
Chrome recently added the option of adding redundancy to audio streams using the RED format as defined in RFC 2198, and Fippo wrote about the process and implementation in a previous article. You should catch-up on that post, but to summarize quickly RED works by adding redundant payloads with different timestamps in the same packet. […]
Search Results for: SFU
Improving Scale and Media Quality with Cascading SFUs (Boris Grozev)
Deploying media servers for WebRTC has two major challenges, scaling beyond a single server as well as optimizing the media latency for all users in the conference. While simple sharding approaches like “send all users in conference X to server Y” are easy to scale horizontally, they are far from optimal in terms of the […]
Breaking Point: WebRTC SFU Load Testing (Alex Gouaillard)
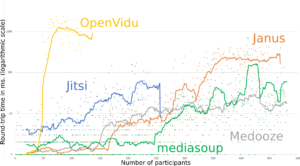
If you plan to have multiple participants in your WebRTC calls then you will probably end up using a Selective Forwarding Unit (SFU). Capacity planning for SFU’s can be difficult – there are estimates to be made for where they should be placed, how much bandwidth they will consume, and what kind of servers you […]
A playground for Simulcast without an SFU

Simulcast is one of the more interesting aspects of WebRTC for multiparty conferencing. In a nutshell, it means sending three different resolution (spatial scalability) and different frame rates (temporal scalability) at the same time. Oscar Divorra’s post contains the full details. Usually, one needs a SFU to take advantage of simulcast. But there is a […]
Can an Open Source SFU Survive Acquisition? Q&A with Jitsi & Atlassian HipChat
Atlassian’s HipChat acquired BlueJimp, the company behind the Jitsi open source project. Other than for positive motivation, why should WebRTC developers care? Well, Jitsi had its Jitsi Video Bridge (JVB) which was one of the few open source Selective Forwarding Units (SFU) projects out there. Jitsi’s founder and past webrtcHacks guest author, Emil Ivov, was a […]