previous Philipp Hancke’s work on fuzzing Janus, our choice was to keep investigating on RTCP and use this protocol to learn more about libFuzzer and fuzzing in general. Actually we have also fuzzed and fixed our RTP protocol implementation but we’ll use the RTCP to show you the steps we did.
The protocol stack
We started by looking at the target function signature:
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size)
Ok, so we had a first parameter with some data in form of raw bytes and a second parameter with its size. We needed to understand the data flow before the RTCP parsing kicks-in in Janus, in order to mimic the way Janus handles those packets.
A static analysis of the stack led to this synthetic overview:
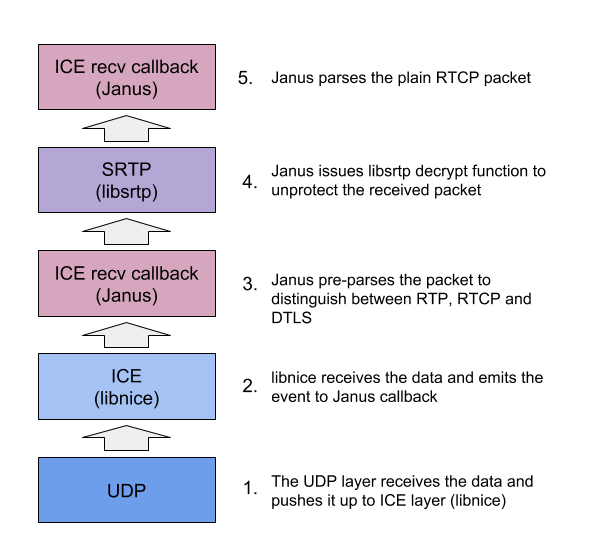
Data constraints analysis
Every level of this chain was introducing some kind of validation and we wanted to simulate the same control logics in the fuzzing target. This was crucial to help concentrating the tests on the right packets and avoid scenarios involving not admissible cases leading to useless iterations and wasted fuzzing cycles.
So assuming that we’re receiving RTCP, which bounds should we consider? From a networking perspective, the maximum size of an UDP packet is 64k, but in practice MTU size has to be considered because it’s common in time-critical applications like RTC to avoid IP fragmentation (indeed WebRTC limits video RTP packet size to 1200). In case of 1500 bytes MTU, after accounting for headers, the max UDP payload size to avoid fragmentation is 1472, so it made sense to set that as the upper bound. This consideration does not imply that our WebRTC server will never receive RTCP packets greater than that size – our idea was just to narrow the testing scope down to common packet sizes and quickly find the bugs in our code. Fuzz testing with jumbo packets is absolutely still recommended!
libnice then proceeds checking for message size greater than zero and emits the message to Janus. The callback preparses the packet, rejecting packets smaller than 8 bytes and with a header type non in the right range [64,95]. Finally libsrtp checks for a minimum length of 8 bytes, that is a full RTCP header.
Implementing the checks in the fuzzing target
Putting all of this together we got the following sanity checks:
|
1 2 3 4 5 6 7 8 9 10 |
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) { /* Sanity Checks */ /* Max UDP payload with MTU=1500 */ if (size > 1472) return 0; /* libnice checks that a packet length is positive */ if (size <= 0) return 0; /* length >= 8 bytes and RTP header type in range [64-95] */ if (!janus_is_rtcp(data, size)) return 0; /* libsrtp checks that a packet contains a full RTCP header */ if (size < 8) return 0; |
We preferred to keep the checks in this order rather then collapse them in a single one. We did this because it reminded us of the layers the packet traverses before arriving to the RTCP parsers. Furthermore these checks might involve a RTCP compound packet, so they will let pass the first valid packet of a row of unchecked packets.
Identifying the target functions
We then moved on identifying the critical RTCP parser functions. Those are the functions that directly handle the memory in a “dangerous way” (e.g. functions using memcpy/memmove, casting bytes to structs or doing pointer arithmetics etc.). There was a bunch of them, so we decided to split the set in three groups:
- Functions that just read data
- Functions that alter input data
- Functions that allocate new memory
For the first group, using the original const uint8_t *data is totally fine. The same is not true for the second group, that expects an input/output parameter, so we can not just feed those functions with the same data coming from the fuzzing engine, because the fuzzer will crash at the first attempt to modify its content. Indeed the const qualifier for fuzzer data is not casual. The input data must not be modified during the execution because otherwise the output of the iteration might be dependent on the order of the tested functions and the dumped crashing pattern will be different from the initial data. To overcome this enforcement and be sure to test also the functions of the second group, we simply made a number of copies of the original pattern, one for each function to test. Also a dummy RTCP context was necessary to some methods, so we added some memory allocations to our fuzzing target:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* Do some copies of input data */ uint8_t copy_data0[size], copy_data1[size], copy_data2[size], copy_data3[size], copy_data4[size]; uint8_t *copy_data[5] = { copy_data0, copy_data1, copy_data2, copy_data3, copy_data4}; int idx, newlen; for (idx=0; idx < 5; idx++) { memcpy(copy_data[idx], data, size); } idx = 0; /* Create some void RTCP contexts */ janus_rtcp_context ctx0; memset(&ctx0, 0, sizeof(janus_rtcp_context)); |
The functions of the third group returned pointers to new allocated memory, so all we had to do was to be sure to free the allocated memory before the test iteration ended.
|
1 2 3 4 5 |
/* Free resources */ /* Pointers returned by tested functions */ g_free(output_data); if (list) g_slist_free(list); return 0; |
The final result is a 66-line rtcp_fuzzer.c target.
Fuzzing target optimization and implementation tips
We tried to optimize the fuzzing target as much as possible.
Some rules of thumb to follow are:
- Try to use static initialization and shared resources
- Avoid dynamic allocations when possible (prefer stack memory)
- Avoid message logging (disable logging in your target API)
Another thing to remember is that you need your target to be deterministic. In practice this means that every call to RAND -like functions must be suppressed or at least called with always the same seed. Also suppression of some code may be needed to optimize out hashing functions, checksum functions or crypto methods. We managed to cut out some paths by using the compilation directive FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION . Doing this we skipped some methods for which fuzz testing was unwanted, avoiding linking with unwanted dependencies (like JSON parsing libraries or crypto libraries).
|
1 2 3 |
#ifndef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION // code you want to skip during fuzzing #endif |
Finally remember that your fuzzing can (and it’s better if it will) run in parallel jobs, so try to manage shared resources (if any) in a proper way.
Building the targeted library objects
Once we wrote a fuzzing target following the mentioned guidelines, time was come to build the sources. First we had to build the Janus objects needed by the fuzzing target.
|
1 2 3 4 |
./configure CC=clang CFLAGS="$FUZZ_CFLAGS" /*--disable-unwanted-features*/ JANUS_OBJECTS="janus-log.o janus-utils.o janus-rtcp.o" make -j$(nproc) $JANUS_OBJECTS ar rcs janus-lib.a $JANUS_OBJECTS |
For RTCP testing the only Janus objects needed were (surprisingly) the rtcp module with the help of the utils and the log modules. So we configured Janus to be compiled with clang and with the fuzzing CFLAGS (more on this in a while), then we built the needed objects in the usual way, finally we archived all of the objects in a static library just to simplify the next steps and obtain a single object with all the Janus capabilities we had to test.
About the fuzzing CFLAGS , they have been set to
FUZZ_CFLAGS="-O1 -fno-omit-frame-pointer -g -ggdb3 -fsanitize=fuzzer,address,undefined -fsanitize-address-use-after-scope -fno-sanitize-recover=undefined -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION"
The table below describes these:
| Flag(s) | Meaning |
| -O1 -fno-omit-frame-pointer -g -ggdb3 | useful for debugging and stacktraces. |
| -fsanitize=fuzzer,address,undefined | enable fuzzer, ASan and UBSan to monitor fuzzer execution. |
| -fsanitize-address-use-after-scope | trigger ASan when using a variable after its scope. |
| -fno-sanitize-recover=undefined | make fail the fuzzer to the first undefined behavior sanitizer message. |
| -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION | Define the variable needed to skip/alter some source paths. |
In general it is not mandatory to compile your target library with clang or specific CFLAGS , but it is highly recommended to insert at least:
- ASan for runtime issues detection
- Debugging flags for stack traces analysis.
To enable code coverage detection in your target library during fuzz testing you’ll need to add the -fsanitize=fuzzer flag and that is specific to clang, so very likely you’ll end up compiling your target library with clang too.
Building the fuzzing target
This finally provided us with a ready-to-fuzz, debug-friendly, janus-lib and now we had to compile the fuzzing target itself:
|
1 |
clang $FUZZ_CFLAGS $(pkg-config --cflags glib-2.0) rtcp_fuzzer.c -o rtcp_fuzzer janus-lib.a $(pkg-config --libs glib-2.0) |
The actual compilation command is a bit more complicated, but this one summarizes well the relations between the objects and the variables. The fuzzing target needs to be built with clang, using the fuzzing CFLAGS and the dependencies (glib) CFLAGS , linking the library under test (janus-lib.a) and the dependencies libraries (glib again).
In production we build the fuzzer by splitting compilation and linking phases, statically linking in dependencies libraries and optionally linking in libFuzzer main symbol (so we have the opportunity to define another library where the main symbol has been provided).
The build.sh script
The final output of our effort was a build.sh script to quickly prepare all fuzzing targets and corpora folders. This script works in the following steps
- read some environment variables to set compiler, compilation flags, linking flags and fuzzing engine to use. Fall back to clang fuzzing with libFuzzer.
- build targeted Janus objects.
- build standalone fuzzing engines. These are the sourcefiles under the engines folder. Their job is to define a main symbol, fetch data from command line and then invoke the callback LLVMFuzzerTestOneInput (defined in your fuzzing target). In this way you are able to test the corpora files against your fuzzing target BUT w/o fuzzing and w/o clang.
- build every fuzzing target.
- archive the corpora files in zip files.
And all of this magic just in a single command:
|
1 2 |
# User defined SRC, OUT, WORK, CC, CFLAGS, LDFLAGS, LIB_FUZZING_ENGINE ./build.sh |
Coverage reporting instrumentation
Given that we were also interested in knowing the coverage of our current corpus, we needed to investigate on how to instrument the build chain to accomplish the task. Following clang directives all we had to do was to change the CFLAGS like this
|
1 |
FUZZ_CFLAGS="-O1 -fno-omit-frame-pointer -g -ggdb3 -fsanitize=fuzzer -fprofile-instr-generate -fcoverage-mapping -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION" |
and compile the janus-lib and the fuzzing target. This gave us an artifact ready to be analyzed with LLVM coverage tools (more on this in the next sections).
Corpora files
We reused the webrtc.org corpora files for RTCP but we decided to create our own corpus too. Our RTCP corpus is made up of:
- plain RTCP packets coming from real world WebRTC sessions
- crash files discovered while fuzzing
We named the binary files of the RTCP corpus after their content, in order to easily reveal the packets of the dataset.
3 – Running the fuzzer and debugging the code
We crafted a helper script (run.sh) to run our fuzzing targets. Its role is to extract the corpora files from the zip archives and then run the fuzzer like the following
|
1 2 3 4 5 |
# run.sh # if [ -f "rtcp_fuzzer_seed_corpus.zip" ]; then unzip -oq rtcp_fuzzer_seed_corpus.zip -d rtcp_fuzzer_seed_corpus fi ./rtcp_fuzzer -artifact_prefix="./rtcp_fuzzer-" -jobs=4 rtcp_fuzzer_corpus rtcp_fuzzer_seed_corpus |
There are many things to notice here:
- No max_len has been specified at command line. We preferred limiting the input size in the fuzzing target in order to keep all the fuzzing logics in the code.
- We have defined a prefix for the dumped crash files to help distinguish between different fuzzer files.
- We run the target in parallel jobs.
- We specified two corpus folders. When using more than one folder, the first one will be used to write all coverage increasing inputs, while the other folders will just be part of the corpus. If you are interested in minimizing a large corpus splitted in different folders look at the merge flag in libFuzzer. The rtcp_fuzzer_seed_corpus is the folder containing the files of the corpus zip archive.
Debugging the crashes
In the (happy?) case of fuzzing target crashing, we can try to convert a crash file in a pcap file, in order to inspect the offending packets with Wireshark
|
1 2 |
od -Ax -tx1 -v crash-file > crash.hex text2pcap -u1000,2000 crash.hex crash.pcap |
It looks cool, but sometimes Wireshark does not seem to like unexpected packets (like a fuzzed RTCP packet), because it stops the parsing at the first error encountered.
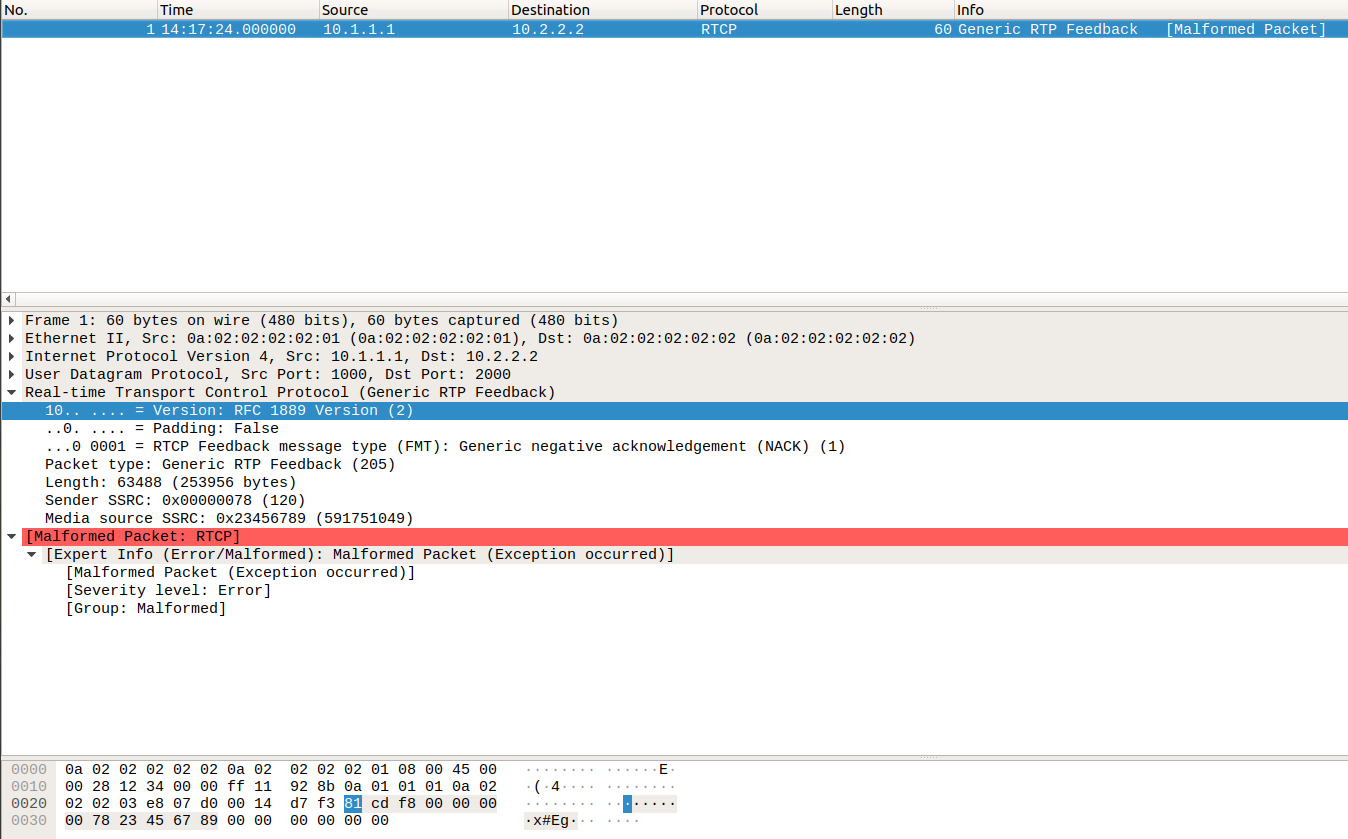
So the hexdump of the crash file, followed by parsing by hand, seems like the only option to inspect the content of a packet. Unfortunately in many cases we found it very difficult to identify a bug by just staring at our code and at the binary dump of the packet. In this cases the best tool to adopt is the old faithful C debugger gdb. You can reproduce a crash of the fuzzer within gdb like the following
|
1 |
ASAN_OPTIONS=abort_on_error=1 gdb --args ./rtcp_fuzzer crash-file |
Then start the program and wait for a failure detected by the sanitizer ( ASan in this example). Notice the ASAN_OPTIONS =abort_on_error=1 option, that is necessary to keep the threads stack traces when a failure occurs in ASan . Should the failure occur in UBSan , just set UBSAN_OPTIONS in the same way. Then proceed like usual, by selecting stack frames, reading variables, examining pointers, evaluating expressions and all the good stuff gdb might offer. Keep in mind that in order to have an effective debugging experience, your target library must have been compiled with the flags:
- -O1 (if your compiler is optimizing out some variables try -O0)
- -ggdb3 (or -g )
- -fno-omit-frame-pointer
Coverage testing
While fuzzing your software you might be interested to the code coverage reached by your tests. After some hours of fuzzing, the corpus folder will hopefully be filled with dozens (or hundreds) of binary files that discovered new source paths in your target library. You may want to test the coverage of these new patterns or you may want to know the coverage of your initial corpus to evaluate its effectiveness. In any case you’ll need, as usual, clang and you have to instrument it with the code coverage CFLAGS we described in the fuzzer building section. Then start the fuzzer:
|
1 |
LLVM_PROFILE_FILE=rtcp_fuzzer.profraw ./rtcp_fuzzer rtcp_fuzzer_seed_corpus/* |
When the program exits it will write a raw profile to the path specified by the LLVM_PROFILE_FILE environment variable. If that variable does not exist, the profile is written to default.profraw in the current directory of the program. The next step is to generate a coverage report. You can get this with some LLVM tools:
|
1 2 |
llvm-profdata merge -sparse rtcp_fuzzer.profraw -o rtcp_fuzzer.profdata llvm-cov show rtcp_fuzzer -instr-profile=rtcp_fuzzer.profdata rtcp.c -use-color -format=html > /tmp/rtcp_fuzzer_coverage.html |
The output will be a report in a HTML file that will show the code coverage in an eye-catching way.
Bonus track: the standalone fuzzing driver
We mentioned in the previous section the implementation of a standalone fuzzing engine. By setting the variable LIB_FUZZING_ENGINE and running build.sh , the script will not link against libFuzzer. In this way you can use your own object file (assuming it has a main symbol) that might have a custom behavior and must invoke the fuzzing callback LLVMFuzzerTestOneInput defined in the fuzzing targets.
Our standalone engine is a very simple driver that reads the files from argv and calls LLVMFuzzerTestOneInput for every file. Therefore you will not need libFuzzer nor clang to compile a fuzzing target with a standalone engine. You can build with gcc in this way:
|
1 |
CC=gcc LIB_FUZZING_ENGINE=standalone.o ./build.sh |
and the final artifact can be launched specifying all of the files:
|
1 |
./rtcp_fuzzer rtcp_fuzzer_seed_corpus/* |
This might be useful for a quick regression or validation testing of your library without fuzzing and without installing clang.
4 – Fuzzing as a service
Fuzz testing effectiveness is highly related to many parameters. By working with libFuzzer your first concern is to optimize your fuzzing target and your corpus dataset, making it discover a large number of source paths in a short time. But fuzz testing is not just covering code lines. What matters above all is testing your critical functions with unexpected inputs. So your fuzzers and your corpora might be the best, but still the fuzzing engine would need time before triggering a bug, and time translates to resources and costs.
In addition to this, fuzzing is not a one time task. Your project will evolve, and so will do the tools involved in bug discovery, therefore this is a regular process that should be integrated in a continuous execution environment.
In other words:
the longer you leave your fuzz testing executing, the bigger are the chances to find bugs, but this will have a cost in terms of hardware and software integration.
Fuzzing in the cloud with Google OSS-Fuzz
Google’s OSS-Fuzz tries to address these issues and others that project maintainers have to face when their fuzzers need to be continuously executed and ready to scale. The OSS-Fuzz service, hosted on Google Cloud Platform, has been dedicated to the fuzzing of critical and/or widespread Open Source Software with the obvious mission to make the Internet a safer world and let developers know how important is fuzz testing today.
You can read the entire list of admitted projects here, but to give you an idea of the their importance you can find names like ffmpeg, gstreamer, OpenSSL, Firefox, LLVM and many many others.
What OSS-Fuzz does offer is an automated and continuous fuzzing framework for your project, through the help of:
- Ready-to-scale, distributed architecture
- Thousands of CPUs
- Multiple fuzzing engines and sanitizers
Google’s platform has already collected many awards: since the launch in 2016, OSS-Fuzz has discovered and reported more than 10,000 bugs. The notification process is quite straightforward: whenever a fuzzer detects a bug, the project maintainer is informed and can investigate the problem on the OSS-Fuzz issue tracker. Furthermore, if one is using a Google Account, the maintainer has given the opportunity to read any time some fuzzing statistics on a dashboard (like code coverage, performance analysis etc.). Many of these features are due to ClusterFuzz, the infrastructure behind OSS-Fuzz, that was originally built for fuzzing Google Chrome and has recently been open sourced.
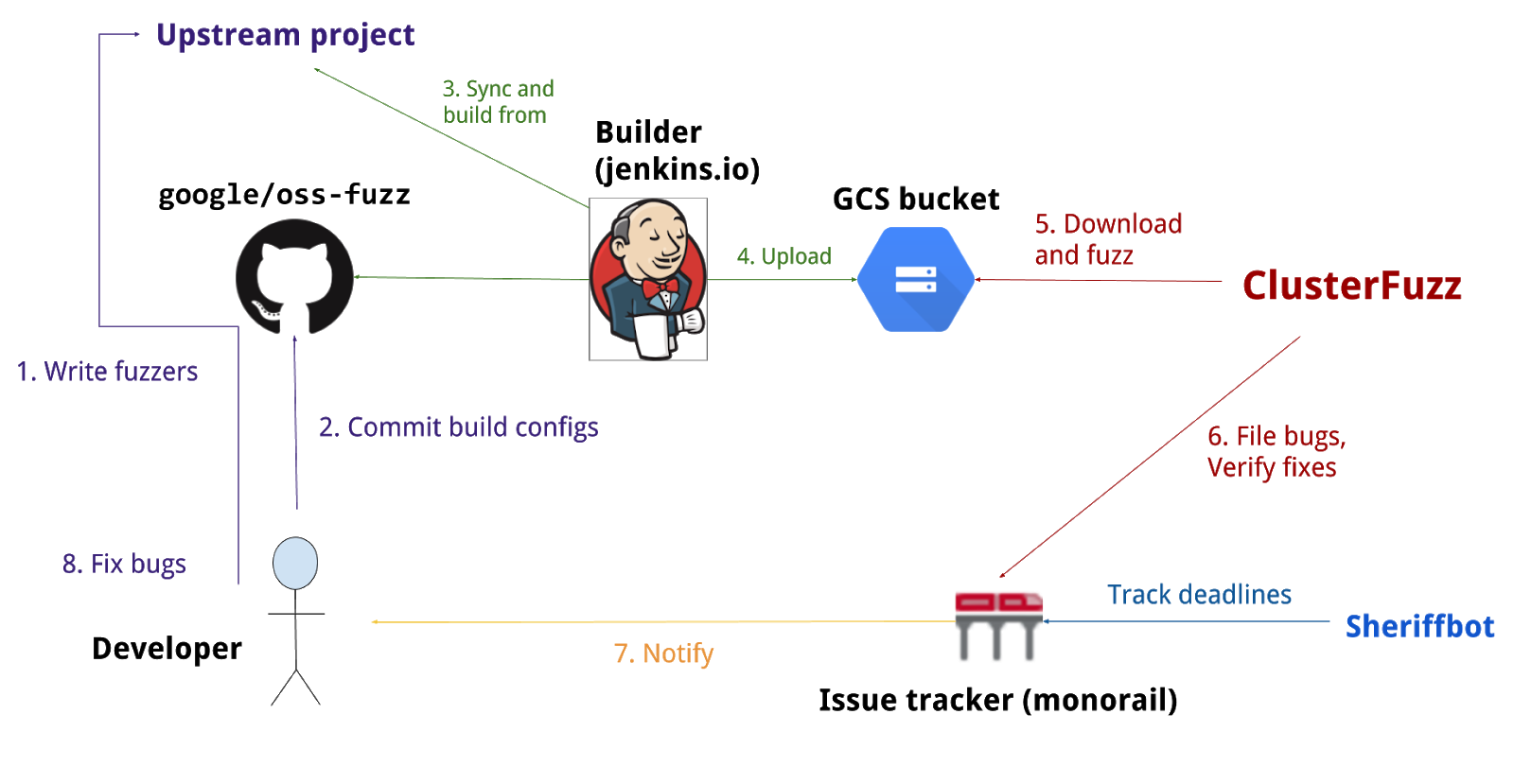
Oh, and I almost forgot to mention the best part: OSS-Fuzz services are totally free! But hold on… you’ll first need to be admitted to the club and this means submitting a PR on their repo with everything put in place.
Enter the OSS-Fuzz
When we started to gather information about fuzzing for Janus, we soon stumbled upon OSS-Fuzz and we immediately decided that aiming at integration with the Google’s platform was the right thing to do. If the excellent platform capabilities we have already described were not enough, Google also offers a Reward Program to compensate developers for the integration efforts. The exact amount is related to the quality of your work, though, ranging from $1K to $20K.
Now, let’s say you have implemented your fuzzing targets. How do you become part of OSS-Fuzz?
The first step to integrate your project is to fork their repository and install Docker on your machine. Google decided to adopt Docker to simplify toolchain distribution and provide a reproducible and secure environment for fuzzer building and execution.
Then add your project under the oss-fuzz/projects folder and create three files:
- project.yaml : a file containing project description, contact info and some extra configurations for the sanitizers.
- Dockerfile : a file defining the container environment with information on dependencies needed to build the target project and its fuzz targets.
- build.sh : a script file that will be executed in the Docker container and will build your project and your fuzzing targets.
Google did an amazing job with the OSS-Fuzz documentation for new projects. You will be guided in the integration step after step, thanks also to some very useful python scripts to locally build, check and run the containerized fuzz testers.
Integrating Janus in the framework
Indeed it was not difficult to create a project.yaml and a Dockerfile for Janus but while these two may be straightforward, the build.sh script needs some more attention. In fact this script is executed in an environment with well defined variables that MUST be taken in account while building your fuzzers. Some of these variables specify the paths for source ( $SRC ), output ( $OUT ) and working paths ( $WORK ), while some others define the compiler ( $CC ), the linker ( $CXX ) and the respective flags ( $CFLAGS and $CXXFLAGS ). Moreover you MUST NOT consider that the fuzzing engine will always be libFuzzer. OSS-Fuzz generates builds for both libFuzzer and AFL, so the fuzzing engine must be linked through the environment variable $LIB_FUZZING_ENGINE .
Another thing to notice is that packages that are installed via Dockerfile or built as part of build.sh are not available on the runtime environment, so you’ll need to statically link any runtime dependency in the fuzzing target.
As of the corpus files, this is something to address in the build.sh script too. You’ll need to place a zip file containing all the dataset in the same folder as the fuzzer binary. Don’t worry about the unzipping, the runtime will do this automatically given that the zip file name somehow matches the fuzzer binary name.
Finally, should you experience some issues while building or running your fuzzers, Google gives you also the helpers for opening a shell in the container or execute a fuzzer within gdb.
A second look at Janus fuzzers build.sh
Considered all of this, you should be ready to have a look at our build.sh for OSS-Fuzz.
Wait… one line? It is not an error, that line just calls the build.sh in our Janus repository, exactly the same one we use when locally building our fuzzers. That is possible because we had OSS-Fuzz in mind since the beginning, so our script automatically sets the fuzzing flags according to the environment (local or OSS-Fuzz), builds the target binaries statically linking in all the dependencies and prepare the zip files with the corpus files (and we use the zip files in local testing too, emulating OSS-Fuzz runtime).
Waiting for the Pull Request
If everything works locally, you should be ready for submitting a PR on OSS-Fuzz repository.
Our integration is working and has been tested for RTCP and RTP fuzzing with all of the sanitizers available on OSS-Fuzz (address, undefined behavior and memory).
We’ll probably submit our PR to Google once the fuzzing code will be merged in Janus mainline and then we’ll just wait for their approval (or denial…).
Conclusions and personal thoughts
Fuzz testing should be taken more in consideration by WebRTC server developers. Even if you don’t follow all the best practices, setting up a simple fuzzing target for libFuzzer and discovering the first problems can be done in a matter of minutes.
But IMHO, bug discovery is not the only benefit of the process. As you write an effective fuzzing target you will be forced to consider your program’s data flow in your program and you will see ways to improve it.
When you fuzz your WebRTC code you not only fix your own implementation; you also make WebRTC a safer world. Please share the patterns that made your fuzzer fail like we are doing here. This will give others the opportunity to test their code and fix their implementation too.
{“author”: “Alessandro Toppi“}




Leave a Reply